Es ist immer eine gute Idee, Daten von Algorithmen zu trennen, um mehr Abstraktion zu schaffen. Dadurch erhält man viele Vorteile, die wir nach ein kurzes, praktisches Beispiel aus dem Alltag sehen werden.
Zuerst schauen wir uns mal, exemplarisch, eine Methode zum Initialisieren einer Datentabelle, namens „settings“ an:
public void InitSettingsValues()
{
_DataSet.Tables["settings"].Rows[0]["column0"] = false;
_DataSet.Tables["settings"].Rows[0]["column1"] = true;
_DataSet.Tables["settings"].Rows[0]["column2"] = null;
_DataSet.Tables["settings"].Rows[0]["column3"] = 47.11;
_DataSet.Tables["settings"].Rows[0]["column4"] = "Hello World!";
_DataSet.Tables["settings"].Rows[0]["column5"] = new DateTime(2001, 9, 11);
_DataSet.Tables["settings"].Rows[0]["column6"] = 6;
_DataSet.Tables["settings"].Rows[0]["column7"] = 7;
_DataSet.Tables["settings"].Rows[0]["column8"] = 8;
_DataSet.Tables["settings"].Rows[0]["column9"] = 9;
_DataSet.Tables["settings"].Rows[0]["column10"] = 10;
//... usw.
_DataSet.Tables["settings"].Rows[0]["column99"] = 99;
_DataSet.Tables["settings"].Rows[0]["column100"] = 100;
}
Dieser Code ist alles andere als optimal:
- Ist weder leicht lesbar, noch überschaubar
- Enthält viele Wiederholungen (DRY: Don’t Repeat Yourself)
- Ist nicht abstrakt, sondern explizit („settings“ und 0 als Zeilennummer)
- Man kann es nicht wiederverwenden (für die Tabelle „nichtSettings“ muss eigene Methode geschrieben werden)
- Man kann es nicht leicht pflegen, erweitern, oder mehrere Varianten davon, nebeneinander erstellen/verwenden/aufrufen (siehe den besseren Code unten):
- Was tun wir, wenn bei nächstem Release, per Konfiguration, entweder die eine oder andere Methode aufgerufen werden soll? (z.B. für spezielle Kunden, oder Rollback der Version aufgrund gravierende Sicherheitsmangel udg.)
- Was tun wir, wenn es N (N >= 2) Daten-Varianten gibt (der eine hat X Spalten mehr/weniger)?
- Man kann nicht wirklich von „Algorithmus“ sprechen
- Der Code für CPU und RAM wird unnötig aufgeblasen, und lässt sich schlecht optimieren (siehe IL und Assembler Listings für Intel x64 zum Vergleichen am Ende des Beitrags)
Und nun trennen wir die Daten von Algorithmus:
// Daten.
private (string ColumnName, object Value)[] _SettingsInitValues = { ("column0", false), ("column1", true), ("column2", null), ("column3", 47.11), ("column4", "Hello World!"), ("column5", new DateTime(2001, 9, 11)), ("column6", 6), ("column7", 7), ("column8", 8), ("column9", 9), ("column10", 10),
//... usw.
("column99", 99), ("column100", 100)
};
// Algorithmus.
public void SetTableValues(DataSet pDataSet, string pTableName, int pRowIndex, IEnumerable<(string ColumnName, object Value)> pColumnNameValueTuples)
{
foreach (var tuple in pColumnNameValueTuples)
{
pDataSet.Tables[pTableName].Rows[pRowIndex][tuple.ColumnName] = tuple.Value;
}
}
Die Methode besteht nun aus die Signatur plus 2 Zeilen, und bietet folgende Qualitätsmerkmale:
- Leichter lesbar: 2 Zeilen
-
Überschaubar: 2 Zeilen
-
Verständlicher/Selbsterklärend: 2 Zeilen
-
Abstrakter: kann auch für andere Tabellen des „_DataSet“ oder sogar andere DataSets verwendet werden
- Leichter zu pflegen
- Leichter zu Debuggen
- Leichter zu erweitern
- Grundsätzlich: leichter zu ändern
- Man kann weitere Daten-Varianten nebeneinander einsetzen
Mit diesem Code, brauchen wir uns keine Sorgen machen, denn:
- Es ist wiederverwendbar (für andere DataSets, Tabellen, Zeilen-Index)
- Falls es für Kunde X oder Version Y andere Daten-Varianten genommen werden müssen: kein Problem
- Falls es gleichzeitig unterschiedliche Daten-Varianten für unterschiedliche SW-Versionen genommen werden müssen: kein Problem!
- Das Gleiche für die Nutzung unterschiedliche Daten-Varianten per Konfiguration: kein Problem!
- Sollte aus welchem Grund auch immer, ein Rollback der SW-Version unternommen werden muss: kein Problem!
- Sollte Microsoft in der nächste .NET Framework, Core, NET 9 usw. irgendwas an DataSet, deren Tabelle, Zeile oder Spalten ändern: kein Problem! Wir müssen nur eine einzige Zeile ändern
Wie man hier sieht, kann man für 10 verschiedene Versionen/Kunden, die Settings-Tabelle per Konfiguration mit 10 unterschiedliche Daten-Werte initialisieren, OHNE unsere 2 Zeilen Code ändern zu müssen:
private (string ColumnName, object Value)[] _Vers_1_0 = ("column0", 0), ("column1", "dw4mrkzy") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_1 = ("column0", 2), ("column1", "LR0_uClc") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_2 = ("column0", 0), ("column1", "SR1Vj5ts") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_3 = ("column0", 2), ("column1", "hiKlLG55") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_4 = ("column0", 8), ("column1", "s2Z4MkKZ") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_5 = ("column0", 0), ("column1", "qXZM0x4h") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_6 = ("column0", 0), ("column1", "UQryY_SV") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_7 = ("column0", 0), ("column1", "CB80QEcy") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_8 = ("column0", 8), ("column1", "S59sdhFc") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_9 = ("column0", 7), ("column1", "FSgCWXii") /*... usw. */};
private (string ColumnName, object Value)[] _Vers_1_10 = ("column0", 3), ("column1", "hdNvQ8Wt") /*... usw. */};
Die Unterschiede in IL:
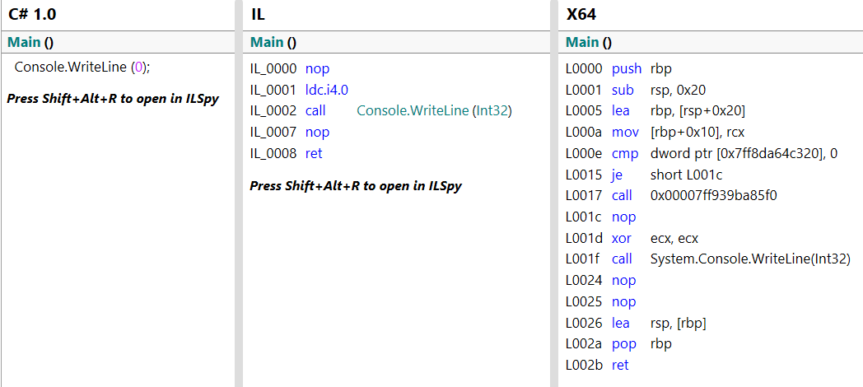
Zuerst der IL Code von „SetTableValues(…)“ (optimaler Code):
Die letzte Zeilennummer (in Hex) ist 0x0057 = 87 dez.
IL_0000 nop
IL_0001 nop
IL_0002 ldarg.3
IL_0003 callvirt IEnumerable <ValueTuple<String,Object>>.GetEnumerator ()
IL_0008 stloc.0
IL_0009 br.s IL_0042
IL_000B ldloc.0
IL_000C callvirt IEnumerator <ValueTuple<String,Object>>.get_Current ()
IL_0011 stloc.1 // tuple
IL_0012 nop
IL_0013 ldarg.0
IL_0014 ldfld UserQuery._DataSet
IL_0019 callvirt DataSet.get_Tables ()
IL_001E ldarg.1
IL_001F callvirt DataTableCollection.get_Item (String)
IL_0024 callvirt DataTable.get_Rows ()
IL_0029 ldarg.2
IL_002A callvirt DataRowCollection.get_Item (Int32)
IL_002F ldloc.1 // tuple
IL_0030 ldfld ValueTuple <String, Object>.Item1
IL_0035 ldloc.1 // tuple
IL_0036 ldfld ValueTuple <String, Object>.Item2
IL_003B callvirt DataRow.set_Item (String, Object)
IL_0040 nop
IL_0041 nop
IL_0042 ldloc.0
IL_0043 callvirt IEnumerator.MoveNext ()
IL_0048 brtrue.s IL_000B
IL_004A leave.s IL_0057
IL_004C ldloc.0
IL_004D brfalse.s IL_0056
IL_004F ldloc.0
IL_0050 callvirt IDisposable.Dispose ()
IL_0055 nop
IL_0056 endfinally
IL_0057 ret
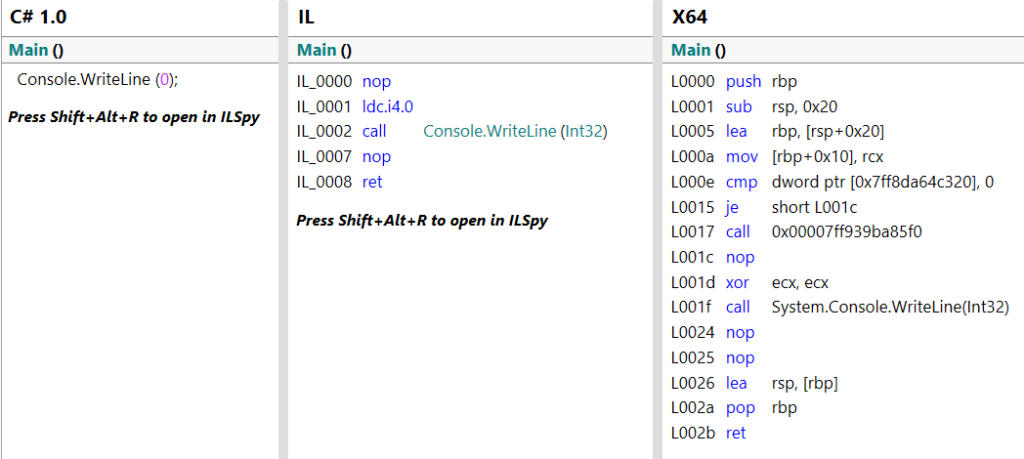
Der IL Code von „InitSettingsValues()“ (nicht optimaler Code):
Die letzte Zeilennummer (in Hex) lautet: 0x0291 = 657 dez.
IL_0000 nop
IL_0001 ldarg.0
IL_0002 ldfld UserQuery._DataSet
IL_0007 callvirt DataSet.get_Tables ()
IL_000C ldstr "settings"
IL_0011 callvirt DataTableCollection.get_Item (String)
IL_0016 callvirt DataTable.get_Rows ()
IL_001B ldc.i4.0
IL_001C callvirt DataRowCollection.get_Item (Int32)
IL_0021 ldstr "column0"
IL_0026 ldc.i4.0
IL_0027 box Boolean
IL_002C callvirt DataRow.set_Item (String, Object)
IL_0031 nop
IL_0032 ldarg.0
IL_0033 ldfld UserQuery._DataSet
IL_0038 callvirt DataSet.get_Tables ()
IL_003D ldstr "settings"
IL_0042 callvirt DataTableCollection.get_Item (String)
IL_0047 callvirt DataTable.get_Rows ()
IL_004C ldc.i4.0
IL_004D callvirt DataRowCollection.get_Item (Int32)
IL_0052 ldstr "column1"
IL_0057 ldc.i4.1
IL_0058 box Boolean
IL_005D callvirt DataRow.set_Item (String, Object)
IL_0062 nop
IL_0063 ldarg.0
IL_0064 ldfld UserQuery._DataSet
IL_0069 callvirt DataSet.get_Tables ()
IL_006E ldstr "settings"
IL_0073 callvirt DataTableCollection.get_Item (String)
IL_0078 callvirt DataTable.get_Rows ()
IL_007D ldc.i4.0
IL_007E callvirt DataRowCollection.get_Item (Int32)
IL_0083 ldstr "column2"
IL_0088 ldnull
IL_0089 callvirt DataRow.set_Item (String, Object)
IL_008E nop
IL_008F ldarg.0
IL_0090 ldfld UserQuery._DataSet
IL_0095 callvirt DataSet.get_Tables ()
IL_009A ldstr "settings"
IL_009F callvirt DataTableCollection.get_Item (String)
IL_00A4 callvirt DataTable.get_Rows ()
IL_00A9 ldc.i4.0
IL_00AA callvirt DataRowCollection.get_Item (Int32)
IL_00AF ldstr "column3"
IL_00B4 ldc.r8 AE 47 E1 7A 14 8E 47 40 // 47,11
IL_00BD box Double
IL_00C2 callvirt DataRow.set_Item (String, Object)
IL_00C7 nop
IL_00C8 ldarg.0
IL_00C9 ldfld UserQuery._DataSet
IL_00CE callvirt DataSet.get_Tables ()
IL_00D3 ldstr "settings"
IL_00D8 callvirt DataTableCollection.get_Item (String)
IL_00DD callvirt DataTable.get_Rows ()
IL_00E2 ldc.i4.0
IL_00E3 callvirt DataRowCollection.get_Item (Int32)
IL_00E8 ldstr "column4"
IL_00ED ldstr "Hello World!"
IL_00F2 callvirt DataRow.set_Item (String, Object)
IL_00F7 nop
IL_00F8 ldarg.0
IL_00F9 ldfld UserQuery._DataSet
IL_00FE callvirt DataSet.get_Tables ()
IL_0103 ldstr "settings"
IL_0108 callvirt DataTableCollection.get_Item (String)
IL_010D callvirt DataTable.get_Rows ()
IL_0112 ldc.i4.0
IL_0113 callvirt DataRowCollection.get_Item (Int32)
IL_0118 ldstr "column5"
IL_011D ldc.i4 D1 07 00 00 // 2001
IL_0122 ldc.i4.s 09 // 9
IL_0124 ldc.i4.s 0B // 11
IL_0126 newobj DateTime..ctor
IL_012B box DateTime
IL_0130 callvirt DataRow.set_Item (String, Object)
IL_0135 nop
IL_0136 ldarg.0
IL_0137 ldfld UserQuery._DataSet
IL_013C callvirt DataSet.get_Tables ()
IL_0141 ldstr "settings"
IL_0146 callvirt DataTableCollection.get_Item (String)
IL_014B callvirt DataTable.get_Rows ()
IL_0150 ldc.i4.0
IL_0151 callvirt DataRowCollection.get_Item (Int32)
IL_0156 ldstr "column6"
IL_015B ldc.i4.6
IL_015C box Int32
IL_0161 callvirt DataRow.set_Item (String, Object)
IL_0166 nop
IL_0167 ldarg.0
IL_0168 ldfld UserQuery._DataSet
IL_016D callvirt DataSet.get_Tables ()
IL_0172 ldstr "settings"
IL_0177 callvirt DataTableCollection.get_Item (String)
IL_017C callvirt DataTable.get_Rows ()
IL_0181 ldc.i4.0
IL_0182 callvirt DataRowCollection.get_Item (Int32)
IL_0187 ldstr "column7"
IL_018C ldc.i4.7
IL_018D box Int32
IL_0192 callvirt DataRow.set_Item (String, Object)
IL_0197 nop
IL_0198 ldarg.0
IL_0199 ldfld UserQuery._DataSet
IL_019E callvirt DataSet.get_Tables ()
IL_01A3 ldstr "settings"
IL_01A8 callvirt DataTableCollection.get_Item (String)
IL_01AD callvirt DataTable.get_Rows ()
IL_01B2 ldc.i4.0
IL_01B3 callvirt DataRowCollection.get_Item (Int32)
IL_01B8 ldstr "column8"
IL_01BD ldc.i4.8
IL_01BE box Int32
IL_01C3 callvirt DataRow.set_Item (String, Object)
IL_01C8 nop
IL_01C9 ldarg.0
IL_01CA ldfld UserQuery._DataSet
IL_01CF callvirt DataSet.get_Tables ()
IL_01D4 ldstr "settings"
IL_01D9 callvirt DataTableCollection.get_Item (String)
IL_01DE callvirt DataTable.get_Rows ()
IL_01E3 ldc.i4.0
IL_01E4 callvirt DataRowCollection.get_Item (Int32)
IL_01E9 ldstr "column9"
IL_01EE ldc.i4.s 09 // 9
IL_01F0 box Int32
IL_01F5 callvirt DataRow.set_Item (String, Object)
IL_01FA nop
IL_01FB ldarg.0
IL_01FC ldfld UserQuery._DataSet
IL_0201 callvirt DataSet.get_Tables ()
IL_0206 ldstr "settings"
IL_020B callvirt DataTableCollection.get_Item (String)
IL_0210 callvirt DataTable.get_Rows ()
IL_0215 ldc.i4.0
IL_0216 callvirt DataRowCollection.get_Item (Int32)
IL_021B ldstr "column10"
IL_0220 ldc.i4.s 0A // 10
IL_0222 box Int32
IL_0227 callvirt DataRow.set_Item (String, Object)
IL_022C nop
IL_022D ldarg.0
IL_022E ldfld UserQuery._DataSet
IL_0233 callvirt DataSet.get_Tables ()
IL_0238 ldstr "settings"
IL_023D callvirt DataTableCollection.get_Item (String)
IL_0242 callvirt DataTable.get_Rows ()
IL_0247 ldc.i4.0
IL_0248 callvirt DataRowCollection.get_Item (Int32)
IL_024D ldstr "column99"
IL_0252 ldc.i4.s 63 // 99
IL_0254 box Int32
IL_0259 callvirt DataRow.set_Item (String, Object)
IL_025E nop
IL_025F ldarg.0
IL_0260 ldfld UserQuery._DataSet
IL_0265 callvirt DataSet.get_Tables ()
IL_026A ldstr "settings"
IL_026F callvirt DataTableCollection.get_Item (String)
IL_0274 callvirt DataTable.get_Rows ()
IL_0279 ldc.i4.0
IL_027A callvirt DataRowCollection.get_Item (Int32)
IL_027F ldstr "column100"
IL_0284 ldc.i4.s 64 // 100
IL_0286 box Int32
IL_028B callvirt DataRow.set_Item (String, Object)
IL_0290 nop
IL_0291 ret
Die Intel x64 Assembler Unterschiede:
Zuerst der Assembler Code von „SetTableValues(…)“ (optimaler Code):
Die letzte Zeilennummer (in Hex) ist 0x017d = 575 dez.
L0000 push rbp
L0001 sub rsp, 0x80
L0008 lea rbp, [rsp+0x80]
L0010 xor eax, eax
L0012 mov [rbp-0x58], rax
L0016 xorps xmm4, xmm4
L0019 movaps [rbp-0x50], xmm4
L001d movaps [rbp-0x40], xmm4
L0021 movaps [rbp-0x30], xmm4
L0025 movaps [rbp-0x20], xmm4
L0029 movaps [rbp-0x10], xmm4
L002d mov [rbp-0x60], rsp
L0031 mov [rbp+0x10], rcx
L0035 mov [rbp+0x18], rdx
L0039 mov [rbp+0x20], r8d
L003d mov [rbp+0x28], r9
L0041 mov rax, 0x7ffd31adc320
L004b cmp dword ptr [rax], 0
L004e je short L0055
L0050 call 0x00007ffd906485f0
L0055 nop
L0056 nop
L0057 mov rcx, [rbp+0x28]
L005b mov r11, 0x7ffd31ad7020
L0065 mov rax, 0x7ffd31ad7020
L006f call qword ptr [rax]
L0071 mov [rbp-0x20], rax
L0075 mov rcx, [rbp-0x20]
L0079 mov [rbp-8], rcx
L007d nop
L007e jmp L0106
L0083 lea rdx, [rbp-0x38]
L0087 mov rcx, [rbp-8]
L008b mov r11, 0x7ffd31ad7030
L0095 mov rax, 0x7ffd31ad7030
L009f call qword ptr [rax]
L00a1 movups xmm0, [rbp-0x38]
L00a5 movups [rbp-0x18], xmm0
L00a9 nop
L00aa mov rcx, [rbp+0x10]
L00ae mov rcx, [rcx+0x10]
L00b2 cmp [rcx], ecx
L00b4 call System.Data.DataSet.get_Tables()
L00b9 mov [rbp-0x40], rax
L00bd mov rcx, [rbp-0x40]
L00c1 mov rdx, [rbp+0x18]
L00c5 cmp [rcx], ecx
L00c7 call System.Data.DataTableCollection.get_Item(System.String)
L00cc mov [rbp-0x48], rax
L00d0 mov rcx, [rbp-0x48]
L00d4 cmp [rcx], ecx
L00d6 call System.Data.DataTable.get_Rows()
L00db mov [rbp-0x50], rax
L00df mov rcx, [rbp-0x50]
L00e3 mov edx, [rbp+0x20]
L00e6 cmp [rcx], ecx
L00e8 call System.Data.DataRowCollection.get_Item(Int32)
L00ed mov [rbp-0x58], rax
L00f1 mov rcx, [rbp-0x58]
L00f5 mov rdx, [rbp-0x18]
L00f9 mov r8, [rbp-0x10]
L00fd cmp [rcx], ecx
L00ff call System.Data.DataRow.set_Item(System.String, System.Object)
L0104 nop
L0105 nop
L0106 mov rcx, [rbp-8]
L010a mov r11, 0x7ffd31ad7028
L0114 mov rax, 0x7ffd31ad7028
L011e call qword ptr [rax]
L0120 mov [rbp-0x24], eax
L0123 cmp dword ptr [rbp-0x24], 0
L0127 jne L0083
L012d nop
L012e jmp short L0130
L0130 mov rcx, rsp
L0133 call L0140
L0138 nop
L0139 nop
L013a lea rsp, [rbp]
L013e pop rbp
L013f ret
L0140 push rbp
L0141 sub rsp, 0x30
L0145 mov rbp, [rcx+0x20]
L0149 mov [rsp+0x20], rbp
L014e lea rbp, [rbp+0x80]
L0155 cmp qword ptr [rbp-8], 0
L015a je short L0177
L015c mov rcx, [rbp-8]
L0160 mov r11, 0x7ffd31ad7038
L016a mov rax, 0x7ffd31ad7038
L0174 call qword ptr [rax]
L0176 nop
L0177 nop
L0178 add rsp, 0x30
L017c pop rbp
L017d ret
Der Assembler Code von „InitSettingsValues()“ (nicht optimaler Code):
Die letzte Zeilennummer (in Hex) lautet: 0x0843 = 2115 dez.
L0000 push rbp
L0001 sub rsp, 0x1e0
L0008 lea rbp, [rsp+0x1e0]
L0010 xorps xmm4, xmm4
L0013 movaps [rbp-0x1c0], xmm4
L001a mov rax, 0xfffffffffffffe50
L0024 movaps [rax+rbp], xmm4
L0028 movaps [rbp+rax+0x10], xmm4
L002d movaps [rbp+rax+0x20], xmm4
L0032 add rax, 0x30
L0036 jne short L0024
L0038 mov [rbp+0x10], rcx
L003c mov rax, 0x7ffd3193c320
L0046 cmp dword ptr [rax], 0
L0049 je short L0050
L004b call 0x00007ffd906485f0
L0050 nop
L0051 mov rcx, [rbp+0x10]
L0055 mov rcx, [rcx+0x10]
L0059 cmp [rcx], ecx
L005b call System.Data.DataSet.get_Tables()
L0060 mov [rbp-8], rax
L0064 mov rdx, 0x1b5d3cd23a8
L006e mov rdx, [rdx]
L0071 mov rcx, [rbp-8]
L0075 cmp [rcx], ecx
L0077 call System.Data.DataTableCollection.get_Item(System.String)
L007c mov [rbp-0x10], rax
L0080 mov rcx, [rbp-0x10]
L0084 cmp [rcx], ecx
L0086 call System.Data.DataTable.get_Rows()
L008b mov [rbp-0x18], rax
L008f mov rcx, [rbp-0x18]
L0093 xor edx, edx
L0095 cmp [rcx], ecx
L0097 call System.Data.DataRowCollection.get_Item(Int32)
L009c mov [rbp-0x20], rax
L00a0 mov rcx, 0x7ffd30967238
L00aa call 0x00007ffd9050af00
L00af mov [rbp-0x28], rax
L00b3 mov r8, [rbp-0x28]
L00b7 mov byte ptr [r8+8], 0
L00bc mov r8, [rbp-0x28]
L00c0 mov rdx, 0x1b5d3ceb6b8
L00ca mov rdx, [rdx]
L00cd mov rcx, [rbp-0x20]
L00d1 cmp [rcx], ecx
L00d3 call System.Data.DataRow.set_Item(System.String, System.Object)
L00d8 nop
L00d9 mov rcx, [rbp+0x10]
L00dd mov rcx, [rcx+0x10]
L00e1 cmp [rcx], ecx
L00e3 call System.Data.DataSet.get_Tables()
L00e8 mov [rbp-0x30], rax
L00ec mov rdx, 0x1b5d3cd23a8
L00f6 mov rdx, [rdx]
L00f9 mov rcx, [rbp-0x30]
L00fd cmp [rcx], ecx
L00ff call System.Data.DataTableCollection.get_Item(System.String)
L0104 mov [rbp-0x38], rax
L0108 mov rcx, [rbp-0x38]
L010c cmp [rcx], ecx
L010e call System.Data.DataTable.get_Rows()
L0113 mov [rbp-0x40], rax
L0117 mov rcx, [rbp-0x40]
L011b xor edx, edx
L011d cmp [rcx], ecx
L011f call System.Data.DataRowCollection.get_Item(Int32)
L0124 mov [rbp-0x48], rax
L0128 mov rcx, 0x7ffd30967238
L0132 call 0x00007ffd9050af00
L0137 mov [rbp-0x28], rax
L013b mov r8, [rbp-0x28]
L013f mov byte ptr [r8+8], 1
L0144 mov r8, [rbp-0x28]
L0148 mov rdx, 0x1b5d3ceb6c0
L0152 mov rdx, [rdx]
L0155 mov rcx, [rbp-0x48]
L0159 cmp [rcx], ecx
L015b call System.Data.DataRow.set_Item(System.String, System.Object)
L0160 nop
L0161 mov rcx, [rbp+0x10]
L0165 mov rcx, [rcx+0x10]
L0169 cmp [rcx], ecx
L016b call System.Data.DataSet.get_Tables()
L0170 mov [rbp-0x50], rax
L0174 mov rdx, 0x1b5d3cd23a8
L017e mov rdx, [rdx]
L0181 mov rcx, [rbp-0x50]
L0185 cmp [rcx], ecx
L0187 call System.Data.DataTableCollection.get_Item(System.String)
L018c mov [rbp-0x58], rax
L0190 mov rcx, [rbp-0x58]
L0194 cmp [rcx], ecx
L0196 call System.Data.DataTable.get_Rows()
L019b mov [rbp-0x60], rax
L019f mov rcx, [rbp-0x60]
L01a3 xor edx, edx
L01a5 cmp [rcx], ecx
L01a7 call System.Data.DataRowCollection.get_Item(Int32)
L01ac mov [rbp-0x68], rax
L01b0 mov rdx, 0x1b5d3ceb6c8
L01ba mov rdx, [rdx]
L01bd mov rcx, [rbp-0x68]
L01c1 xor r8d, r8d
L01c4 cmp [rcx], ecx
L01c6 call System.Data.DataRow.set_Item(System.String, System.Object)
L01cb nop
L01cc mov rcx, [rbp+0x10]
L01d0 mov rcx, [rcx+0x10]
L01d4 cmp [rcx], ecx
L01d6 call System.Data.DataSet.get_Tables()
L01db mov [rbp-0x70], rax
L01df mov rdx, 0x1b5d3cd23a8
L01e9 mov rdx, [rdx]
L01ec mov rcx, [rbp-0x70]
L01f0 cmp [rcx], ecx
L01f2 call System.Data.DataTableCollection.get_Item(System.String)
L01f7 mov [rbp-0x78], rax
L01fb mov rcx, [rbp-0x78]
L01ff cmp [rcx], ecx
L0201 call System.Data.DataTable.get_Rows()
L0206 mov [rbp-0x80], rax
L020a mov rcx, [rbp-0x80]
L020e xor edx, edx
L0210 cmp [rcx], ecx
L0212 call System.Data.DataRowCollection.get_Item(Int32)
L0217 mov [rbp-0x88], rax
L021e mov rcx, 0x7ffd3096e688
L0228 call 0x00007ffd9050af00
L022d mov [rbp-0x28], rax
L0231 mov r8, [rbp-0x28]
L0235 movsd xmm0, [UserQuery.InitSettingsValues()]
L023d movsd [r8+8], xmm0
L0243 mov r8, [rbp-0x28]
L0247 mov rdx, 0x1b5d3ceb6d0
L0251 mov rdx, [rdx]
L0254 mov rcx, [rbp-0x88]
L025b cmp [rcx], ecx
L025d call System.Data.DataRow.set_Item(System.String, System.Object)
L0262 nop
L0263 mov rcx, [rbp+0x10]
L0267 mov rcx, [rcx+0x10]
L026b cmp [rcx], ecx
L026d call System.Data.DataSet.get_Tables()
L0272 mov [rbp-0x90], rax
L0279 mov rdx, 0x1b5d3cd23a8
L0283 mov rdx, [rdx]
L0286 mov rcx, [rbp-0x90]
L028d cmp [rcx], ecx
L028f call System.Data.DataTableCollection.get_Item(System.String)
L0294 mov [rbp-0x98], rax
L029b mov rcx, [rbp-0x98]
L02a2 cmp [rcx], ecx
L02a4 call System.Data.DataTable.get_Rows()
L02a9 mov [rbp-0xa0], rax
L02b0 mov rcx, [rbp-0xa0]
L02b7 xor edx, edx
L02b9 cmp [rcx], ecx
L02bb call System.Data.DataRowCollection.get_Item(Int32)
L02c0 mov [rbp-0xa8], rax
L02c7 mov r8, 0x1b5d3ceb6e0
L02d1 mov r8, [r8]
L02d4 mov rdx, 0x1b5d3ceb6d8
L02de mov rdx, [rdx]
L02e1 mov rcx, [rbp-0xa8]
L02e8 cmp [rcx], ecx
L02ea call System.Data.DataRow.set_Item(System.String, System.Object)
L02ef nop
L02f0 mov rcx, [rbp+0x10]
L02f4 mov rcx, [rcx+0x10]
L02f8 cmp [rcx], ecx
L02fa call System.Data.DataSet.get_Tables()
L02ff mov [rbp-0xb0], rax
L0306 mov rdx, 0x1b5d3cd23a8
L0310 mov rdx, [rdx]
L0313 mov rcx, [rbp-0xb0]
L031a cmp [rcx], ecx
L031c call System.Data.DataTableCollection.get_Item(System.String)
L0321 mov [rbp-0xb8], rax
L0328 mov rcx, [rbp-0xb8]
L032f cmp [rcx], ecx
L0331 call System.Data.DataTable.get_Rows()
L0336 mov [rbp-0xc0], rax
L033d mov rcx, [rbp-0xc0]
L0344 xor edx, edx
L0346 cmp [rcx], ecx
L0348 call System.Data.DataRowCollection.get_Item(Int32)
L034d mov [rbp-0xc8], rax
L0354 xor ecx, ecx
L0356 mov [rbp-0xd0], rcx
L035d lea rcx, [rbp-0xd0]
L0364 mov edx, 0x7d1
L0369 mov r8d, 9
L036f mov r9d, 0xb
L0375 call System.DateTime..ctor(Int32, Int32, Int32)
L037a mov rdx, 0x1b5d3ceb6e8
L0384 mov rdx, [rdx]
L0387 mov [rbp-0x1c0], rdx
L038e lea rdx, [rbp-0xd0]
L0395 mov rcx, 0x7ffd30bef900
L039f call 0x00007ffd9050af40
L03a4 mov [rbp-0x1b8], rax
L03ab mov r8, [rbp-0x1b8]
L03b2 mov rdx, [rbp-0x1c0]
L03b9 mov rcx, [rbp-0xc8]
L03c0 cmp [rcx], ecx
L03c2 call System.Data.DataRow.set_Item(System.String, System.Object)
L03c7 nop
L03c8 mov rcx, [rbp+0x10]
L03cc mov rcx, [rcx+0x10]
L03d0 cmp [rcx], ecx
L03d2 call System.Data.DataSet.get_Tables()
L03d7 mov [rbp-0xd8], rax
L03de mov rdx, 0x1b5d3cd23a8
L03e8 mov rdx, [rdx]
L03eb mov rcx, [rbp-0xd8]
L03f2 cmp [rcx], ecx
L03f4 call System.Data.DataTableCollection.get_Item(System.String)
L03f9 mov [rbp-0xe0], rax
L0400 mov rcx, [rbp-0xe0]
L0407 cmp [rcx], ecx
L0409 call System.Data.DataTable.get_Rows()
L040e mov [rbp-0xe8], rax
L0415 mov rcx, [rbp-0xe8]
L041c xor edx, edx
L041e cmp [rcx], ecx
L0420 call System.Data.DataRowCollection.get_Item(Int32)
L0425 mov [rbp-0xf0], rax
L042c mov rcx, 0x7ffd3096b258
L0436 call 0x00007ffd9050af00
L043b mov [rbp-0x28], rax
L043f mov r8, [rbp-0x28]
L0443 mov dword ptr [r8+8], 6
L044b mov r8, [rbp-0x28]
L044f mov rdx, 0x1b5d3ceb6f0
L0459 mov rdx, [rdx]
L045c mov rcx, [rbp-0xf0]
L0463 cmp [rcx], ecx
L0465 call System.Data.DataRow.set_Item(System.String, System.Object)
L046a nop
L046b mov rcx, [rbp+0x10]
L046f mov rcx, [rcx+0x10]
L0473 cmp [rcx], ecx
L0475 call System.Data.DataSet.get_Tables()
L047a mov [rbp-0xf8], rax
L0481 mov rdx, 0x1b5d3cd23a8
L048b mov rdx, [rdx]
L048e mov rcx, [rbp-0xf8]
L0495 cmp [rcx], ecx
L0497 call System.Data.DataTableCollection.get_Item(System.String)
L049c mov [rbp-0x100], rax
L04a3 mov rcx, [rbp-0x100]
L04aa cmp [rcx], ecx
L04ac call System.Data.DataTable.get_Rows()
L04b1 mov [rbp-0x108], rax
L04b8 mov rcx, [rbp-0x108]
L04bf xor edx, edx
L04c1 cmp [rcx], ecx
L04c3 call System.Data.DataRowCollection.get_Item(Int32)
L04c8 mov [rbp-0x110], rax
L04cf mov rcx, 0x7ffd3096b258
L04d9 call 0x00007ffd9050af00
L04de mov [rbp-0x28], rax
L04e2 mov r8, [rbp-0x28]
L04e6 mov dword ptr [r8+8], 7
L04ee mov r8, [rbp-0x28]
L04f2 mov rdx, 0x1b5d3ceb6f8
L04fc mov rdx, [rdx]
L04ff mov rcx, [rbp-0x110]
L0506 cmp [rcx], ecx
L0508 call System.Data.DataRow.set_Item(System.String, System.Object)
L050d nop
L050e mov rcx, [rbp+0x10]
L0512 mov rcx, [rcx+0x10]
L0516 cmp [rcx], ecx
L0518 call System.Data.DataSet.get_Tables()
L051d mov [rbp-0x118], rax
L0524 mov rdx, 0x1b5d3cd23a8
L052e mov rdx, [rdx]
L0531 mov rcx, [rbp-0x118]
L0538 cmp [rcx], ecx
L053a call System.Data.DataTableCollection.get_Item(System.String)
L053f mov [rbp-0x120], rax
L0546 mov rcx, [rbp-0x120]
L054d cmp [rcx], ecx
L054f call System.Data.DataTable.get_Rows()
L0554 mov [rbp-0x128], rax
L055b mov rcx, [rbp-0x128]
L0562 xor edx, edx
L0564 cmp [rcx], ecx
L0566 call System.Data.DataRowCollection.get_Item(Int32)
L056b mov [rbp-0x130], rax
L0572 mov rcx, 0x7ffd3096b258
L057c call 0x00007ffd9050af00
L0581 mov [rbp-0x28], rax
L0585 mov r8, [rbp-0x28]
L0589 mov dword ptr [r8+8], 8
L0591 mov r8, [rbp-0x28]
L0595 mov rdx, 0x1b5d3ceb700
L059f mov rdx, [rdx]
L05a2 mov rcx, [rbp-0x130]
L05a9 cmp [rcx], ecx
L05ab call System.Data.DataRow.set_Item(System.String, System.Object)
L05b0 nop
L05b1 mov rcx, [rbp+0x10]
L05b5 mov rcx, [rcx+0x10]
L05b9 cmp [rcx], ecx
L05bb call System.Data.DataSet.get_Tables()
L05c0 mov [rbp-0x138], rax
L05c7 mov rdx, 0x1b5d3cd23a8
L05d1 mov rdx, [rdx]
L05d4 mov rcx, [rbp-0x138]
L05db cmp [rcx], ecx
L05dd call System.Data.DataTableCollection.get_Item(System.String)
L05e2 mov [rbp-0x140], rax
L05e9 mov rcx, [rbp-0x140]
L05f0 cmp [rcx], ecx
L05f2 call System.Data.DataTable.get_Rows()
L05f7 mov [rbp-0x148], rax
L05fe mov rcx, [rbp-0x148]
L0605 xor edx, edx
L0607 cmp [rcx], ecx
L0609 call System.Data.DataRowCollection.get_Item(Int32)
L060e mov [rbp-0x150], rax
L0615 mov rcx, 0x7ffd3096b258
L061f call 0x00007ffd9050af00
L0624 mov [rbp-0x28], rax
L0628 mov r8, [rbp-0x28]
L062c mov dword ptr [r8+8], 9
L0634 mov r8, [rbp-0x28]
L0638 mov rdx, 0x1b5d3ceb708
L0642 mov rdx, [rdx]
L0645 mov rcx, [rbp-0x150]
L064c cmp [rcx], ecx
L064e call System.Data.DataRow.set_Item(System.String, System.Object)
L0653 nop
L0654 mov rcx, [rbp+0x10]
L0658 mov rcx, [rcx+0x10]
L065c cmp [rcx], ecx
L065e call System.Data.DataSet.get_Tables()
L0663 mov [rbp-0x158], rax
L066a mov rdx, 0x1b5d3cd23a8
L0674 mov rdx, [rdx]
L0677 mov rcx, [rbp-0x158]
L067e cmp [rcx], ecx
L0680 call System.Data.DataTableCollection.get_Item(System.String)
L0685 mov [rbp-0x160], rax
L068c mov rcx, [rbp-0x160]
L0693 cmp [rcx], ecx
L0695 call System.Data.DataTable.get_Rows()
L069a mov [rbp-0x168], rax
L06a1 mov rcx, [rbp-0x168]
L06a8 xor edx, edx
L06aa cmp [rcx], ecx
L06ac call System.Data.DataRowCollection.get_Item(Int32)
L06b1 mov [rbp-0x170], rax
L06b8 mov rcx, 0x7ffd3096b258
L06c2 call 0x00007ffd9050af00
L06c7 mov [rbp-0x28], rax
L06cb mov r8, [rbp-0x28]
L06cf mov dword ptr [r8+8], 0xa
L06d7 mov r8, [rbp-0x28]
L06db mov rdx, 0x1b5d3ceb710
L06e5 mov rdx, [rdx]
L06e8 mov rcx, [rbp-0x170]
L06ef cmp [rcx], ecx
L06f1 call System.Data.DataRow.set_Item(System.String, System.Object)
L06f6 nop
L06f7 mov rcx, [rbp+0x10]
L06fb mov rcx, [rcx+0x10]
L06ff cmp [rcx], ecx
L0701 call System.Data.DataSet.get_Tables()
L0706 mov [rbp-0x178], rax
L070d mov rdx, 0x1b5d3cd23a8
L0717 mov rdx, [rdx]
L071a mov rcx, [rbp-0x178]
L0721 cmp [rcx], ecx
L0723 call System.Data.DataTableCollection.get_Item(System.String)
L0728 mov [rbp-0x180], rax
L072f mov rcx, [rbp-0x180]
L0736 cmp [rcx], ecx
L0738 call System.Data.DataTable.get_Rows()
L073d mov [rbp-0x188], rax
L0744 mov rcx, [rbp-0x188]
L074b xor edx, edx
L074d cmp [rcx], ecx
L074f call System.Data.DataRowCollection.get_Item(Int32)
L0754 mov [rbp-0x190], rax
L075b mov rcx, 0x7ffd3096b258
L0765 call 0x00007ffd9050af00
L076a mov [rbp-0x28], rax
L076e mov r8, [rbp-0x28]
L0772 mov dword ptr [r8+8], 0x63
L077a mov r8, [rbp-0x28]
L077e mov rdx, 0x1b5d3ceb718
L0788 mov rdx, [rdx]
L078b mov rcx, [rbp-0x190]
L0792 cmp [rcx], ecx
L0794 call System.Data.DataRow.set_Item(System.String, System.Object)
L0799 nop
L079a mov rcx, [rbp+0x10]
L079e mov rcx, [rcx+0x10]
L07a2 cmp [rcx], ecx
L07a4 call System.Data.DataSet.get_Tables()
L07a9 mov [rbp-0x198], rax
L07b0 mov rdx, 0x1b5d3cd23a8
L07ba mov rdx, [rdx]
L07bd mov rcx, [rbp-0x198]
L07c4 cmp [rcx], ecx
L07c6 call System.Data.DataTableCollection.get_Item(System.String)
L07cb mov [rbp-0x1a0], rax
L07d2 mov rcx, [rbp-0x1a0]
L07d9 cmp [rcx], ecx
L07db call System.Data.DataTable.get_Rows()
L07e0 mov [rbp-0x1a8], rax
L07e7 mov rcx, [rbp-0x1a8]
L07ee xor edx, edx
L07f0 cmp [rcx], ecx
L07f2 call System.Data.DataRowCollection.get_Item(Int32)
L07f7 mov [rbp-0x1b0], rax
L07fe mov rcx, 0x7ffd3096b258
L0808 call 0x00007ffd9050af00
L080d mov [rbp-0x28], rax
L0811 mov r8, [rbp-0x28]
L0815 mov dword ptr [r8+8], 0x64
L081d mov r8, [rbp-0x28]
L0821 mov rdx, 0x1b5d3ceb720
L082b mov rdx, [rdx]
L082e mov rcx, [rbp-0x1b0]
L0835 cmp [rcx], ecx
L0837 call System.Data.DataRow.set_Item(System.String, System.Object)
L083c nop
L083d nop
L083e lea rsp, [rbp]
L0842 pop rbp
L0843 ret
Dazu mehr ist auf Wikipedia in Separation of Concerns zu lesen.