Hässlicher Code ist wie ein Kondom, Taschentuch oder Toilettenpapier. Man kann es nur einmal verwenden.
Guter Code hat einen Mehrwert. Wie die Weihnachtskeks-Schablonen/-Formen kann man ihn immer wieder verwenden/einsetzen.
Nomen est omen: Eine Funktion oder Prozedur tut genau das, was der Name sagt, nicht mehr und nicht weniger. Gilt auch für Namensräume, Klassen, Events, Variablen etc. Der Name muss 100%ig selbsterklärend, eindeutig und unmissverständlich sein.
Eleganter Code ist: kurz, klar, einfach, eindeutig, einprägsam und effizient. Alles andere ist plumper (dahin-gerotzter) Code.
Intelligente Software-Entwickler schreiben den einfachsten, kürzesten und flachsten Code (Eleganz!). Schlechte Software-Entwickler schreiben die kompliziertesten, längsten Zeilen und mehrfach verschachtelter Code.
Faule, aber clevere Software-Entwickler haben jeden Tag weniger zu tun als der Tag zuvor, während fleißige, aber schlechte Software-Entwickler jeden Tag gleich viel oder sogar mehr als der Tag zuvor tun müssen. (Siehe „Wenn die Dämme brechen“!)
Guter Code wird getestet, denn nur guter Code kann getestet werden. Schlechter Code kann gar nicht getestet werden. Die Aussagekraft der Tests von schlechtem Code = 0.
Code-Optimierung erfolgt erst nach vollständiger Implementierung und erfolgreichem Testen, nicht davor oder währenddessen.
Man muss sich Vieles überlegen und gut vordenken, bevor man einen Zug macht. Man muss sich auch Vieles überlegen und gut vordenken, bevor man ein paar Zeilen Code schreibt.
Bei einem Vortragsvideo von Univ. Prof. Harald LESCH auf YouTube, wo es um die Umwelt ging, hat er das Buch „Nationales Sicherheits Amt NSA“ (von Andreas ESCHBACH) erwähnt. Da er, so schien es mir, davon begeistert war, dachte ich mir, dieses Buch muss ich auch lesen. Zuerst dachte ich mir: „Ich bin eh von Fach! Ich kenne mich eh aus. Was werde ich schon aus diesem Buch (Neues) lernen?“ (Einbildung!) Da ich von Prof. LESCH sehr viel halte, entschied ich mich doch das Buch zu kaufen und lesen … Es war kein Fehler! Als ich das Buch bis ca. Seite 45 gelesen habe, könnte ich an Nichts Anderes denken! Dieses Buch, die Geschichte hatte mich voll gepackt.
Nachdem ich das Buch fertig gelesen habe, habe ich noch weitere siebenmal das Buch bestellt und verschenkt.
Die Geschichte in diesem Buch, ist die einfachste und effektivste Methode, Menschen die keine IT’ler sind oder geringes Sicherheits-Bewusstsein haben, beizubringen, warum das Thema IT-Sicherheit, Privatsphäre, Facebook, Google, Amazon, bargeldlose Zahlung, Massenüberwachung von E-Mails, SMS, Telefonate, „soziale“ Medien udg. usw. wichtig und kritisch sind.
Alles (aus) Gold glänzt, aber nicht alles was glänzt ist Gold. Alle Nüsse sind rund, aber nicht alles, was rund ist, ist eine Nuss. …
Jeder kocht Zuhause. Aber deswegen ist nicht jeder ein Koch. Jeder kann ein Auto-Motor oder -Getriebe zerlegen. Aber deswegen ist nicht jeder ein Auto-Mechaniker. Jeder kann mit einer Lötpistole (oder einem Lötkolben) in einem Radio oder Fernseher herum löten. Aber deswegen ist nicht jeder ein Elektroniker. Jeder kann mit einem Taschenrechner umgehen, aber deswegen ist nicht jeder ein Mathematiker. Jeder kann beim Schachspielen drei Züge vorausdenken, aber deswegen ist nicht jeder ein Profi-Schachspieler. …
Nur weil man in eine Objekt-orientierte Programmier-Sprache wie C++, Java oder C# Code schreibt, heißt es noch lange nicht, dass das Programm (der Code) Objekt orientiert ist!
Ich habe C# Code in „professioneller“ Umgebung (Industrie) gesehen und gelesen … Es war SPS/PLC Programmier-Stil in .NET/C# ! Ja, ich weiß! Ich hätte es selbst nicht geglaubt, wenn ich den Code nicht persönlich gelesen hätte (eine mind. viermonatige Tortur! Eine pure Verschwendung von teurem Arbeits- und Lebens-Zeit! Dazu noch: Augen- und Hirn-Schmerzen sowie schlaflose Nächte! Das wünsche ich niemandem!). Ich selbst habe früher Mal, als Autodidakt, Visual Basic programmiert, ohne je von OOP, Klassen, Interfaces, Kapselung, Vererbung, Polymorphismus usw. je gehört/gelesen oder verstanden zu haben. Es hat (damals für mich) „funktioniert“. Dessen Code-Qualität war gleich 0 (null), bzw. eher am Ende der Minus-Bereich, je-nach Code-Qualitäts-Bewertungs-System.
Jede Programmier-Sprache hat seine Geschichte, geschichtliche Entwicklung, Konzepte, Paradigmen sowie „Eigenheiten“ und „Features“.
Es ist von großer Wichtigkeit die Geschichte einer Programmier-Sprache, dessen Sprach-/Programm-Elemente, Paradigmen und Konzepte zu kennen. Erst dadurch kann man sie 1.) begreifen und 2.) wissen Wann, Wo, Wie und Warum ein Programm-Element (Pre-Compiler-Symbol, Konstanten, Enumerations, Properties, Delegates, Events, usw.) oder OOP-Muster zu verwenden sei.
Jemand der C++ beherrscht kann nicht automatisch auch Java oder C# beherrschen. Jemand der Java beherrscht kann nicht automatisch auch C# beherrschen.
Beweis durch Widerspruch: Annahme: Wer C++ beherrscht, kann automatisch genauso Java/C# beherrschen. Vergleiche in alle drei Sprachen werden mit dem Schlüsselwort „if“ durchgeführt. Gegeben:if ( person != null && person.Name == "Bob" ) und die Variable person ist null. In C++ (bis mind. C99 Standard) wird ein Fehler ausgelöst (Null Reference), weil person.Name == ... ausgeführt wird, und die Variable person ist/referenziert ja null! Man kann nicht auf Etwas das NULL ist, auf dessen Eigenschaft/Variable/Methode (in diesem Fall „Name“) zugegriffen werden.
In Java und C# hingegen geht es gut, weil beide Sprachen den sogenannte „Kurzschluss-Ausschluss-Verfahren“ beim Vergleichen anwenden (was in C++ je nach Compiler und Standard nicht gibt/gab). Das heißt, nachdem „person != null“ Falsch (false) ist, und der nächste Vergleich Konjunktiv („&&“) gebunden ist, wird der Rest („person.Name == ...„) nicht mehr ausgewertet, da es gilt: false && True_Or_False ==> false oder binär (0 && (0 || 1) ==> 0). („==>“ steht hier für „daraus folgt“). Daher der Name: Kurzschluss-Ausschluss-Verfahren. Quod erat demonstrandum! (1)
Nun unterscheiden sich auch die Semantik (Bedeutung) und somit das Verhalten zwischen Java und C# auch noch: Gegeben: person ist nicht null UND der Inhalt von person.Name ist „Bob„.
In Java: person.Name == "Bob" erzeugt einen neuen anonymen immutable String Object(eine Konstante) von Typ String mit dem Inhalt „Bob“ und vergleicht den Referenzen von person.Namemit der Referenz von anonymen immutable String Object. Das Resultat ist: false, da jedes Object auf eine andere Adresse zeigt, und somit es sich um zwei unterschiedliche Referenzen handelt.
In C# werden hingegen die Inhalte von beiden immutable String Objekten (person.Name und anonymen String Objekt, = Konstante) durch den Operator „==“ verglichen. Das Resultat ist: true, da der Wert von „person.Name“ inhaltlich dem anonymen immutable String Objekt (Konstante) „Bob“ gleicht. Kurz: Strings in Java und C# sind immutable Objects (siehe und vergleiche ECMA-334, Abschnitt 8.2.1 „Predefined types“ mit Java-String von Oracle!) In Java müsste der Code so umgeschrieben werden damit es funktioniert: if (person != null && person.Name.equals("Bob"))… Quod erat demonstrandum! (2)
Dazu kommt noch…
Das Kennen von Schlüsselwörter (if, else, new, while, …) sowie die Grammatik (Syntax) einer Programmiersprache reicht nicht aus um es zu „können“. Man kann dadurch den Code höchstens lesen. Um eine Programmiersprache zu beherrschen („können“), sind daher weitere Kenntnisse unbedingt erforderlich:
Paradigmen und Konzepte (Heap vs. Stack, Class vs. Struct, Copy-by-Value, Copy-by-Reference, Immutable Types, OOP Design Patterns, Garbage-Collector/-Collection, Exception-Handling, Generizität, statischer vs. dynamischer Datentyp einer Variable,…)
Compiler (Was, Wie und Wo wird optimiert? Was wird während Compilierung und was während Runtime (Laufzeit) übersetzt, geprüft, ausgeführt? Z. B. findet in Java (ab Vers. 1.5 = Java 5) die Typ-Prüfung bei generische Typen erst zur Laufzeit (Runtime), weshalb der Compiler (da Java Type-Safety garantieren möchte) während Compilierung „Warning“ ausgibt. Bei C# jedoch findet die Typ-Prüfung bei generische Typen während Compilierung statt, und sollte Type-Safety nicht gegeben sein, gibt der C#-Compiler „Error“ aus. Siehe und Vergleiche auch Just-In-Time sowie Ahead-Of-Time Compiler! Zusätzlich: C# ermöglicht direkten Zugriff und Manipulation auf Speicher und dessen Inhalt (nur wenn der Code-Block mit „unsafe“ Schlüsselwort, sowie die Assembly als „Unsafe“ markiert wird), was in C++ normal/business as usual ist und Java gar nicht anbietet!
Ich habe ein Modem/Router im Jahr 2017 von A1 erhalten. Bis heute (09.07.2021) hat es nie ein Update dafür gegeben, obwohl wöchentlich, manchmal täglich, neue Sicherheitslücken in irgendwelche Software-Modulen, Internet-Protokolle udg. gemeldet und veröffentlicht werden. Wie kann das sein?
Die Modems/Router von Internet Provider (A1, Telekom, UPS, …) sind extrem billige Geräte. Sie nutzen, wie viele andere Internet-fähige Geräte (Switches, NAS, Tablets, Smartphones, Smart-TVs, …) Software-Module die „open source“ sind und für kommerzielle Zwecke sogar gratis verfügbar sind. Und hier liegt das Problem. Falls in diese Software-Module Sicherheitslücken udg. erkannt und beseitigt werden, dauert es lange, wenn überhaupt, dass die Internet-Provider einen Sicherheits-Patch/-Update erstellen und liefern. Leider! Wie mein Modem-Router.
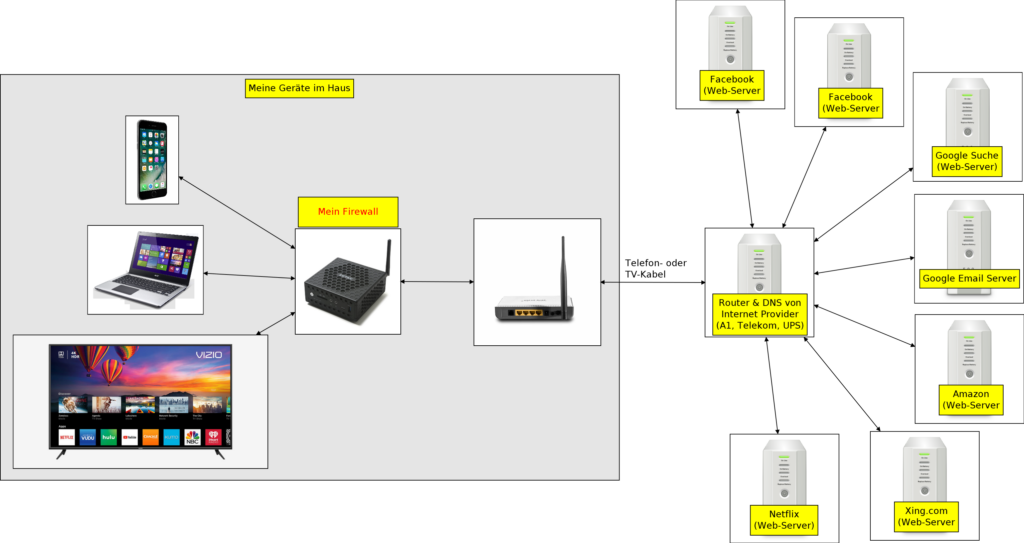
Aus diesem Grund verwende ich seit 2007 mein eigenes Firewall-System/-Gerät, welches ich hinter dem Modem/Router von meinem Internet-Provider anschließe.
Ports blockieren (nach Innen und Außen) die nicht notwendig sind
verlässlich, einfach und immer aktuell IP Pakete blockieren/wegwerfen die infektiös sind (Attacken: DOS, DDOS, Kill-Bits, Trojaner, Viren, …)
verlässlich und einfach Werbe-Fotos/-Videos blockieren
verlässlich, einfach und immer aktuell einzelne URLs, IP-Adressen oder Netzwerke blockieren, welche für ihre Schad-Programme (Viren, Trojaner udg.) bekannt sind
einfach ganze Gruppen an Inhalte (Web-Adressen) sperren/filtern, wie z. B.: Casino, Viagra, Warez, …
Unsichtbare Web-Cache (Proxy) der Bilder und andere Dateien (wie z. B. Google-Logo-Bilder) beim ersten Besuch/Aufruf einer Webseite speichert –> ab dann kommen diese Inhalte von meinem Firewall/Web-Cache und nicht aus dem Internet –> schneller surfen & große Dateien herunterladen
DHCP Dienst: meine Geräte haben/bekommen immer die gleichen privaten IP-Adressen (seit 2007)! Ich muss meine Netz-Laufwerke (NAS), Drucker, Scanner etc. nie konfigurieren (obwohl ich inzwischen 6 Mal umgezogen/übersiedelt bin). Ich muss nur die MAC-Adressen neue Geräte, die ich mir kaufe, einmalig eingeben, und die Regeln (was darf dieser und was nicht) für diese festlegen.
Traffic Shaping: verteilt den Datenlasten zugunsten von Web-Surfen oder Emails-Lesen automatisch, während große Dateien von irgendeinem PC oder Notebook heruntergeladen werden.
Verbieten von „ET nach Hause telefonieren“: Ich kann mir nach der Installation von neuem App oder Anwendung auf dem PC, genau anschauen, wohin/mit wem sich dieses Verbinden will und welche Daten sie zu senden versucht. Je nach Bedarf erlaube ich den Zugang nach Außen durch diese App/Anwendung oder ich blockiere es.
Das Betriebssystem, die Modulen und Regeln sind immer Up-to-Date (aktuell).
Intrusion Detection System (IDS): Einbruchs-Versuche in meinem Netz werden protokolliert (wann, IP, Port, welche Art), verhindert und ich könnte sogar den Absender zurück-attackieren lassen (juristische Grauzone!).
Alles, was man dazu benötigt ist, ein kleiner Rechner, mit sehr geringem Strom-Verbrauch und mindestens zwei Ethernet-Büchsen (RJ-45) und eine eingebautes (Onboard) Wi-Fi Modul mit Antenne.
Als Firewall-Betriebssystem kann man dann IPFire oder OPNsense oder pfSense Community installieren. Hände weg von eingestellte Systemen wie m0n0wall oder IP Cop! Diese werden seit langem nicht mehr weiterentwickelt (Rest In Peace m0n0wall! Du hast mir das Leben als GBH-Admin um einiges leichter gemacht).
„Sicherheit“ ist nur ein Gefühl. 100 prozentige Sicherheit gibt es nicht! Niemand ist 100 prozentig neutral!
Die Schweizer Firma „Crypto AG“ stellte Maschinen für professionelle Verschlüsselung her. Diese wurden sowohl von Firmen, aber auch von Staaten, Nachrichten-Dienste, internationale Organisationen und Konzerne eingesetzt.
Irgendwann stellte sich heraus, dass die Crypto AG von BND und CIA betrieben und deren Verschlüsselungs-Maschinen/-Methoden/-Algorithmen absichtlich mit „Lücken“ versehen waren …!
Die Ereignisse am 11. Sept. 2001 haben Einiges in USA und weltweit verändert. Hier möchte ich nur auf 5 Dinge eingehen:
Freedom of Information Act wurde ausgehebelt/ausgesetzt: Früher dürfte man als US-Bürger zu einem beliebigen US-Amt gehen, und nach Dokumenten verlangen. Diese Dokumente dürfte man dann, gegen einen geringen Kopier-Kosten-Betrag, kopieren und nach Hause mitnehmen. Z. B.: Jemand wollte sich den Bericht über die Schadstoff- und Qualitäts-Werte des Wassers in seiner Gemeinde erkundigen. Er/Sie ging zu dem Amt, bekam die Akten/Berichte, könnte sich diese durchlesen, kopieren und die Kopien mitnehmen … Es gibt nur mehr komplett geschwärzte Zeilen und Seiten. Nicht zu verwechseln mit DGSVO!
Das Recht auf Anwalt haben die US-Bürger nicht mehr (ganz)! Lavabit war ein US-Unternehmen, welches besonders sicherer (verschlüsselte) E-Mail-Dienst anbot. Eines Tages kam ein FBI Beamter, der sich auswies, mit ein paar „Man in Black“ Typen, die sich nicht auswiesen, und der FBI-Mann bestätigte, dass diese ebenfalls von Regierung seien und sich nicht-auszuweisen brauchen. Sie verlangten die Entschlüsselung des Systems und alle E-Mail-Konten, was der Betreiber technisch nicht imstande war. Außerdem bedeutete dies das Ende seiner Firma! Der Betreiber wurde belehrt, dass er gemäß Patriot Act und weitere neue Gesetze „Nichts unternehmen darf was dazu führen KÖNNTE, dass die Öffentlichkeit davon informiert wird.“ Damit KÖNNTE er von seinem Recht auf Anwalt nicht gebrauch machen, um gegen die Entschlüsselungen-Aufforderung vor Gericht zu ziehen (Anwalt, Richter, Staatsanwälte und Gerichtsmitarbeiter KÖNNTEN somit informiert werden).
Der Fall von Cisco Geräte mit NSA-Firmware-Versionen: Cisco Geräte (Router, Switches) die von große Konzerne oder staatliche Ämter/Organe in Ausland bestellt wurden, wurden von NSA abgefangen, Pakete geöffnet, die NSA Firmware-Version installiert, professionell wieder verpackt (sogar mit original Cisco 3D Laser-Holo-Labels) und dann verschickt. Bei einigen Geräten, nachdem man im Ausland die Firmware aktualisiert hatte, funktionierten die Geräte nicht mehr … Und so ist man denen auf die Schliche gekommen Es ist nun mal so, dass nicht jeder einfach für jedes Gerät einen Firmware schreiben kann. Man muss von dem Gerät sehr detailliertes Wissen haben, was nur die Cisco-Mitarbeiter in Entwicklungs-Teams haben können! Alles Klar was ich sagen möchte?
Die sicher geglaubte Kryptografie: Es war 2013 … Edward Snowden war überall zu sehen, hören und lesen. Einige Ereignisse danach wurden (leider) nicht oft bzw. lang genug in Medien thematisiert: Einschleusung von NSA-Mitarbeiter als Software-Entwickler in diverse Unternehmen. So wurden unter anderem Hintertüren (backdoor) in Systemen, und Trojaner auf Installations-Medien eingebaut … Und den Bereich für tatsächlich erzeugten privaten Schlüssel (Private Key, für asymmetrische Verschlüsselung alá RSA und PGP) erheblich beschränkt (statt gepriesene so-und-so-mega-peta-giga-trillionen-milliarden Möglichkeiten wurden nur ein paar tausend tatsächlich erzeugt, sodass die NSA & Co für die Brute-Force-Entschlüsselung weniger als zwei Stunden benötigten!).
Die Kaspersky-Antivirus-Software (mit künstlicher Intelligenz): Kaspersky kommt bekanntlich nicht aus USA, sondern aus Russland. Die fingen an (ich glaube 2012) mithilfe der KI die Dateien sowie Netzwerk-Verhalten von Systemen und Software zu analysieren … etwas das sich als erfolgreich erwiesen hat. Wurden ein paar wenige Systemen von Schadsoftware befallen, so wurde sofort die Signaturen (Fingerprints, Hash summen) von Dateien, neu installierte Software sowie das Netzwerk-Verhalten von denen, die zuvor in Kaspersky-Netz gespeichert wurden, als Wiedererkennungs-Signale an allen anderen Kaspersky-Antivirus-Clients weitergereicht. Für NSA & Co bedeutete dies: Die müssten für jeden PC ihre Schadsoftware ändern (damit neue unterschiedliche Signatur entstand) plus dessen Verhalten ändern (was viel schwieriger ist) … Was geschah? FBI-Männer in Begleitung von „Man in Black“ klopften an die Türen der Kaspersky-Büros in USA… Zusätzlich/Parallel startete man eine Schmutzkübel-Kampagne und warnte über US-Medien „man befürchte Sicherheitsrisiken durch Kaspersky-Antivirus“ … Es wäre ja auch schade um die Millionen US $ die NSA in Microsofts Defender investiert hatte …
Wenn man sich den Fall von Lavabit anschaut und Kaspersky sowie Krypto-Algorithmen-Sabotage dazu addiert … Dann … Ja dann könnte man auf komische Ideen kommen.
Daher erstaunt es mich immer wieder, wenn bei jedem Virus, Trojaner etc. immer wieder behauptet wird: Die Russen waren es! Wie kann es sein, dass „die Russen“ so „einfach“ in IT-Systemen eindringen können? Schauen wir uns doch das Ganze mal in Ruhe sachlich an:
Welche Betriebssysteme haben unsere Geräte?
Kommen die Microsoft Windows (3.11, 95, 98, 2000, NT4, XP, Vista, 7, 8, 10,…) aus Russland?
Kommen Apple OS X und iOS aus Russland?
Googles Android? Auch nicht aus Russland? Hmmm…. komisch!
Fast hätte ich es vergessen … Und Linux?
Welche Suchmaschinen verwenden wir?
Kommt Google Search aus Russland?
Kommt Microsoft Bing aus Russland?
Und Yahoo kommt auch nicht aus Russland? Wird immer komischer!
Ach ja! Wolfram Search?
Welche TOP 11 Profi-Netzwerk-Geräte (Router, Bridges und Switches) werden weltweit in Ämter, staatliche Organe, große Organisationen und Konzerne eingesetzt?
Nur fürs Protokoll: Alle von uns eingesetzten Betriebssystemen, Suchmaschinen und die wichtigsten Netzwerkgeräte (sowie alle Internet-Protokolle und Standards) kommen aus USA. Ein Schelm Putin-Versteher und „Anti-Amerikanist“ wer sich Böses Verschwörungstheorien denkt!
Wie schaut es bei uns in der EU aus? Wer in Österreich, Deutschland, Frankreich, Spanien, Italien, Schweden usw. baut Profi-Router/Switches? Und Patch-Kabel? Nicht einmal das Patch-Kabel! Wir müssen sogar ein lächerliches Patch-Kabel aus Asien (China & Tiger-Staaten) kaufen/importieren. So viel zu EU, Industrie 4.0 und Digitalisierung.
Wir sind zu 100 % von USA und China abhängig! Was wenn …?
Hier erkläre ich, anhand von praktischen Beispielen, worum es geht und wie das Spionieren durch Konzerne/Firmen über WWW (Webseiten, Handy-Apps, Bankomatkarte) funktioniert.
Eine Webseite (auch E-Mails die in „HTML“ Format empfangen werden) kann folgende Dinge enthalten:
Ausführbare Skripte (JavaScript)
Frameworks: Sammlung vorgefertigte „Koch-Rezepte“ (JavaScript), wie z. B. JQuery und JQuery UI
Elemente (Bilder, Schriftarten, Werbe-Banner oder komplette Webseite) von fremden (3rd Party) Webseiten (z. B. in sogenannte Rahmen „Frames“, oder transparente 1 × 1 Pixel „Bilder“)
CSS (Beschreibung-Skripte welche Dinge, wie dargestellt werden sollen, wie z. B.: Farben, Schriftart, Schriftgröße udg.)
„Cookies“: eine Datei das irgendwelche Name-Wert-Paare enthält wie z. B.: „IstAngemeldet=Ja“ oder „LetzteAktivitätZeitstempel=2021-12-31 23:59:59“ udg.
Dein Netzwerk bei dir Zuhause ist der Verräter!
Egal ob über das Telefon- oder TV-Kabel, du hast ein Modem von deinem Internet-Anbieter (A1, Telekom, UPS, …) bei dir Zuhause. Diese hat eine eindeutige IP-Adresse, sowie ein paar RJ-45 Büchsen und einen WLAN (damit du Zuhause mit dem Handy oder Notebook, ohne Kabel, statt 3G/4G/LTE/5G ins Internet kommst).
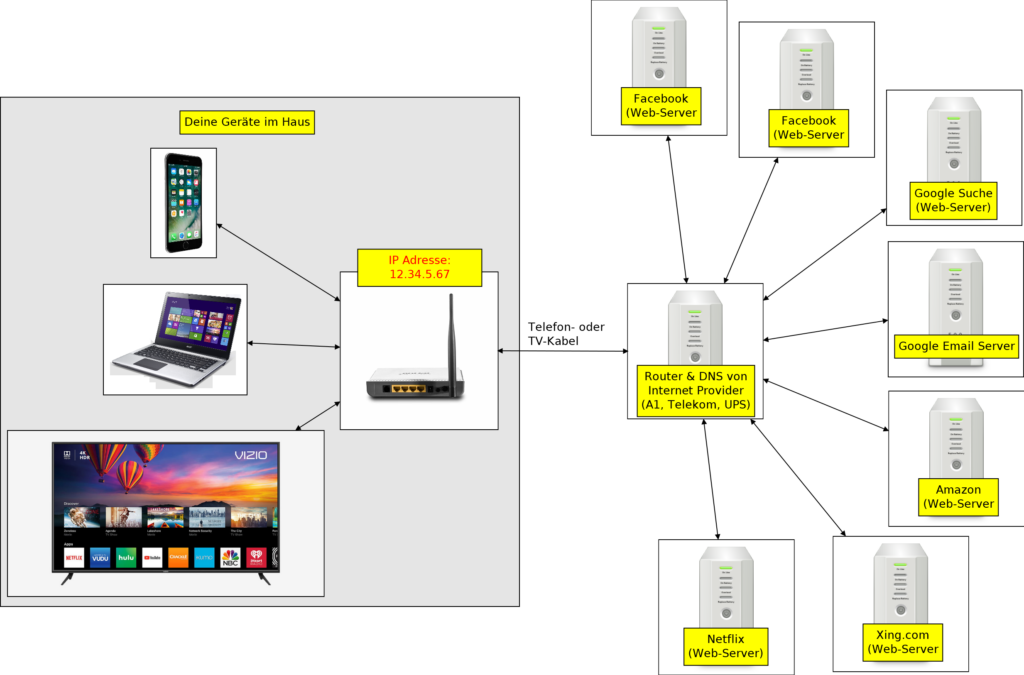
Es ist völlig egal, mit welchem Gerät im Haus, du ins Internet gehst (E-Mails von Google Mail „Gmail.com“ liest, in Amazon nach einem Produkt suchst und es online kaufst, Online-Banking machst, in Facebook ein Bild postest, mit TV Videos von YouTube oder Netflix anschaust usw.). Deine IP-Adresse (12.34.5.67), die von deinem Modem/Router, ist eindeutig, für jeden im Internet sichtbar (sonst wurde Internet nicht funktionieren), und damit kann man dich eindeutig identifizieren (die IP-Adresse ist wie ein Finger-Abdruck). Probiere den Link „Deine IP-Adresse“ mit verschiedene Geräte aus!
So! Und nun schauen wir mal was jeder einzelner Dienst-Anbieter (Google, YouTube, Facebook, Amazon, Xing.com, …) von dir weiß und (gegen Bezahlung oder Austausch-Vertrag) mit anderen austauschen kann.
Nehmen wir als Beispiel eine erdachte Person „Anton Berger“ der in Wien wohnt. Anton nimmt sein Notebook, öffnet den Internet Explorer, geht auf Google.com und sucht nach „sexy blondinen fotos“. Und klickt auf einem Link „Sex Magazin XYZ“.
Datenbank der Webseite von Google (Such-Maschine): Suchanfragen-Tabelle:
IP Adresse
Webbrowser ID
Was wurde gesucht?
12.34.5.67
Internet Explorer 0.8.15 (Windows 10 Pro, DE…)
sexy blondinen fotos
…
…
…
Jetzt nimmt er sein iPhone in die Hand, öffnet die Amazon-App. Nanu! In Amazon-App wird jede menge Werbung für Sex-Magazine, Sex-Kalender und Sex-Artikel gemacht! Der Anton bestellt sich den „Super Pervers Sex Magazin XXX“, und bezahlt es mit seiner Kreditkarte.
Datenbank von Amazon: Verkaufte Artikel:
Verkaufs ID
Konto ID
Artikel ID
Kreditkarten-Nr.
Betrag
…
…
1234
234
345
987654321000
100€
…
…
…
…
…
…
…
…
…
Amazon-Konten-Tabelle:
ID
Vorname
Nachname
Telefon
PLZ
Ort
Straße
…
234
Anton
Berger
012345678
1234
Wien
Berger Str. 1/2/3
…
…
…
…
…
…
…
…
…
Artikel-Tabelle:
ID
Name
…
345
Super Pervers Sex Magazin XXX
…
…
…
…
Datenbank deiner Bank („Banka Balkonia Finance Group“): Konten-Tabelle:
ID
Bankomat-Karten-Nr.
Kreditkarten-Nr.
Name
Adresse
777
1234567890
987654321000
Anton Berger
1234 Wien Berger Str. 1/2/3
…
…
…
…
Letzte-Transaktionen:
Konto-ID
Wann
IP Adresse
Client
Client-/Web-Broser-ID
777
01.02.2019 12:30:00
12.34.5.67
Handy App
…
777
28.02.2020 01:59:59
12.34.5.67
Web Browser
Internet Explorer 0.8.15 (Windows 10 Pro, DE…)
Nun schaltet der Anton seinen TV ein und öffnet den Netflix oder YouTube TV-App. Nanu! Es werden jede menge Werbung für Erotik-Filmen gezeigt.
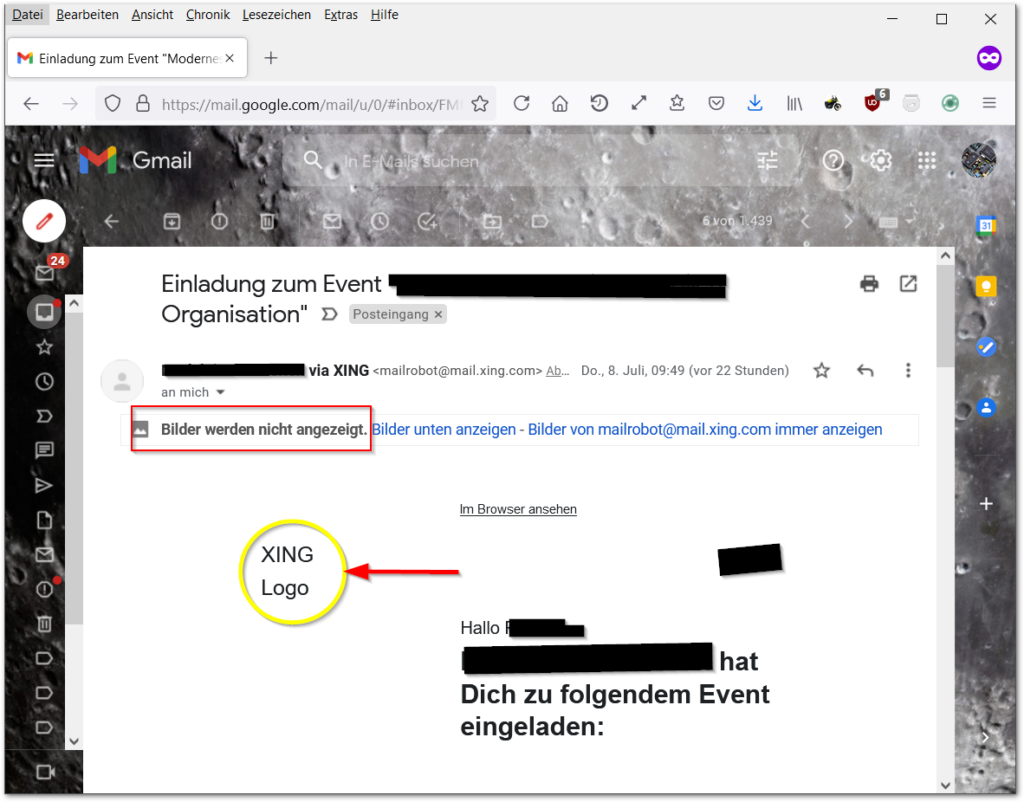
Am nächsten Tag schaut sich Anton seine E-Mails auf seinem PC an. Dazu öffnet der seinen Firefox Webbrowser. Er hat eine neue E-Mail von Xing (oder Facebook, Twitter, LinkedIn, WerAuchImmer…). Er war so klug und hat Gmail so eingestellt, dass die Bilder in E-Mails nicht automatisch geladen und gezeigt werden (eigentlich reicht es, wenn die Bilder geladen werden, diese müssen jedoch nicht gezeigt werden! So macht das z.B. GMail-App von Google! Warum das von Interesse ist, kommt später).
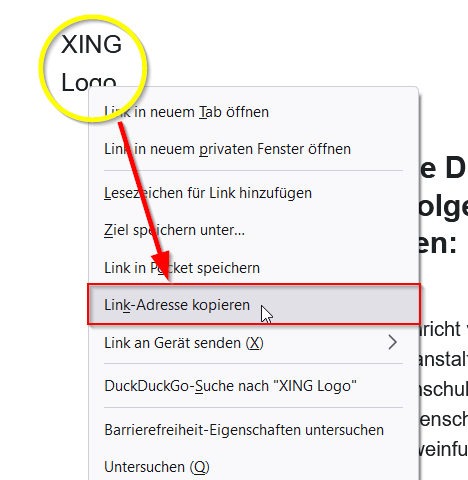
Der Anton klickt auf „Bilder unten anzeigen“. Was passiert da? Es wird in Wahrheit kein Bild von Web-Server geholt, sondern ein einzigartiger Link, welcher eine Signatur nur für Anton enthält aufgerufen. Dahinter versteckt sich ein Programm, welches auf dem Web-Server gestartet wird. Dieser sucht in der Datenbank nach die eindeutige Signatur und vervollständigt (zum Beispiel) folgende Einträge: Wer hat wann mit welche IP-Adresse mithilfe welchem Client diesen Link aufgerufen, und was soll nun gesendet werden. Erst danach wird das Logo/Bild gesendet! Wenn man z. B. in einem Webbrowser wie Firefox, Rechts-Klick auf dem „Xing Logo“ macht und in Kontextmenü auf „Link-Adresse kopieren“ wählt … (siehe Bild unten!) …
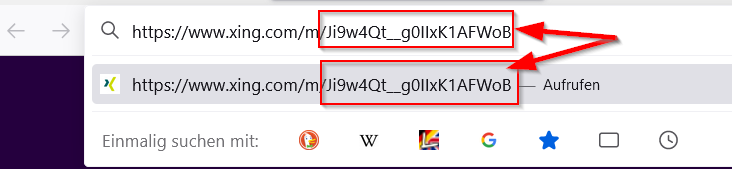
Dann kann man sich den Link irgendwo anders (z. B. in einem Text-Editor oder Adresszeile des Browsers) genauer anschauen, wie hier im Bild unten:
Anhand der IP-Adressen + „User Agent“ Eigenschaften kann man eine Tabelle anlegen, und sämtliche Aktivitäten verfolgen. Der Internet-Provider (z. B. A1, Telekom, UPS, …) können dies jederzeit tun. Die DNS (Domain Name Server) liefern die IP-Adressen für Links/URLs, die für Menschen leichter verständlich sind. Zum Beispiel: für „www.amazon.de“ wird „99.88.123.250″ zurückgeliefert. Somit kann jeder DNS Betreiber (auch A1, Telekom, UPS, …) wissen, wann man aufwacht, wann man seine E-Mails von welchem E-Mail-Anbieter liest, … und so weiter bis zum, wann man wieder Zuhause ist und schläft. Die IP-Adressen von Modem/Router werden zwar von Zeit zu Zeit geändert … aber es gibt jede menge andere Meta-Daten, die man ebenfalls zur Verfügung hat, und aus einer Submenge von ihnen, ist es möglich immer genau zu sagen, wer schon wieder (und wie oft) auf www.playboy.com herum-surft usw.
Ein „User Agent“ ist in der Web-Sprache, eine lange Text-Zeile, die einiges über das verwendete Client (Amazon-App, Banken-App, Internet Explorer, Chrome, Firefox, Samsung-Smart-TV-YouTube-App etc.) aussagt, wie z. B.:
Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0
Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/51.0.2704.106 Safari/537.36 OPR/38.0.2220.41
Opera/9.80 (Macintosh; Intel Mac OS X; U; en) Presto/2.2.15 Version/10.00 Opera/9.60 (Windows NT 6.0; U; en) Presto/2.1.1
Und wie man sieht, steht in „User Agent“ viel mehr als einem lieb ist: Name und Version von Client, Betriebssystem-Name und -Version, 32 oder 64 Bit. Dieser Text wird immer an dem Webserver gesendet!
Dann kommen noch die Skripte (JavaScript) die in Webseiten, auf deinem Handy/Notebook/TV, ausgeführt werden. Diese können dann unter anderem folgende Dinge über dich verraten: Wie groß ist dein Bildschirm (1920 × 1080 Pixel), welche Farbtiefe ist eingestellt, und welche „Plug-ins“ bzw. „Add-ons“ du installiert hast, welche Sprache du auf dein System verwendest („de“, „en“, „us“,…) … und einiges mehr.
Dann gibt es die Cookies auch noch 🙂 Diese speichern Informationen in einem Cache Verzeichnis auf dein Gerät. In denen stehen Dinge wie: Wann hast du dich angemeldet, bist du überhaupt angemeldet, was hast du gewählt, gesucht, geklickt usw. Manche diese Cookies sind sogenannte 3rd-Party-Cookies. Diese speichern Daten über dich, um dich für andere Webseiten eindeutig und leichter zu identifizieren. Bei mir werden diese immer deaktiviert (Firefox). Sobald du eine andere Webseite besuchst, kann er auf diese 3rd-Pary-Cookies zugreifen und sich anschauen, wofür dich interessierst oder bisher so gemacht hast.
Dann gibt es noch 3rd-Party-Dinge wie z. B. Video- oder Musik-Player. Du gehst auf die Webseite „www.illegal-kinofilme-gratis-anschauen.com“ und schaust dir den neuen Schinken aus Hollywood (eine Sony-Produktion) an. Irgendwann gehst du auf eine andere Seite und schaust dir z. B. ein Werbe-Video an … Was glaubst du, was dieser Video-Player alles über dein Gerät und somit dich speichert und weitergibt? Was mach der Verein Anti Piraterie (VAP) mit deiner IP-Adresse und Zeitstempel, wenn sie an die Daten von beschlagnahmten Server kommen (von wo du die illegal MP3 oder Videos heruntergeladen/angehört/angesehen hast)?
Die meisten Webseiten im Internet benutzen sogenannte Frameworks: JQuery, JQuery UI, WordPress,… Was glaubst du was diese an Daten abfragen und weiterleiten/austauschen/verkaufen?
Sprichst du gerne mit Alexa, Siri, Cortana & Co? Sind diese immer eingeschaltet (= horchen immer zu)? Hast du gewusst, dass das was du denen sagst zuerst zum Amazon, Apple, Microsoft etc. gesendet wird, damit deren Künstliche Intelligenz dein Gesprochenes zu Text umwandelt?
Trägst du eine moderne Armband-Uhr, welche mit deinem Handy verbunden ist oder direkten Zugang zum Internet hat? Könnte es sein, dass die Versicherung wo du deine private Kranken-Versicherung abgeschlossen hast, an diese Daten Interesse hat?
Gehst du gerne Laufen? Werden deine Lauf-/Sport-Aktivitäten sofort, Live, ins Facebook oder sonst wo angezeigt und aktualisiert? Hast du Unbekannten als deine „Freunde“ in Facebook? Könnte es sein, dass einer von ihnen (dank deiner Bilder) weiß, dass du teures Zeug zu Hause hast? Könnte er auch nun wissen, wo du gerade bist, und wie lange brauchst bis du wieder zu Hause bist?
Tust du dein Haus oder Wohnung mit Kameras rund um die Uhr überwachen? Fühlst du dich nun sicher? Na dann schau mal hier, ob du aufgelistet bist 😉 Die Profi-Diebe freuen sich auch!
Hast du dir ein USB-Ladegerät gekauft, um deine Akkus über USB zu laden?
Eine wahre Geschichte zum Aufwärmen: In der Weimarer Republik (Deutschland), hatte jemand die Idee, unterschiedlichste Listen von Beamten, Politiker, Offiziere udg. zu erstellen. In eine Liste wurden Namen von Personen (hohe Beamten, Politiker, Offiziere etc.) gesammelt, welche „mädchenhaft“ waren, oder sich für gleichgeschlechtliche Liebe oder gar „Knabenliebe“ interessierten. Diese Liste wurde als die „rosa rote Liste“ genannt. Niemand weiß bis heute, wer der Initiator war, und niemand weiß, warum bzw. wozu? Die gelistete Personen wurden weder verhaftet, noch entlassen, noch kontaktiert. Einige Zeit später gab es die „Weimarer Republik“ nicht mehr. Stattdessen, war der „dritte Reich“ da, mit NSDAP und ein gewisser Adolf an deren Spitze … Die rosa rote Liste (neben andere Listen) war noch da. Und diese wurde von Gestapo und SS „abgearbeitet“. In einer Demokratie, MÜSSEN die Regierungen, Ämter und Organe, sehr präzise und ausführlich begründen 1. Welche Daten, 2. von Wem, und 3. Wozu gesammelt werden? 4. Wann diese Daten unter 5. Welche Voraussetzungen gelöscht werden? Das Ganze sollte natürlich transparent gehalten werden (ausgenommen, wenn es um Schutz der Bevölkerung oder tatsächliche Gefahrenbekämpfung geht, wie z. B. Terror, Kriminalität udg., oder tatsächliche „nationale Interessen“ wie z. B. Kauf von Funkgeräte fürs Militär usw.). Zu diesem Thema empfehle ich den Roman „NSA – Nationales Sicherheits-Amt“ von Andreas ESCHBACH, ISBN 978-3-7857-2625-9
Wie man gesehen hat, siehe BVT, Ibiza, Wirecard, Spionage von NEOS Abgeordnete & Co, heißt eine Demokratie NICHT, dass ALLES so bleibt wie es ist. Regierungen kommen und gehen, die Parteien wechseln Farbe (z. B. Schwarz zum Türkis) und Personal… Wir wissen NIE wer als Nächstes kommt, was er/sie vorhat, und wozu diese(r) fähig ist… „Sie werden sich noch wundern, was alles möglich ist.“ (Norbert Hofer, FPÖ)
Gegenstandsbereich der Software-Ergonomie im eigentlichen Sinne ist der arbeitende Mensch im Kontext (Softwarenutzung an Arbeitsplätzen). Allgemein wird heute die Benutzung von bzw. die Interaktion mit Computern betrachtet. Dies bedeutet die Berücksichtigung (neuro)psychologischer Aspekte beim Entwerfen der Software – wie dies methodisch auch die Ingenieurpsychologie anstrebt –, um eine optimale Mensch-Maschine-Schnittstelle zur Verfügung zu stellen. Dies soll sich in besonders leicht verständlichen funktionalen Einheiten ausdrücken (Bsp. einfache Dialoge bei Systemen mit GUI). Die Entwicklung gebrauchstauglicher Software wird im Rahmen des Usability-Engineering geleistet.
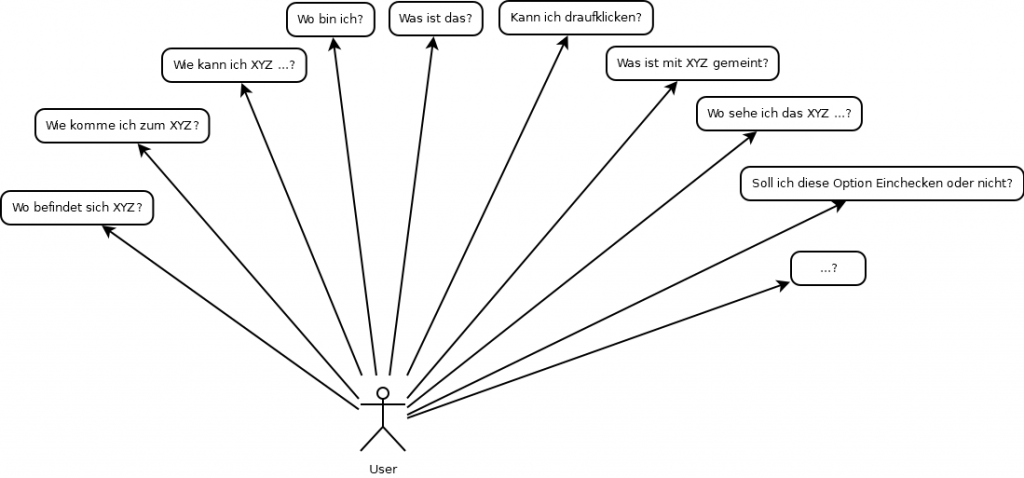
Wer ist der User?
Zu einem System gehören nicht nur Hardware u. Software, sondern auch Anwender (User). Der User unterscheidet sich durch:
Kultur (Sprache, Symbole, Farben),
Bildungs-Niveau,
domänenspezifisches Wissen,
Kontaktfreudigkeit,
Gemütszustand (schlechter Tag, private Probleme, Eile, Stress, Müdigkeit,…)
…
Und einiges mehr.
Es ist wichtig sich bewusst zu sein, dass viele Anwendungs-User in sogenannte Dritte-Welt-Länder, noch nie einen PC mit Maus und Tastatur gehabt, oder damit gearbeitet haben.
Diese besitzen jedoch meist ein Smartphone. Genauso wie das Festnetz-Telefon durch den Einsatz und schnelle Verbreitung von Handys und Handy-Masten übersprungen wurde, wurden in viele Länder die PCs durch Smartphones (und teilweise Tablets) übersprungen.
Somit ist es verständlich das Einigen die Verwendung von Tasten-Kombinationen („Tastatur-Kung-Fu“), Kontext-Menüs, F1 – F12 und Escape-Tasten, sowie Tool-Tipps teilweise oder gar völlig unbekannt sind.
Das sollte auch bei der Einschulung der User sowie schreiben der Manuals berücksichtigt werden.
UX Eigenschaften
Allgemein gebräuchliche Eigenschaften von Usability:
Nützlich: Kann es etwas, das die Leute brauchen?
Erlernbar: Können Leute herausfinden wie es funktioniert?
Einprägsam: Müssen die User es für jeden Gebrauch erneut lernen?
Effektiv: Erledigt es seinen Job?
Effizienz: Tut es das in einem angemessenen Zeitraum und mit zumutbarem Aufwand?
Begehrenswert: Werden die User es mögen?
Reizvoll: Ist der Gebrauch erfreulich oder macht er sogar Spaß?
UX Definition von Steve KRUG:
„Eine Person mit durchschnittlicher (oder sogar unterdurchschnittlicher) Fähigkeit und Erfahrungversteht, wie man das Ding benutzt, um etwas zu erreichen, ohne dass dabei der Aufwand größer als der Nutzen ist.“
KRUGs erstes Gesetz der Usability
Was ist Usability?
Eine Anwendung sollte – so weit, wie es nach menschlichem Ermessen möglich ist – klar sein.
Der User sollte in der Lage sein „es zu kapieren“ – was die Ansichtdarstellt und was man mit ihr machen kann –, ohne lange überlegen zu müssen.
Wie viel Klarheit?
Wenn der User sich denkt: „Oh, das ist ja einMenü → ich kann es anklicken.“ „Ah ja, da istder Button zum Speichern.“ „Da ist jadas Bestellformular →was ich wollte.“
Was ist Unklarheit?
Wenn der User eine Ansicht (gilt auch für Sektionen und Steuer-Elemente) ansieht, die ihn zum Überlegen zwingt, sind alle Gedankenblasen über seinem Kopf voller Fragezeichen.
Grundprinzip von UX: Eliminierung der Fragezeichen.
Mann kann nicht alles offensichtlich machen! Aber das Ziel sollte sein, dass jede Ansicht (gilt auch für Sektionen und Steuer-Elemente) offensichtlich ist, damit der Durchschnittsanwender beim Ansehen weiß, worum es geht und wie man sie nutzt. Er kapiert es, ohne darüber nachzudenken.
Warum müssen die Fragezeichen eliminiert werden?
Wenn wir (User) die Anwendung benutzen, trägt jedes Fragezeichen zu unserer kognitiven Belastung bei und lenkt unsere Aufmerksamkeit von der momentanen Aufgabe ab. Die Ablenkungen mögen nur gering sein, aber sie addieren sich, und ein Tropfen bringt das Fass zum Überlaufen.
Grundregel:
Die Leute mögen es nicht, darüber nachzugrübeln, wie man etwas macht (Wer liest gerne die Manuals zuerst durch? „TL;DR“* in Kommentaren, Chats und Blogs,… Anm. d. A.). Die Tatsache, dass die Ersteller der Anwendung sich keine große Mühe gaben, die Dinge offensichtlich – und einfach – zu gestalten, kann unser Vertrauen in die Anwendung und ihre Herausgeberuntergraben.
*) Abkürzung des Internet-Kunstbegriffs „Too Long; Didn’t Read!“
Beispiel für Dinge die den User zum Nachdenken zwingen:
Niedliche oder clevere Namen, falsche oder nicht gebräuchliche Begriffe
firmenspezifische oder fremdartige technische Bezeichnungen
nicht offensichtlich anklickbare Buttons, Drop-Down-Listen, Listen-Elemente, Links,…
„Datum von“, „Datum bis“: ist das inklusive oder exklusive heute/gestern/…?
Ich habe die Uhrzeit in Datum-UI eingegeben, aber die Uhrzeit-UI zeigt immer noch XYZ an. Was habe ich falsch gemacht?
Muss ich jetzt die Anwendung Neustarten (um die Einstellungen anzuwenden) oder nicht?
Wurde die Aktion XYZ durchgeführt oder nicht?
Muss ich auf „Speichern“ oder „Übernehmen“ klicken?
Muss ich auf „Cancel“ oder „Close“ klicken? Was ist der Unterschied?
Ich klicke auf dem Button „Kopieren“ aber es tut Nichts! Warum? Habe ich was falsch gemacht?
Was ist „Initialisieren“?
Uuups! Fehlermeldung „Object XYZ throw NullReferenceException….“. Was heißt das? Hab ich was falsch gemacht? Kann ich es nochmal probieren? Muss ich jemandem davon benachrichtigen? Kann ich weiter damit arbeiten oder muss ich die Anwendung Neustarten? An welche Support-E-Mail-Adresse muss ich schreiben? Welche Hotline-Nummer muss ich wählen? Was soll ich dem Support-/Hotline-/Techniker sagen?
…
Also warum UX?
Die Ansichten offensichtlich zu gestalten, ist wie die gute Beleuchtung in einem Geschäft: Alles erscheint einfach besser. Die Nutzung einer Anwendung, die uns nicht zum Nachdenken über Unwichtiges zwingt, fühlt sich mühelos an, wogegen das Kopfzerbrechen über Dinge, die uns nichts bedeuten, Energie, Nerven, Enthusiasmus und Zeit raubt.
Die meisten User haben weit weniger Zeit mit dem Betrachten der von uns designten Ansichten/Fenster/Manuals, als uns lieb ist.
Ergebnis: Klarheit oder zumindest selbsterklärend.
Die User haben ein Ziel. Sie wissen, dass sie nicht alles lesen müssen. Sie sind gut darin Dinge zu überfliegen. Darin sind sie geübt (in der Sprache der Neurologen: konditioniert).
Deswegen: die User wählen in der Realität die erste annehmbare Option (Satisficing1), also ausreichend befriedigend. Zur Erinnerung: Gemütszustand der User!
Die User befassen sich nicht damit, wie etwas funktioniert, sondern wursteln sich durch (Beispiel: Manuals/Bedienungs-Anleitungen).
Woher kommt das?
Den meisten von uns ist es egal, ob wir die Funktionsweise verstehen, solange wir etwas benutzen können
Wenn wir etwas finden, das funktioniert, bleiben wir dabei. Wir neigen dazu keinen besseren Weg zu suchen.
Wenn die User eine Ansicht kapieren ist die Wahrscheinlichkeit viel größer, dass:
sie das Gesuchte finden (was gut für User und Hersteller ist)
sie die gesamte Anwendung verstehen
sie sich schlauer fühlen und haben mehr das Gefühl der Kontrolle
Ein paar Punkte zum Überfliegen von Design und Layout:
Vorteile von Konventionen nutzen
Effektive visuelle Hierarchien erzeugen
Einteilung der Ansichten in klar definierte Bereiche
Keine Zweifel darüber lassen, was anklickbar ist
Minimierung des „Rauschens“
Formatierung der Inhalt, damit er sich leichter überfliegen lässt
Wichtigste über Navigation:
Wo bin ich (da)? und
Wo möchte ich hin (dort)? Daraus resultiert
Wie komme ich dorthin (Strecke/Weg, Route)?
1 Satisficing ist ein Kunstbegriff bestehend aus: Satisfaction + Sufficient
Vorgehensweise bei Projekt-Beginn
UML Use Case Diagramm:
welche Akteure (User) werden
welche Funktionen (Was)
wann und
wo aufrufen/anwenden
UML Zustands Diagramm:
In welcher/welches Ansicht/Fenster/Menüpunkt beginnt das Ganze?
Was sind die nächsten Schritte?
Durch welche Daten/Zustände werden welche UI-Elemente aktiviert/deaktiviert?
Was sind illegale Eingaben/Aktionen? Wie soll darauf reagiert werden?
Was wenn bei der Aktion XYZ (Laden, Speichern,…) ein Fehler auftritt?
Muss der User alle bisherige Angaben (z. B. in Formular) nochmal eingeben? Zumutbar?
Muss der User die Anwendung Neustarten? Oder Admin benachrichtigen bzw. Hotline anrufen?
…
Wie kann dem User am Ende der Aktions-Kette signalisiert werden, dass alles gut gegangen oder etwas Fehlgeschlagen ist?
Sind Zusatz-Informationen notwendig?
Kann dem User Vorschläge unterbreitet werden, was er/sie tun kann damit es funktioniert?
Wo bzw. in welche Dokumentation oder Manual kann der User mehr darüber lesen?
…
Wireframes / Mockups erstellen!
Reviews!
Test von Wireframes / Mockups auf dem Papier…
Verbessern und nochmal Testen!
Erst, wenn Tests erfolgreich sind, wird mit der GUI-Entwicklung begonnen
Jetzt kann die GUI qualitativ auf UX getestet werden (periodisch/zyklisch!)
Falls in neue Anwendungs-Version neue Funktionen hinzugekommen sind (Menüs, Menü-Punkte, Buttons, Listen udg.) → auf UX nochmal Testen!
Standards & Konventionen
Die Standards und Konventionen sind nicht aus Langweile oder einfach aus der Luft gegriffen.
Irgendjemand hatte die Idee zuerst. Wenn die Idee gut war und sich als nützlich erwies, wurde es mehr und mehr kopiert und verbessert. Irgendwann haben die Leute das Ding öftersüberallgesehen und wissen worum es sich handelt und wie es funktioniert. Sie müssen nicht nachdenken (in der Sprache der Neurologen und Pädagogen: Model-Lernen, oder einfach Kopieren).
Die Aufgabe von Layout und Design ist nicht, das Rad neu zu erfinden!
Selten führt das Neuerfinden des Rades zu einem revolutionärem, neuen Fahrgerät. Aber oft geht dabei einfach nur Zeit drauf.
Wenn man, eine existierende Konvention nicht nutzen kann/will, muss man sicher sein, dass der Ersatzvorschlag:
Offensichtlich und
selbsterklärend ist und
kein Anlernen benötigt oder
es einen so extrem großen Wertzuwachs bedeutet, dass etwas Anlernzeit gerechtfertigt ist.
Klarheit übertrumpft Konsistenz!
Was bringt es, wenn etwas konsistentunverständlich ist?
Beispiele für Konventionen:
Form und Farben:
Egal wo Sie mit dem Auto fahren, ob in: Iran, Chile, Mongolei, Mexiko, Marokko, Québec, Thailand oder China,… die wichtigsten und notwendigsten Verkehrszeichen sehen alle gleich aus (bis auf die Schrift).
Positionierung der Funktionen:
Egal wer das Auto gebaut hat, egal ob manuelle oder automatische Schaltung, und egal welches Model das Auto ist: Die Positionen und Funktionen der Pedalen sind eindeutig. Man muss nicht nachdenken.
Abgerundete Ecken bei Schalter und Tastatur:
Beim Überfliegen einer Ansicht suchen wir nach Hinweisen, die Dinge als anklickbar kennzeichnen.
Entstandene (Ideen) Standards:
Signal-Stärke und Rauschen (= Lärm)
Beispiel fürs Rauschen/Lärm:
Zu viele/lange Texte (Absätze kurz halten)
viele Ausrufezeichen
verschiedene Schriften und bunte Farben
automatische Animationen (hineinfahren/hinausfahren von mehreren Steuer-Elementen, wenn mit der Maus über die Ansicht gefahren wird)
Keine oder wenige Listen mit Gliederungspunkten (Manuals, Fehler-Behebungs-Vorschläge,…)
Nicht hervorgehobene Schlüsselbegriffe (= Signal)
Unordnung:
Jede Ansicht ist anders aufgeteilt
Durch zu große Dimensionierung verliert ein Steuer-Element seine Wieder-Erkennbarkeit
Dinge mit gleicher Funktion (Status-Texte, Labels, Buttons,…) haben unterschiedliche Größe, Position, Form, Schriftart oder Farbe (bei mindestens einer Ansicht)
Neue Schriften oder Farben auf mindestens einer Ansicht
Nicht genug Abstand
Nicht eindeutig Zuordenbar
Nicht betitelt oder beschriftet (Was kann ich in dieser Drop-Down-Liste auswählen?)
Unnötige Umrandung(en) oder Rahmen suggerieren das Element (z. B. Button oder Combo-Box) ist etwas Eigenes und hat nichts mit den UI Elementen darunter/darüber zu tun
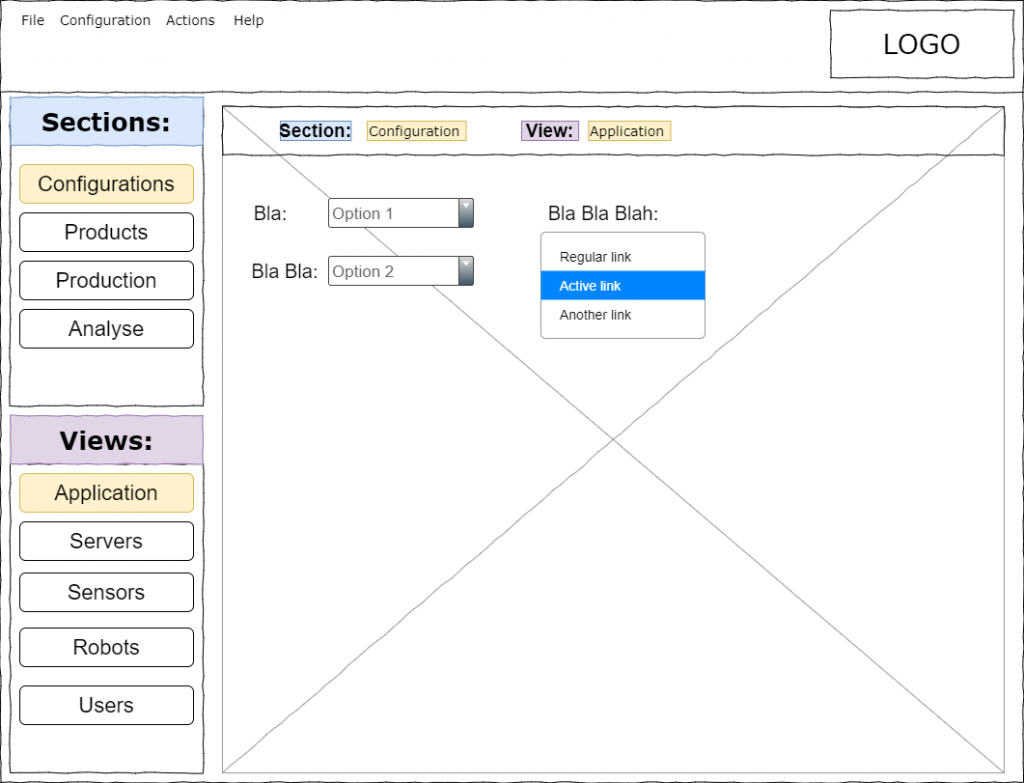
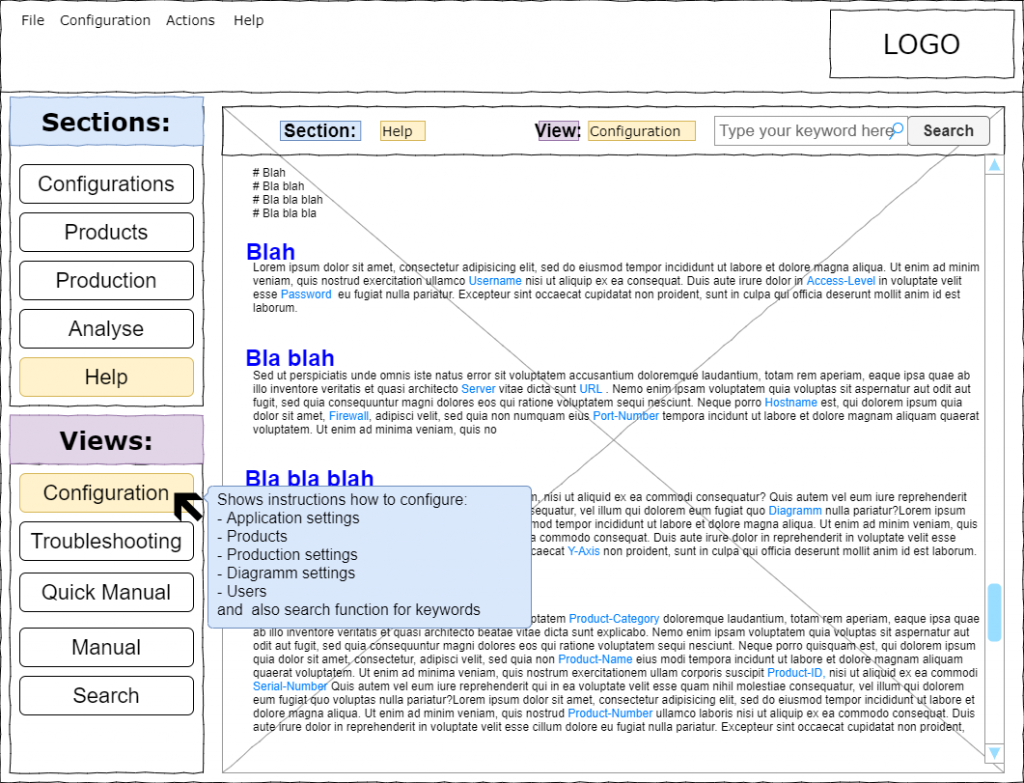
Erstes Beispiel für UX-Test: Wo bin ich?
Schichtwechsel! User Anton geht. User Bernd kommt.
Was sieht er?
Muss Bernd nachdenken/grübeln welche Ansicht er sieht?
Vor den UX Verbesserungen
Nach den UX Verbesserungen
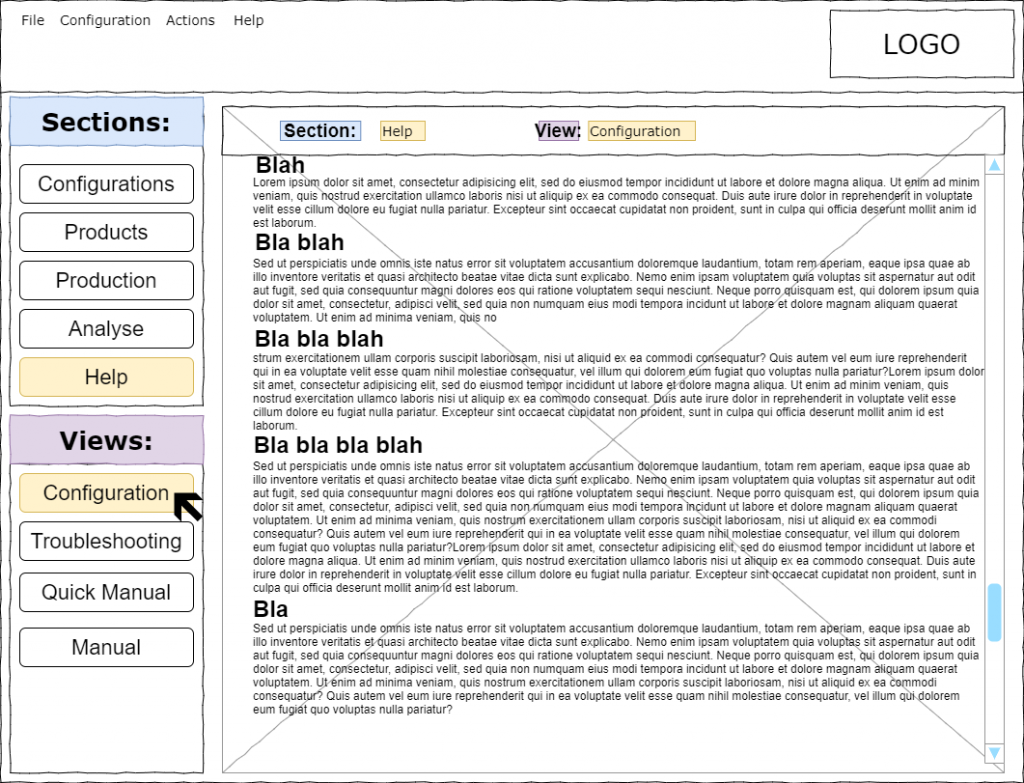
Zweites Beispiel für UX-Test: Wo finde ich XYZ?
Die Produktion steht! Der für die Produktion verantwortlicher User (Maschinen-/Hallen-Chef oder Produktions-Leiter) eilt gestresst und genervt zum Bildschirm. Er hat die Fehler-Meldung „Unbekannte Produkt-Nummer!“ bekommen und nun sucht er (ungeduldig) nach Anweisungen für die Konfiguration.
Er versucht möglichst schnell (durch Überfliegen) die interessanteSektion zu finden.
Muss er alles durchlesen?
Muss er viel nachdenke/grübeln?
Warum?
Was ist hier das Rauschen/Lärm?
Wo sind die Signale?
Vor den UX Verbesserungen
Nach den UX Verbesserungen
Maximale Anzahl der Klicks für die Navigation oder Erledigung einer Aufgabe:
Die Anzahl ist relativ egal, solange diese Klicks unüberlegt getätigt werden können.
Als Richtlinie: ca. max. 3 Klicks. Warum sollte der User N Mal klicken um zu XYZ zu kommen? Warum sollte der User N Ansichten/Views oder gar andere Stellen/Fenster/Dokumente (User Manual, PDF) suchen um alle benötigte Informationen zusammenzubekommen? Kann man den XYZ klickbar machen, damit der User mit nur einem Klick darauf, sofort das Dokument öffnen/speichern/sehen kann?
Einige Wahrheiten über UX-Tests
Wenn man eine großartige Anwendung haben will, muss man es testen.
Einen einzigen User testen ist auf jeden Fall besser als gar keine Tests.
Einen User zu Beginn des Projekts testen zu lassen, ist besser als 50 gegen Ende.
Was wird getestet?
Qualitative UX-Eigenschaften:
Klarheit
Offensichtlichkeit
Wiedererkennbarkeit
Einhaltung von Konventionen/Standards
Navigation
Wie lange der User, für die Erledigung bestimmter Aufgaben benötigt hatte
Woran der User, während der Erledigung der Aufgaben gegrübelt/gedacht, bzw. welche Fragen er sich gestellt hat
Welche Outputs nach dem UX-Test gibt es?
Video
Analyse-Bericht mit:
Liste von erledigte oder nicht-erledigte Aufgaben (wenn nicht erledigt: der Grund)
Liste der gröbsten Mängel (max. 10)
Verbesserungsvorschläge
Wie wird entschieden welche der Mängel sofort zu beheben sind?
Nach Return-on-Investment (RoI):
Es wird eine engere Auswahl-Liste erstellt. Der Zweck der Auswertung ist, die schwerwiegendsten Probleme zu identifizieren, damit diese zuerst behoben werden.
Vorgehensweise:
Verbesserungen die leicht und schnell umgesetzt werden können zuerst.
Verbesserungen die etwas mehr Zeit benötigen fürs Später einplanen.
Falls die Anwendung (das Projekt) kurz vor dem Liefer-Termin steht und die Behebung eines der Mängel inklusive dessen UX-Test nicht zu schaffen ist, dann für nächste Roll-Out planen.
Re-Design ausschließlich, wenn das Projekt noch in Anfangs-/Entwicklungs-Phase befindet, sonst nie (diese müssen leider dann akzeptiert/hingenommen werden!).
Vorschläge für mehr Effizienz, Zeit- und Kosten-Ersparnis bei den GUI-/Anwendungs-Projekten:
Fürs Layout (Ausrichtung, Positionierung/Platzierung, Abstände, Dimensionen) ein möglichst einfaches Konzept/Model ausarbeiten (Wireframes) und das Layout minimal halten. Später können diese leicht und schnell hinzugefügt, präzisiert, angepasst und detaillierter gestalten werden, und zwar einmalig.
Design (Schrift-Arten, Farben, Symbole udg.) weglassen, oder sehr einfach und „global“ änderbar halten. Global bedeutet wie z. B. die einmalige Definition von Hintergrund-Farbe oder Schrift-Größe für Buttons (Schaltflächen) unter einzigartigen Namen in einer globalen Stil-Datei („styles.xaml“) wie z. B.:
Button-Background-Color = Light-Gray
Button-Font-Size = 14 pixels
Alle Buttons nutzen dann die in Stil-Datei definierte und benannte Werte.
Dadurch kann man durch das Anpassen/Ändern des Wertes (z. B. für die Schrift-Größe) an einer einzigen Stelle (in „styles.xaml“), alle Buttons einheitlich anpassen. Funktioniert extrem leicht und schnell. RETURN ON INVESTMENT!
Kurzes Beispiel für einen UX-Test-Bericht mit Liste der Mängel sowie deren Verbesserungsvorschläge:
Angemeldet als Admin, gezeigt wird die Ansicht Produktion
Weiß der User welche Ansicht er vor sich hat?
Nein! Weil…
2.
Wie 1.
Der User soll neue Produktion mit dem Namen „P123“ anlegen.
Ja
3.
Gezeigt wird die Ansicht Produktions-Klassen
Umbenennen der „P123“ in „Q456“
Nein! Weil…
4.
Wie 2.
Der Wert von System-Einstellung XYZ soll auf 1,23 geändert u. gespeichert werden
Ja
…
…
…
…
Worüber der User gegrübelt hat:
Bei Aufgabe 1 hat er die Drop-Down-Liste XYZ nicht als solches erkannt und hat danach gesucht.
Bei Aufgabe 3 könnte der User nicht herausfinden wie der Name der P-Klasse geändert werden kann.
Während der Aufgabe N wurde eine Fehler-Meldung Error-0815 ausgelöst. Der User war sich nicht sicher, ob er weiterarbeiten kann oder die Anwendung neu-starten muss.
…
Verbesserungsvorschläge:
Die Drop-Down-Liste XYZ beschriften (mit einem Label über oder Links davon) und ein Tooltip (Balloon-Text) hinzufügen mit dem Text „Hier können Sie XYZ auswählen“.
Der Text für die Fehler-Meldung Error-0815 ändern, damit der User weiß, dass er die Anwendung neu-starten muss.
Bei Pareto-Prinzip geht es vereinfacht formuliert darum: das Verhältnis der Dinge, mit 20 % und 80 %, möglichst einfach zu beschreiben. Dabei gibt es nur die zwei Prozentzahlen: 20 und 80 (sonst nichts). Z. B.: 20 % Code von einer Software enthält die 80 % der Hauptfunktionen (SW Core), oder 20 % der Funktionen werden 80 % der Zeit aufgerufen, die Benutzer sehen in 80 % der Fälle 20 % der Fehler-Dialoge/-Meldungen etc. etc. usw. usf.
Bei Job-Interviews, stelle ich immer die Frage nach dem Prozentsatz meiner Tätigkeit in der Firma (welche einen Software-Entwickler für .NET/C# sucht).
Was ich erwarte: 20 % der Zeit … oder 80 % der Zeit. Ich glaube ja auch daran, dass ein Bäcker 80 % der Zeit Brot bäckt, ein Metzger 80 % der Zeit Fleisch schneidet, ein Automechaniker 80 % der Zeit Autos repariert…
Eine kurze Geschichte übers Kommentieren und Kommentare
Ich wünsche die Kollegen beim Neuschreiben des Codes in C, C++, C#, Java,… oder WasAuchImmer++ viel Geduld, Kraft und Nervenstärke.
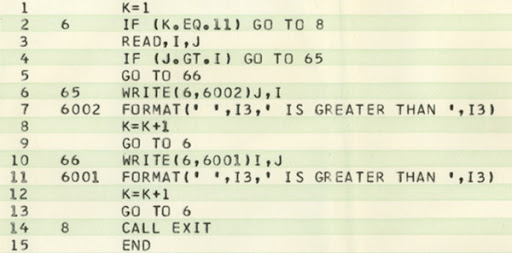
Wenn Kommentare genauso kryptisch sind, wie der Code
Was machen diese 15 Zeilen?
Man kann die Kommentare übersetzen und erahnen was diese Zeilen tun
Back to the Future… Kommentare sind wichtige Informationen für die Zukunft. Kommentare sind wichtige Informationen aus der Vergangenheit. Kommentare sind Notizen/Erklärungs-Ergänzungen für sich selbst, Kolleginnen und die Nachwelt (neue Kolleginnen, wenn man nicht mehr in der Firma (oder am Leben) ist).
Ich lese immer wieder Sätze mit Rufzeichen am Ende, wie „Jede Code-Zeile muss kommentiert werden!“, oder „Pro Methode, mindestens drei Zeilen Kommentare!“ usw.
An der Uni hieß es „Alles muss kommentiert werden!“.
Dann hieß es (eine Show namens „Linux Nerds vs. Geeks“ glaube ich) „Wenn man schönen/guten Code schreibt, braucht man keine Kommentare“ (sagte der Linux Grafik-Programmierer-Guru!).
Irgendwann sagte ein ehemaliger Kollege „Kommentare verwirren nur“ und dass „Nur Amateure und Doofis kommentieren“ …
Mein derzeitiger Standpunkt ist:
Extrem ist und bleibt extrem. Daher entscheide ich mich für die goldene Mitte.
Bevor ich Kommentiere stelle ich mir folgende Fragen:
Muss ich Kommentieren?
Reicht der Name nicht?
Ist der Name gut gewählt?
Sollte ich nicht lieber den Namen ändern?
Wie groß ist der Informationsgehalt des Kommentars?
Bietet der Kommentar eine zusätzliche oder ergänzende Information, die sonst nicht (oder sehr schwer) zu lesen/sehen/wissen (Code) wäre?
Erleichtert/Verkürzt der Kommentar die Suche/Recherche oder das Verständnis des Algorithmus?
Lässt der Kommentar Raum für falsche Interpretationen zu?
Hilft der Kommentar Fehler zu minimieren, oder verursacht es mehr Fehler durch Missverständnis?
Nehmen wir den (C#) Code von Unten als Beispiel und stellen wir uns gemeinsam pro Kommentar die obigen neun Fragen unter Punkt zwei:
public class Person
{
/// <summary>
/// Gets/Sets the ID of Person.
/// </summary>
public int ID { get; set; }
/// <summary>
/// Gets/Sets the first/given name of Person.
/// </summary>
public string FirstName { get; set; }
/// <summary>
/// Gets/Sets the last/second name of Person.
/// </summary>
public string LastName { get; set; }
/// <summary>
/// Gets/Sets the day of birth of Person.
/// </summary>
public DateTime BirthDay { get; set; }
/// <summary>
/// Returns the whole/full name beginning with FirstName then LastName in uppercase.
/// </summary>
/// <returns></returns>
public string GetName()
{
// todo: check!
return $"{FirstName} {LastName.ToUpper()}"; // NG! PGH 2021-07-05 V0.8.15
}
}
Die Property-Namen sagen eindeutig, unmissverständlich und klar aus, was sie beinhalten, und deren Kommentare haben/bringen keine zusätzliche/ergänzende Informationen… Also ⇒ Weg damit!
Der Kommentar von der Methode „GetName“ möchte, und MUSS, etwas erklären, was der Name leider nicht tut. Zusätzlich verwirrt dieser Kommentar. Innerhalb der Methode „GetName“ steht ein „todo“ Kommentar, was kein Mensch entschlüsseln kann: „check!“ Check-What? Was soll gecheckt/überprüft werden FirstName, LastName oder Return-Value (string)? Am Ende der Return-Zeile steht wieder kryptische Buchstaben-Suppe:
„NG!“ steht für…??? No Guns? No Game? Next Generation? Not Good? No Grade? Network Grid?
Danach steht „PGH„, meine Initialien plus Datum und anscheinend eine Version:
Gibt es für sowas Versionsverwaltungs-Systemen (CVS, SVN und GIT). Dort kann man all das lesen, von Anbeginn der Zeit (Projekt-Geburt) bis zum letzten Commit: Wer (Name, E-Mail-Adresse) hat, wann(Datum + Uhrzeit mit Millisekunden) was (Verzeichnis, Datei, Zeile) in welche Version geändert (gelöscht, hinzugefügt, umbenannt, ergänzt, entfernt,…) hat.
Was sollen die Kolleginnen damit anfangen? Mehrwert? Informationsgehalt?
Das Ganze könnte man auch so schreiben:
public class Person
{
public int ID { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
/// <summary>
/// Returns full name, like: "John DOE", "Alice BOYLE".
/// </summary>
/// <returns></returns>
public string GetFullName()
{
return $"{FirstName} {LastName?.ToUpper()}";
}
}
Ich habe diese Beispiele nicht aus der Luft gegriffen. Ähnliche, und teilweise noch schlimmere Fälle aus der Praxis (was mir unter die Augen gekommen sind) werde ich noch hinzufügen. Entweder hier oder im neuen Beitrag.
Der Kunde zahlt fürs Code-Schreiben und nicht fürs Code-Lesen!
In einer Firma, wo alle Software-Entwickler und IT’ler Deutschsprachige waren, hat der Inhaber & CEO uns befohlen alle Kommentare (nur Kommentare) auf Deutsch zu schreiben. Ein Jahr später, nachdem das Projekt im Verzug war und die Entwicklung des Software-Systems nicht schnell genug vorangegangen war, wurden drei neue Software-Entwickler aus Spanien eingestellt. Die neuen Kollegen waren alle sehr gute Software-Entwickler und beherrschten souverän ihr Fach, jedoch verstanden kein Wort Deutsch. Danach wurden noch mindestens fünf weitere Software-Entwickler, ebenfalls aus Spanien, eingestellt… Nun hatten wir alle Hände voll zu tun. Wir drei Deutschsprachigen müssten alle Kommentare nun auf Englisch übersetzen und ersetzen, anstatt unsere Aufgaben nachzugehen.
In eine andere Firma, hatte ich das „Vergnügen“ Code auf Denglisch zu lesen. Manche Namen waren Deutsch, manche waren Englisch, und der Rest eine beliebige Mischung aus Deutsch und Englisch. Dass alle Programm-Elemente (Interfaces, Klassen, Delegates, Events, Methoden, Properties etc.) in Microsoft .NET Frameworks auf US-Englisch waren, ist natürlich trivial…
Das Lesen der Code war extrem schwierig und eine Herausforderung an/für sich. Beispiel für Variable-Namen: messValue, measWert, measValue, messWert (diese Namen standen für: measured value, bzw. gemessener Wert). Auch wenn man alle Namen auf Deutsch schreibt, die Hälfte von Code ist und bleibt auf Englisch, da die Schlüsselwörter und alles Andere in MS .NET Frameworks in US-Englisch ist, wie: string.IsNullOrEmpty(…), PropertyChanged, File.Exist(…), using(var x = new MemoryStream(…)), usw. usf.
Deswegen behaupte ich: Es kann kein Code auf „Deutsch“ geschrieben werden, wenn man das versucht, dann entsteht immer ein Code auf „Denglisch“. Man stelle sich nur vor, jemand würde Denglisch schreiben oder reden: „I war very froh to sehen you nochmal“.
Ich verwende gerne US englische Namen (Color statt Colour, Synchronize statt Synchronise, usw.). Somit bleibt alles einheitlich, unmissverständlich, eindeutig, klar und der Lese-Fluss bleibt sehr flüssig.
Denglisch kostet mehr Zeit, mehr Zeit zum Lesen und mehr Zeit zum Verstehen. Je öfter der Code von je mehr Kollegen (wieder)gelesen wird, desto mehr Zeit wird verschwendet! Zeit ist Geld. Somit verursacht Code auf Denglisch unnötige zusätzliche Kosten.
Der Kunde zahlt fürs Code-Schreiben und nicht fürs Code-Lesen!
Event-Handling-Methoden beginnen mit „On“ plus Event-Name, und können -wenn passend- mit „ed“ enden, also: „On<EventName>ed„, wie: OnCommandInvoked, OnValueChanged, OnSafeModeActivationChanged, OnStreamOpening, OnStreamOpened, OnStreamClosing, OnStreamClosed, OnUserLoggedIn, OnUserLoggedOut, OnMachineReplaced, OnErrorOccured,…
Funktionen/Methode, die etwas Berechnen und eine Zahl zurückgeben beginnen mit „Calc“ oder „Calculate“ (und NIEMALS mit „Get“!), wie: CalculateCircleSurface(…), CalculateStandardDeviation(…) oder kurz: CalcStdDeviation(…)
Methoden die asynchron laufen enden mit „Async“, wie: CalcStdDeviationAsync(IEnumerable pTooManyNumbers),…
Properties die Exception werfen können, werden NICHT als Properties, sondern mit „Get…()“ und „Set…()“ implementiert (so wie es die C# Sprach-Designer Anders Hejlsberg, Bill Wagner & Co vorgesehen haben), denn ein Property sollte niemals Exceptions werfen, schon gar nicht der Getter. Ausgenommen sind die Indexer (wegen IndexOutOfRangeException).
„Get…“ Methoden welche Exceptions abfangen und behandeln enden mit:
„OrNull“ wenn bei Exception NULL zurückgeliefert wird
„OrDefault“ wenn bei Exception Default-Wert (z. B. default(int)) zurückgeliefert wird
Member-Variablen beginnen mit „m“ oder „m_„, wie: mFirstName oder m_FirstName
Parameter beginnen mit „p“ wie: CalcRectSurface(int pWidth, int pHeight), SetTopLeft(int pX, int pY),…
Konstanten werden GROSS_GESCHRIEBEN: DEFAULT_VALUE, MAX_VALUE,…
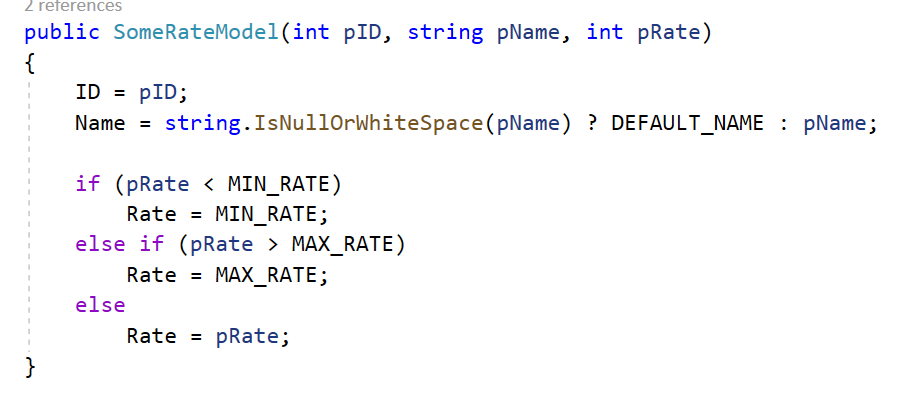
Der Beispiel-Code unten erfüllt die oben erwähnten Regeln. Versuche herauszufinden: Welcher Name ist ein Property, welcher ein Parameter, welcher eine Member-Variable und welcher eine Konstante:
Konstanten, Parameter, Properties etc. sind eindeutig zu erkennen
Der Kunde zahlt fürs Code-Schreiben und nicht fürs Code-Lesen!
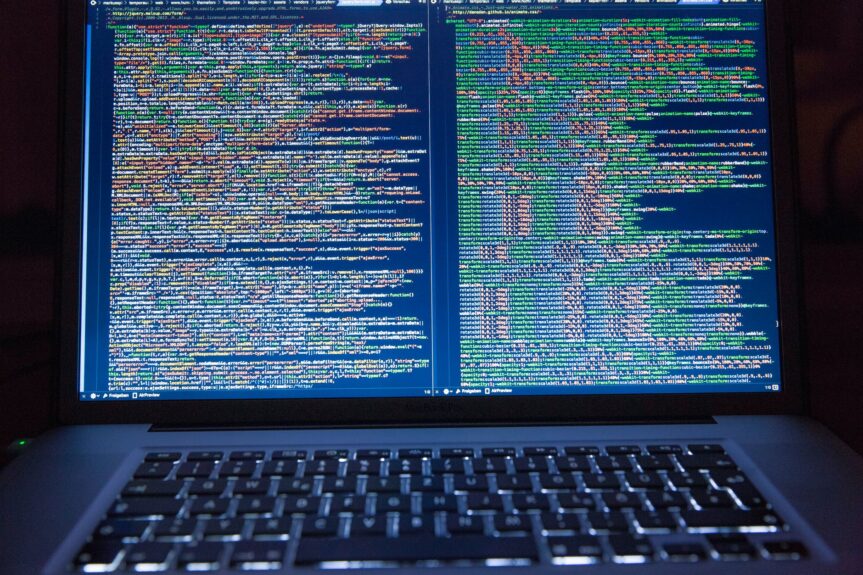
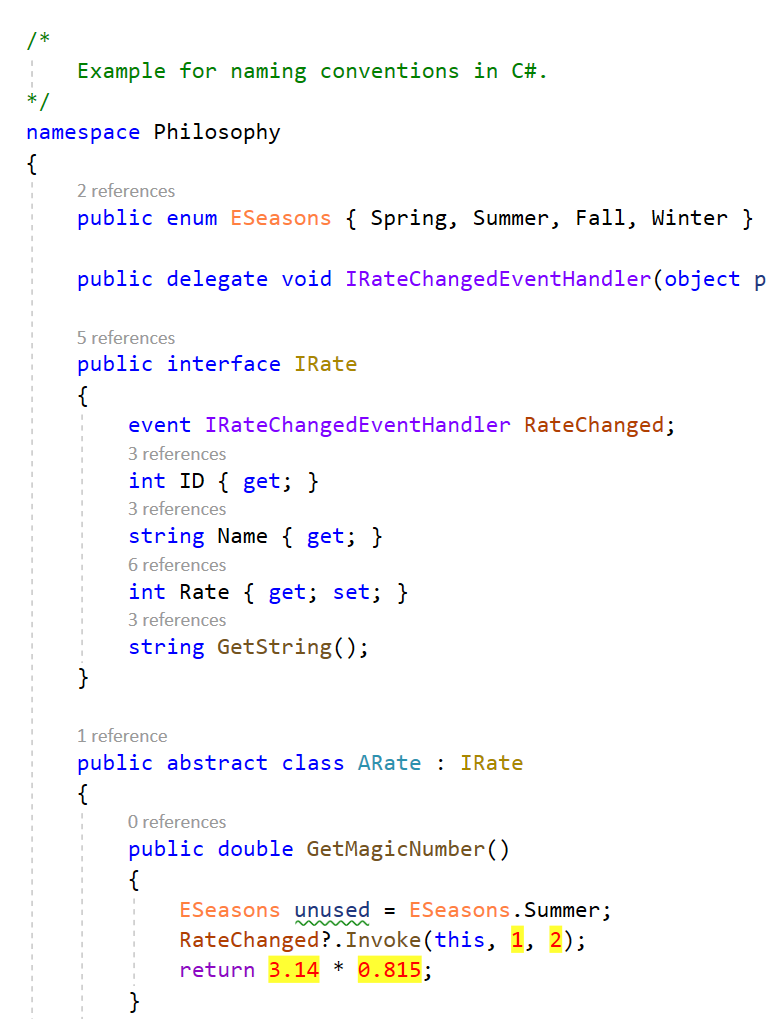
Die Zeiten wo alles in Grün auf schwarzem Hintergrund stand (Borland Turbo Pascal/CPP Editor udg.) sind lange vorbei. IDEs wie Visual Studio & Co bieten von Haus aus Syntax Highlighting. Die Einfärbung der Schlüsselwörter, Kommentare, Typen etc. machen das Lesen von Code leichter, flüssiger und angenehmer. Für mich jedoch reichte die Einfärbung für C# in Visual Studio nicht. Ich möchte schnell auf einem Blick, ohne zu lesen erkennen, ob bei ein Programm-Element (in C#) es sich um ein Interface, Klasse, Enum, Delegate, Event oder „Magic Number“ handelt. Dazu habe ich für Interfaces, Delegates, Enums und Zahlen eigene Farben zugewiesen (siehe Bild 1!)
Kommentare sehe ich deutlicher (Dunkelgrün statt Standard Leichtgrau)
Enums sind eindeutig sofort zu erkennen (Orange)
Delegates sind ebenfalls eindeutig zu erkennen (Violett)
Interfaces haben eine andere Farbe als (abstrakte) Klassen oder Structs
Events sind Braun
„Magic Numbers“ haben bei mir keine Chance, da sie sofort erkannt werden 😉
Unterscheidung zwischen Enums und Konstanten sind ebenfalls leichter
Bild 1
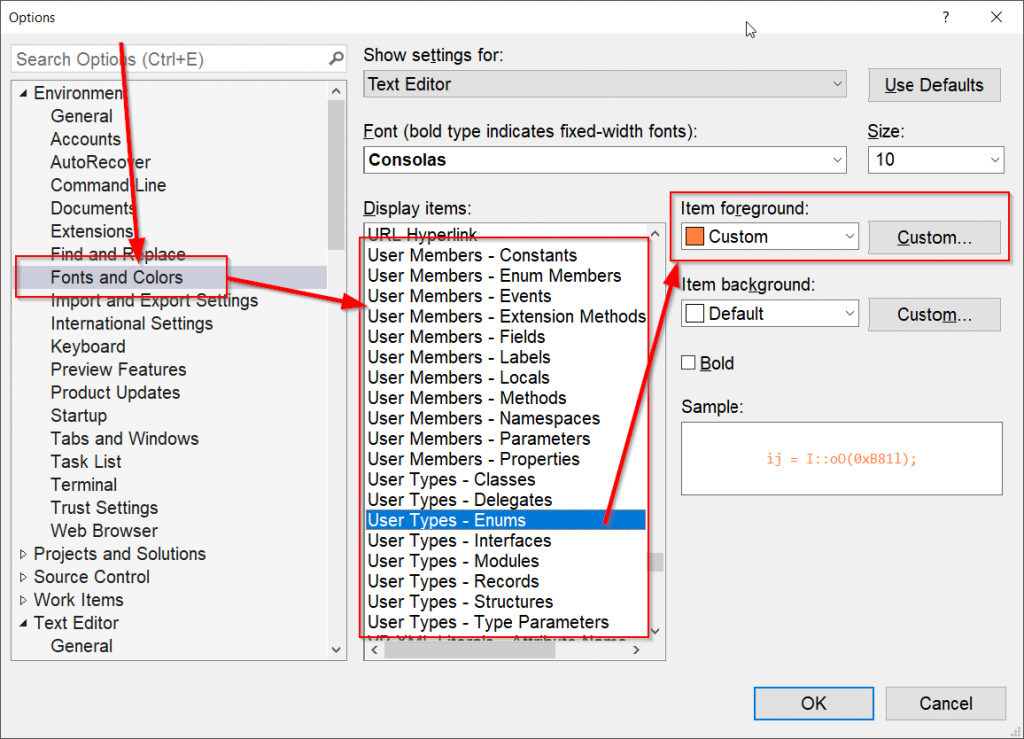
So gelangt man zu Farben- und Font-Style von Programm-Elementen in Visual Studio (Bild 2):
Seit Visual Studio 2012 wird „Dark Theme“ (Tools → Options → Environment → General → Color Theme) als Standard verwendet. Das hat den Vorteil, dass die Augen mit weniger Licht belastet werden. Jedoch ist es so, dass „Dark Theme“ sich eher für Grafik, 3D und Animations-Editoren eignet, um die Tool-Leisten weg- und das Bild/Modell (Bild, 3D Objekt udg.) in die Mitte zu rücken (dadurch wird automatisch die Fokussierung auf das Bild/Modell geleitet). Für das Lesen und Schreiben von Text (hier Code) ist es eher ungeeignet (laut Augen-Mediziner). Die Augen müssen sich mühsam auf die hellen Buchstaben fokussieren. Vor allem, wenn durch große Fenster, was heutzutage modern ist, das Sonnenlicht auf dem Bildschirm fällt, oder über helle Flächen auf dem Bildschirm reflektiert wird.
Deshalb probiert es selbst aus! Nachdem ich eine Zeit lang extreme Augen- und Kopfschmerzen hatte, und deshalb zum Augenarzt gehen müsste, bin ich auf dem „Light“ Theme umgestiegen. Das reflektierte Sonnenlicht ist seitdem kein Thema (für mich) mehr. Für detaillierte Informationen, siehe hier und hier! Anmerkung: bei OLED und AMOLED Bildschirm, wird oft Dark Theme zwecks Energiesparen eingesetzt.
Der Kunde zahlt fürs Code-Schreiben und nicht fürs Code-Lesen!
Wenn wir ein Buch, eine Zeitung, ein Magazin oder nur ein A4 Blatt lesen, dann halten wir es so, dass die obere Kante etwas weiter hinten ist, und die untere Kante näher zu uns ist. Beim Lesen nach Unten bewegen sich die Augen weiter nach Innen (zu Nase), und beim Lesen nach Oben bewegen sich die Augen auseinander. Wir halten ein Buch niemals parallel vor unserem Kopf, wir neigen den Kopf etwas nach Unten. Kurze Zeilen unter einander machen den Lese-Fluss leichter. Lange Zeilen stören den Lese-Fluss, da die Augen sich auch horizontal bewegen müssen. Bei sehr lange Zeilen muss sich sogar noch der Kopf sich horizontal drehen. Je mehr Augenmuskeln beansprucht werden, desto früher wird man Müde (Kopf-Schmerzen). Man kann sich schlecht konzentrieren/fokussieren. Deshalb ist das Lesen während einer Zug- oder Busfahrt (für längere Zeit) nicht ratsam.
Das gilt auch für Code lesen. Deshalb sollte darauf geachtet werden das beim Code schreiben, die Zeilen möglichst kurz und untereinander stehen.
// Hindert den Lesefluss
if ((a > B && C < D) && !(x == y || y != z)) dataCommunicator.SomeMethod(a, b, c, true);
// Noch mehr Code...
// Macht den Lesefluss leichter
if ((a > B && C < D) && !(x == y || y != z))
dataCommunicator.SomeMethod(a, b, c, true);
// Noch mehr Code...
Nomen est omen Namen spielen beim Schreiben von Code eine essenzielle Rolle. Gut gewählte Namen können viele Grübeleien, Verwirrungen und Missverständnisse sowie Fehler vermeiden, und machen den Code leichter lesbar. Gute Namen sind:
Selbsterklärend
Klar
Eindeutig
Unmissverständlich
Einprägsam
Sagen genau was das Ding tut oder enthält, nicht mehr und nicht weniger
Müssen nicht kommentiert werden
Zum Beispiel hier (C# Code): Der Klassen-Name sagt aus „Ich enthalte Geometrie-Methoden“, die erste Methode sagt „Ich berechne eine Kreisfläche, wenn du mir die Radius-Länge gibst“, usw. Man braucht nicht (mit F12 ins Visual Studio) sich den Code innerhalb einer Methode zu lesen, um zu wissen, was es tut.
public class GeometryCalculator
{
public double CalculateCircleSurface(double radiusLength)
{
return radiusLength * radiusLength * Math.PI;
}
public double CalculateSquareSurface(double sideLength)
{
return sideLength * sideLength;
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Ugly.Code
{
public class GeoCalc
{
public double GetCS(double value)
{
double val1;
double calc;
val1 = value;
calc = Math.Pow(val1, 2) * Math.PI;
return calc;
}
public double GetSS(double value)
{
double val1;
double calc;
val1 = value;
calc = Math.Pow(val1, 2);
return calc;
}
// Some other methods...
}
}
Warum ist der Code oben „Ugly“?
Ungenutzte „using“ Zeilen
Der Klassen-Name sagt nicht, was die Klasse enthält/anbietet/tut
Die Methoden-Namen sagen nicht, was sie tun oder berechnen/zurückliefern
Die Parameter-Namen sagen nicht, was sie enthalten
Die lokalen Variable-Namen sagen nicht, was sie enthalten
Lokale Variablen kaschieren die Parameter und dessen Werte, machen den Algorithmus schwer verständlich
Unnötige Leerzeilen verlängern unnötig die Methode. Man muss mehr scrollen und mit den Augen rauf & runterschauen.
Die Klasse „GeoCalc“ von Oben, könnte man auch so schreiben:
using System;
namespace Clean.Code
{
public class GeometryCalculator
{
public double CalculateCircleSurface(double radiusLength)
{
return radiusLength * radiusLength * Math.PI;
}
public double CalculateSquareSurface(double sideLength)
{
return sideLength * sideLength;
}
// Some other methods...
}
}
Zustimmung verwalten
Um dir ein optimales Erlebnis zu bieten, verwenden wir Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wenn du diesen Technologien zustimmst, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn du deine Zustimmung nicht erteilst oder zurückziehst, können bestimmte Merkmale und Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.