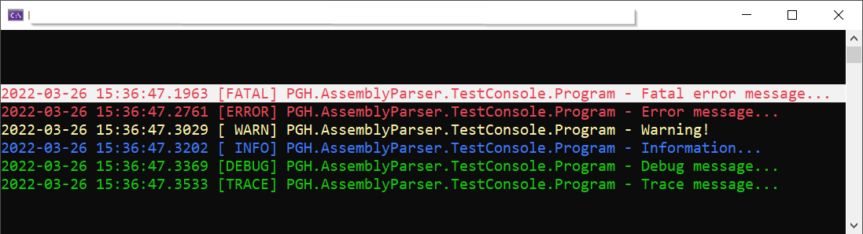
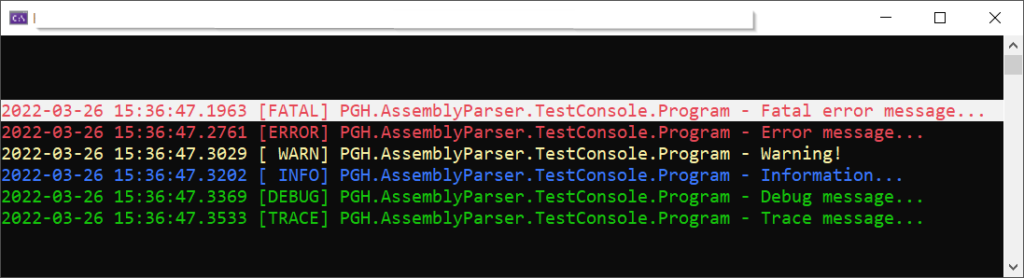
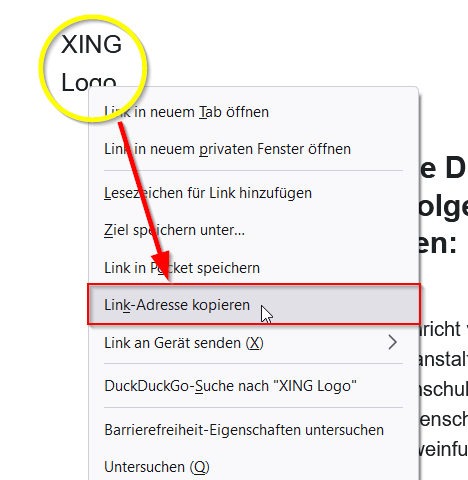
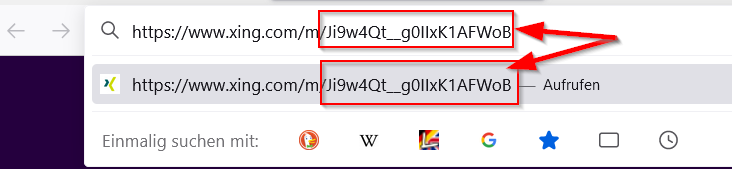
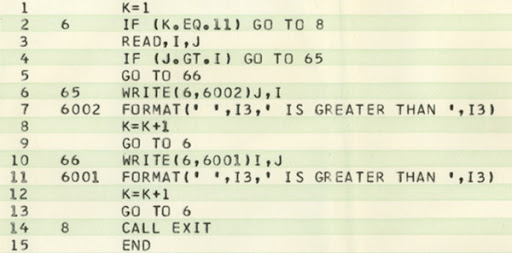
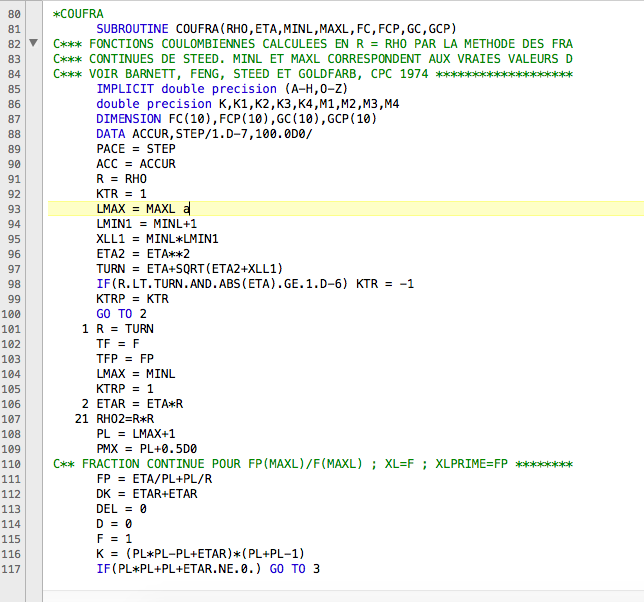
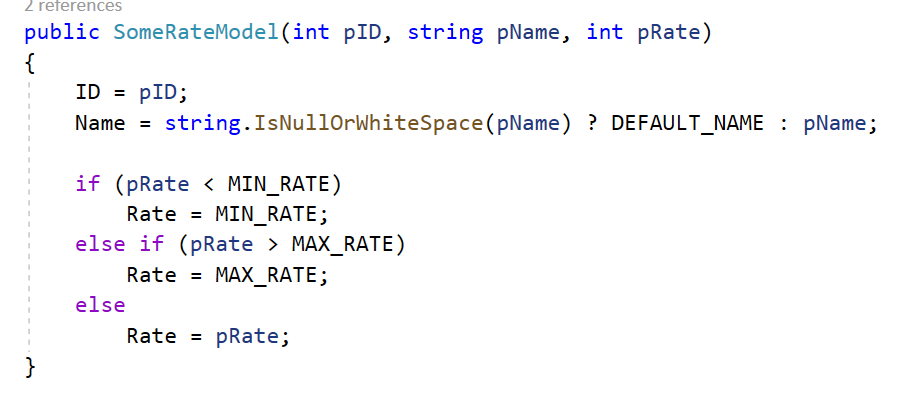
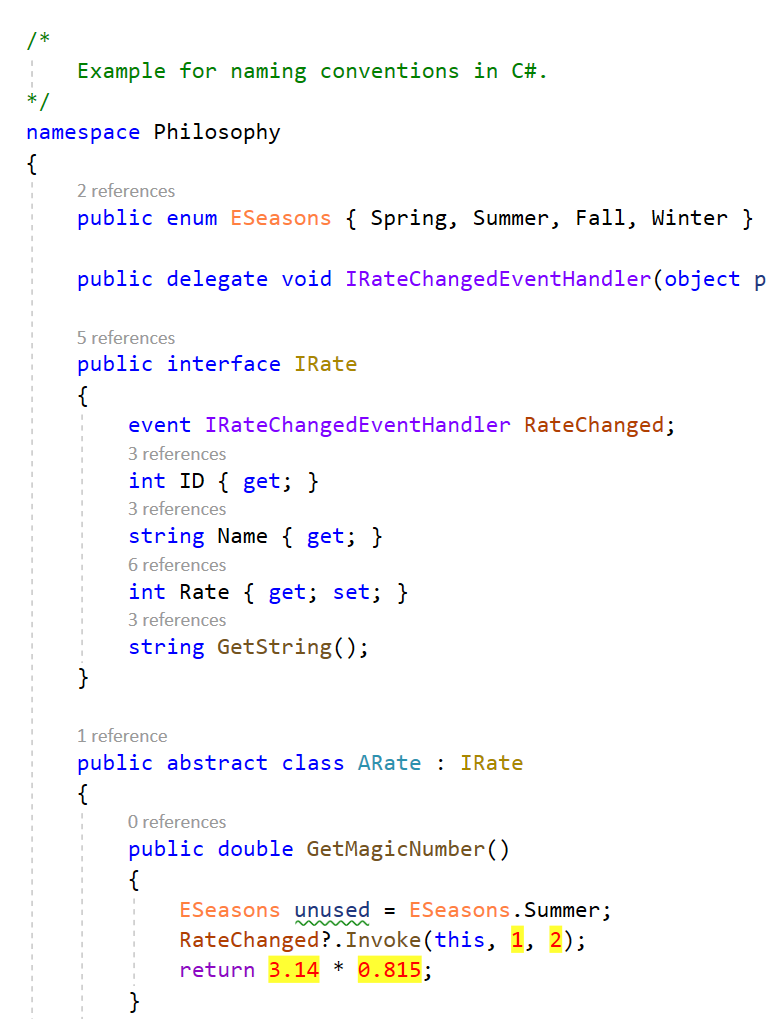
Der Logger NLog ist mit über 250M Downloads (in Nuget.org) einer der Standard-Logger für .NET/C#. Davor verwendete ich den log4net Logger.
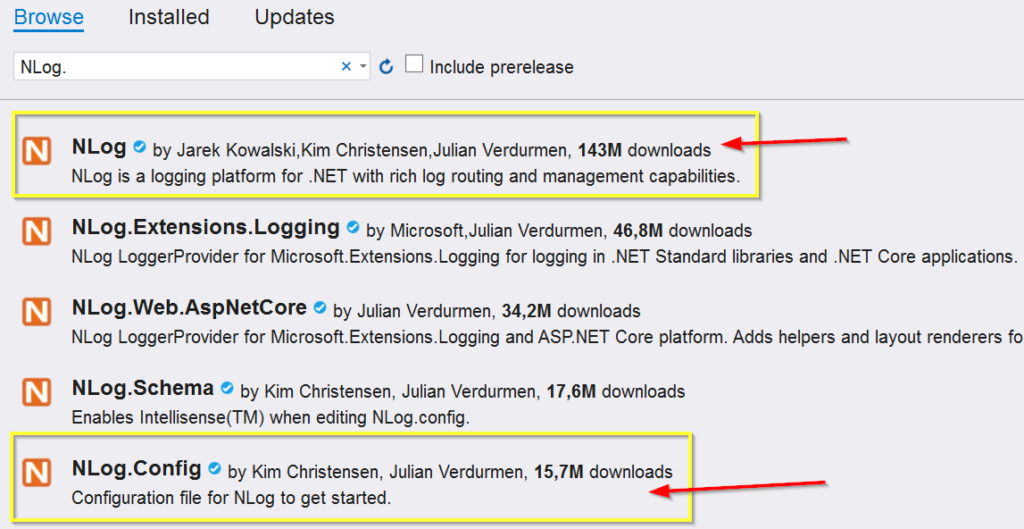
Um NLog zu verwenden müssen zwei Nuget-Packages installiert werden:
NLog
NLog.Config
Danach muss die NLog.config Datei im Projekt konfiguriert werden. Hier ist eine einfache Konfiguration um die Logs in einer Datei zu schreiben sowie diese auch in Console farbig auszugeben:
Nun kann der Logger wie folgt im Code verwendet werden:
class Program
{
// Create the logger for current class ( = typeof(Program)).
private static readonly NLog.Logger Logger = NLog.LogManager.GetCurrentClassLogger();
static void Main(string[] args)
{
Logger.Info("Starting application from Console...");
// more code...
}
}
Es gibt immer noch einige PCs und Notebooks mit Windows 7 oder 8.x die herumliegen oder gar noch im Betrieb sind (= Unsicher!). Man kann immer noch das Betriebsystem Windows 7, oder Windows 8.x (8.0 – 8.3) auf Windows 10 aktualisieren. Es ist nicht zu spät.
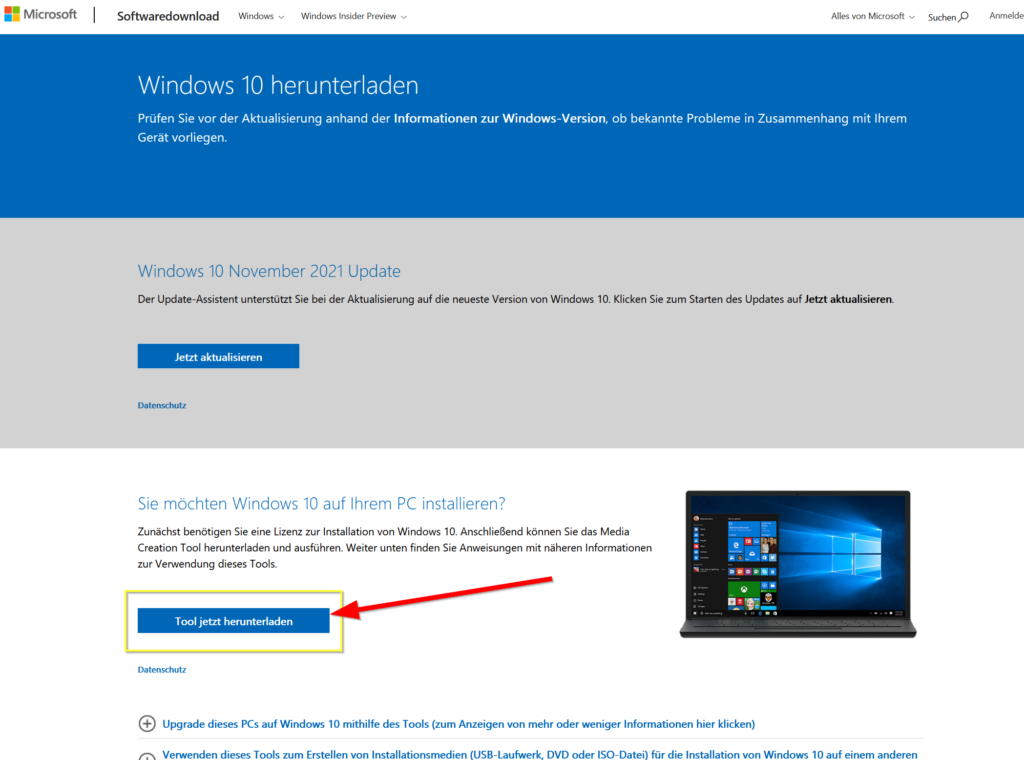
Hier ist eine bebilderte Schritt für Schritt Anleitung:
Nachem die Datei „MediaCreationToolXXXX.exe“ (XXXX steht für die aktuelle Version wie z.B.: 21H2) heruntergeladen/gespeichert wurde diese durch Doppelklick starten und folgende Schritte durchgehen:
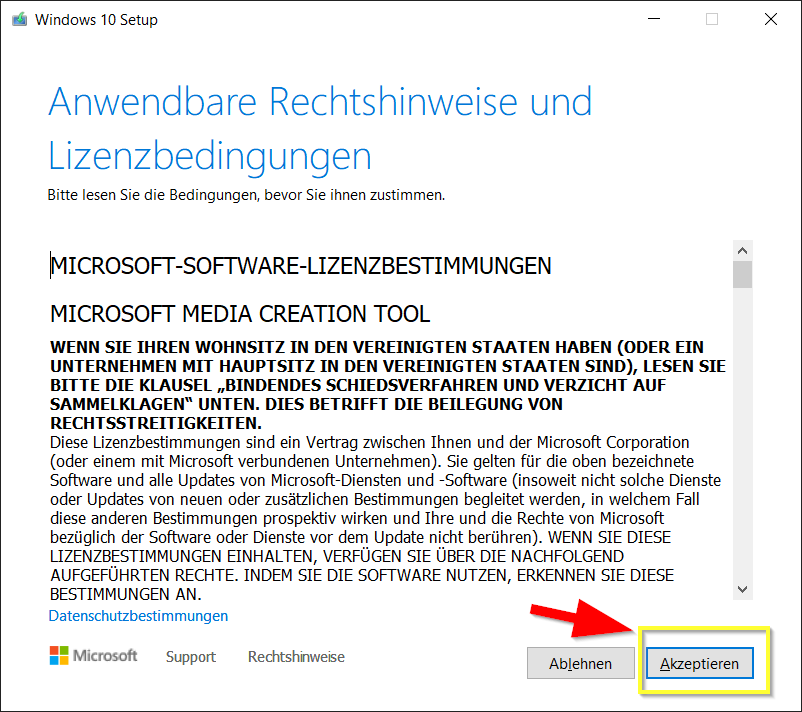
Die Lizenzbedingungen mit einem Klick auf „Akzeptieren“ akzeptieren:
Danach muss man sich entscheiden ob man ein Installations-USB-Stick oder Installations-DVD erstellen möchte. Ich persönlich bevorzuge ein USB-Stick als Installations-Medium, da es sicherer (zerkratzte/unlesbare DVD bzw. das Fehlen von DVD-Laufwerk auf manchem PC/Notebook) und die Installation viel Schneller ist. Hier beschreibe ich wie ein USB-Installer erstellt werden kann.
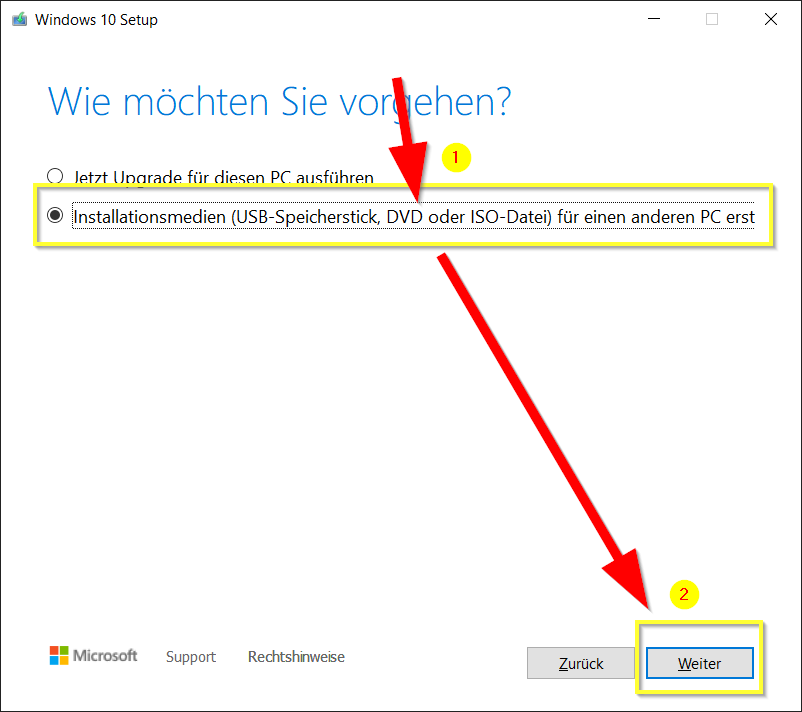
Nun die zweite Option „Installationsmedien (USB-Speicherstick, DVD oder ISO-Datei) für einen anderen PC erstellen)“ auswählen und auf „Weiter“ klicken:
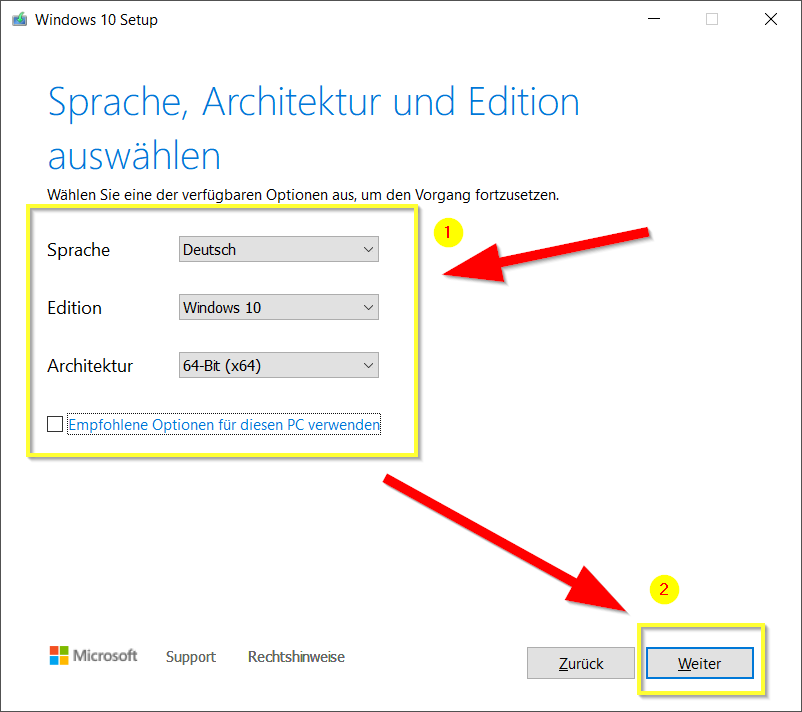
Jetzt die Sprache, Windows Edition (Windows 10) und die Architektur wählen und auf „Weiter“ klicken. Normalerweise ist „Deutsch„, „Windows 10“ und „64-Bit (x64)“ als Standardwerte bereits ausgewählt. Man kann durch das Abwählen von „Empfohlene Optionen für diesen PC verwenden“ die drei oben erwähnte Einstellungen freigeben, um z.B. die 32 (x86) Architektur zu wählen. Davon rate ich ab.
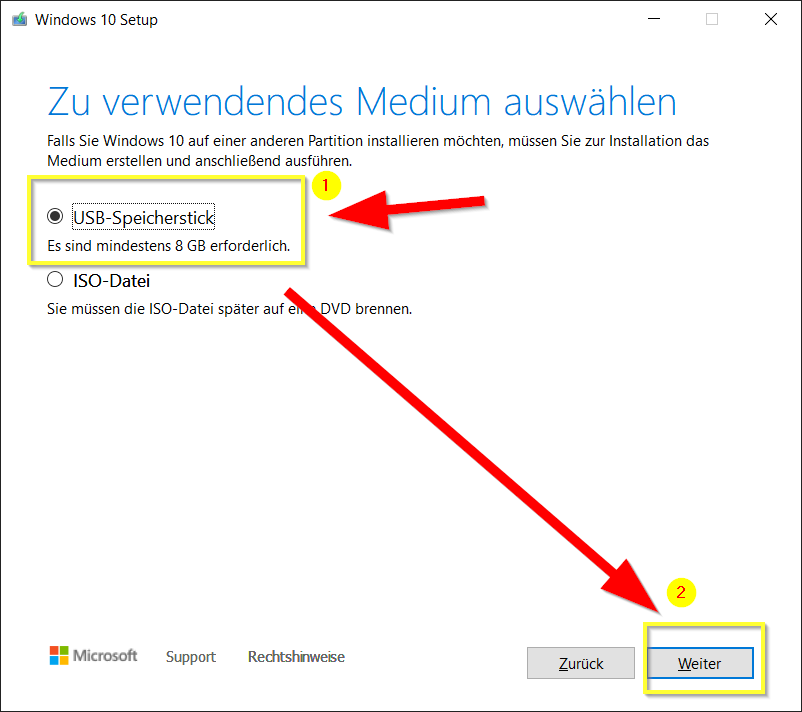
Nun muss das Installations-Medium „USB-Speicherstick“ oder „ISO-Datei“ (für DVD) gewählt werden. Ich empfehle USB-Speicherstick (wegen oben erwehnte Gründe) zu wählen, eine leeres USB-Speicherstick mit mindestens 8 GB an PC/Notebook zu stecken (am Besten USB 2.x oder USB 3.x) und auf „Weiter“ klicken:
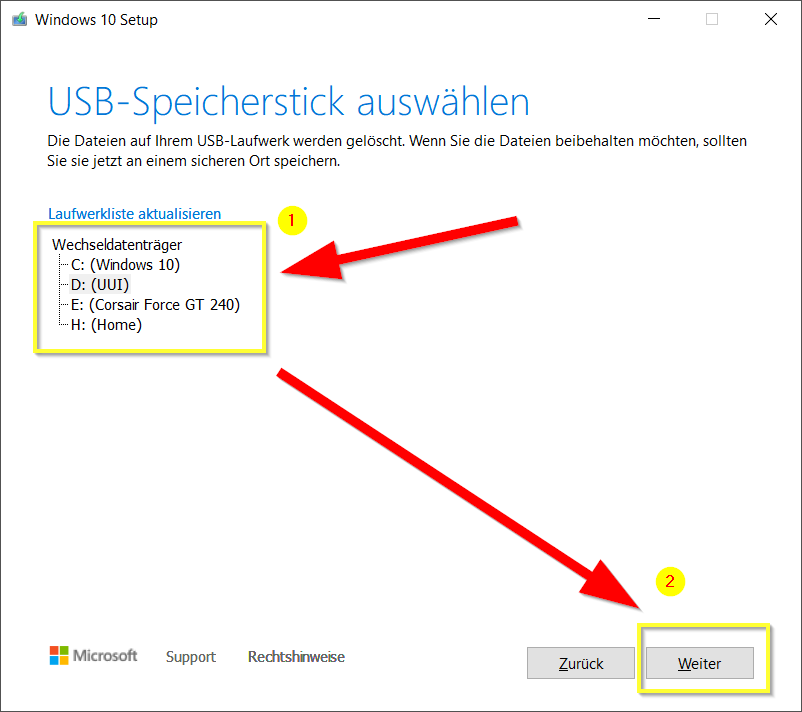
Nun wird eine Liste von Verfügbaren Medien (Festplatten, DVD- und USB-Laufwerke) angezeigt. Bitte wähle jetzt dein USB-Speicherstick (Vorsicht! Nicht das falsche Laufwerk wählen!) welcher Du vorher angesteckt hast und klick auf „Weiter„:
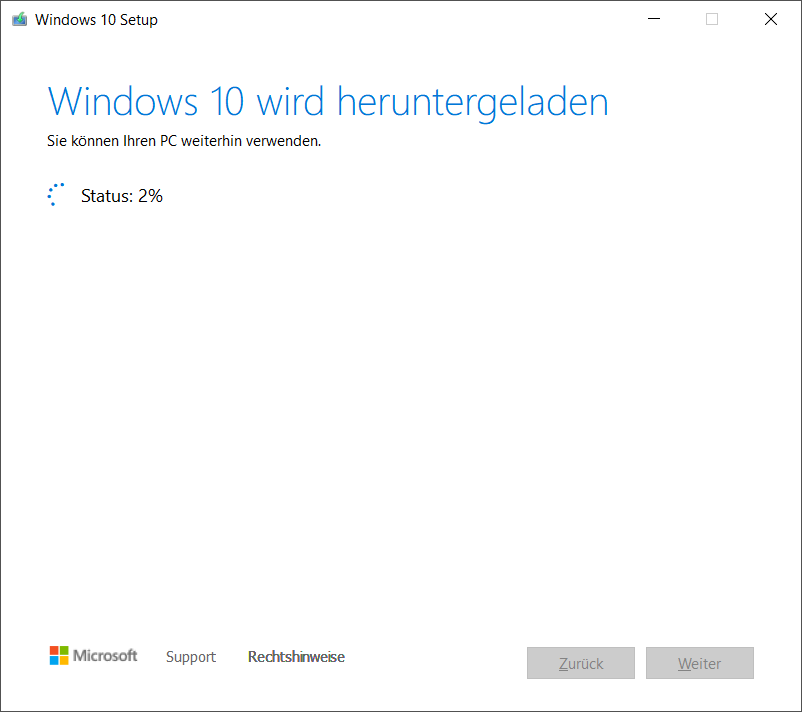
Nun werden die Dateien für den Windows-10-Installer heruntergeladen. Je nacht Internetgeschwindigkeit kann dies mehrere Minuten dauern:
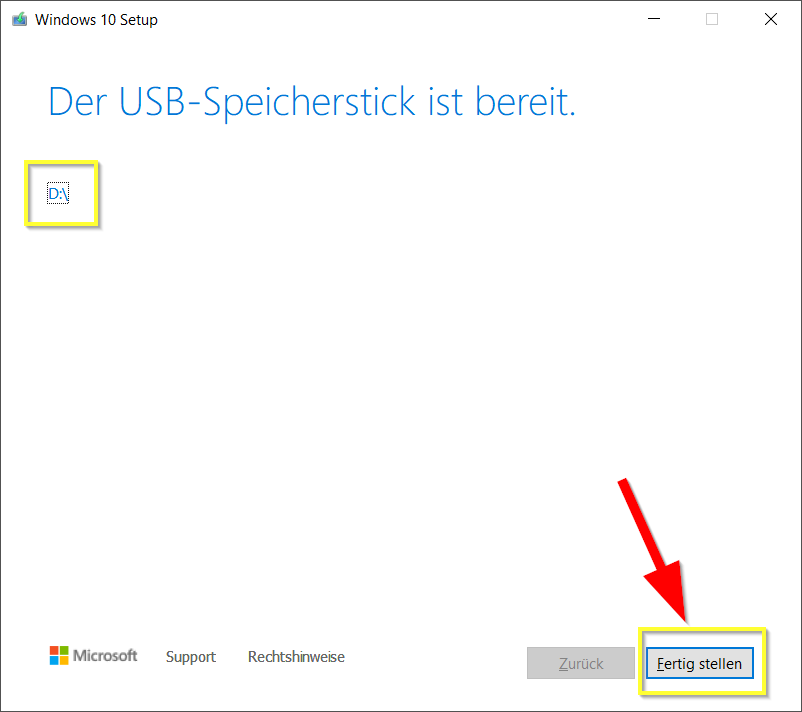
Wenn die Meldung „Der USB-Speicherstick ist bereit.“ angezeigt wird, kann man nochmal sehen auf welchem Laufwerk (in Beispiel-Bild „D:\„) der Windows-10-Installer sich befindet. Jetzt auf „Fertig stellen“ klicken:
Nun wird für kurze Zeit eine Meldung über die Bereinigung angezeigt und das Fenster schließt sich selbst.
Wir sind mit der Erstellung von Windows-10-Installations-USB fertig.
Manchmal kommt es vor, dass man die mehrfachen Starts von Anwendungen unterbinden will, damit die Anwendung pro User nur einmal gestartet wird. Anders formuliert: Die Anwendung soll nicht parallel pro User gestartet werden können.
Hier hilft der Mutex, wie im Beispiel-Code unten. Durch die Vergabe von spezieller Name kann global auf einem Rechner, die Anzahl der parallel laufende Anwendungs-Prozesse limitiert und kontrolliert werden:
using (Mutex mutex = new Mutex(false, "MyVerySpecialPrefix0815\\" + GUID_OF_MY_APP))
{
// see: https://docs.microsoft.com/en-us/dotnet/api/system.threading.waithandle.waitone?view=net-5.0#System_Threading_WaitHandle_WaitOne_System_Int32_System_Boolean_
if (!mutex.WaitOne(0, false))
{
DialogManager.ShowWarning("An instance of ACME application is running!", "Running multiple instances of this application is not allowed!");
}
}
Bei manche Anwendungen kommt es vor, dass man z. B. für bestimmte Kunden, Dinge wie Schrift-Art/-Größe, Farben, Dimensionen, Bilder, Icons etc. einfach und leicht („low ceremony“) ändern möchte, ohne den Quellcode jedes Mal zu ändern.
Dies erreicht man, indem man diese „Styles“ in einer externer „Styles.xaml“ Datei auslagert, zur Laufzeit, noch bevor das Hauptfenster erzeugt wird, ladet, und damit alle oder teile der Styles überschreibt. Vorausgesetzt die „Styles“ Datei ist als Ressource, also als Datei in dem Anwendungs-Verzeichnis deklariert (siehe Properties) und zu finden.
private void LoadCustomStyles()
{
if (File.Exists("CustomStyles.xml"))
{
try
{
using (var fileStream = new System.IO.FileStream("CustomStyles.xml", FileMode.Open, FileAccess.Read, FileShare.Read))
{
var dictionary = (ResourceDictionary)System.Windows.Markup.XamlReader.Load(fileStream);
Application.Current.Resources.MergedDictionaries.Clear();
Application.Current.Resources.MergedDictionaries.Add(dictionary);
}
}
catch(Exception ex)
{
Logger.Error(ex);
}
}
}
Dabei könnte die „CustomStyles.xaml“ Datei folgende Dinge enthalten:
<ResourceDictionary xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:clr="clr-namespace:System;assembly=mscorlib"
xmlns:logo="clr-namespace:Acme.Application.Icons"
mc:Ignorable="d">
<ResourceDictionary.MergedDictionaries>
<!-- Loading styles from a library -->
<ResourceDictionary Source="pack://application:,,,/Acme.Some.Library;component/Styles.xaml" />
</ResourceDictionary.MergedDictionaries>
<!-- Defining a string -->
<clr:String x:Key="PathToSomeIcon">../Icons/file.png</clr:String>
<!-- Defining an image -->
<Image x:Key="ImageCompanyLogo" Source="pack://application:,,,/Icons/acme_logo.png" Width="100" Height="120" />
<!-- Defining a brush -->
<SolidColorBrush x:Key="BrushForBorders" Color="#FFB400" />
<!-- Defining a color -->
<Color x:Key="Color1">#FFABCDEF</Color>
<Color x:Key="Color2">#FF123456</Color>
<!-- Defining a linear gradiant -->
<LinearGradientBrush x:Key="BorderWithGradiant" EndPoint="0.5,1" StartPoint="0.5,0">
<GradientStop Color="{DynamicResource Color1}" Offset="0" />
<GradientStop Color="{DynamicResource Color2}" Offset="0.5" />
<GradientStop Color="{DynamicResource Color1}" Offset="1" />
</LinearGradientBrush>
<!-- Defining style for specific control -->
<Style x:Key="MySpecialLabel" TargetType="{x:Type Label}">
<Setter Property="Background" Value="White"/>
<Setter Property="FontSize" Value="16"/>
<Setter Property="FontWeight" Value="Bold"/>
<Setter Property="Margin" Value="5"/>
<Setter Property="VerticalAlignment" Value="Center"/>
<Setter Property="HorizontalAlignment" Value="Center"/>
</Style>
</ResourceDictionary>
Es kommt vor, dass in einer Anwendung Ausnahmefehler (Exception), aus welchem Grund auch immer, nicht abgefangen und behandelt werden, was zum Absturz der Anwendung führt. Daten und stunden lange Arbeit können dabei verloren gehen, was den Anwender verärgern kann, und alles andere als schön ist.
Es gibt jedoch die Möglichkeit diese Ausnahmefehler abzufangen, um zumindest die Daten oder die Arbeit zu speichern, um danach die Anwendung automatisch wieder neu-starten oder zumindest ein Entschuldigungs-Dialog anzuzeigen.
Dazu gibt es 3 Ereignisse (Events) die einem über eine nicht-abgefangene Fehler informieren:
Für WPF einen Konverter (IValueConverter) zu schreiben ist relativ einfach. Einen Konverter zu schreiben, welcher dann in XAML Werte zugewiesen werden können, ist etwas schwerer. Ich habe einen abstrakten Konverter geschrieben, welcher es ermöglicht, darauf basierend, komplexere Konverter zu schreiben zu können, welche dann direkt in XAML statische oder dynamische Parameter annehmen können.
Eine besondere Rolle hat der „Dummy Rectangle“. Dieser wird missbraucht, um während der Laufzeit festzustellen, ob die Methoden der Klasse während der Design time oder Run time aufgerufen wurden.
using System.Runtime.CompilerServices;
using System.Windows.Data;
using System.Windows.Markup;
public abstract class AValueConverter : MarkupExtension, IValueConverter
{
protected static System.Windows.Shapes.Rectangle m_Dummy;
static AValueConverter()
{
m_Dummy = new System.Windows.Shapes.Rectangle();
}
[MethodImpl(MethodImplOptions.NoInlining)]
public abstract object Convert(object pValue);
[MethodImpl(MethodImplOptions.NoInlining)]
public virtual object Convert(object pValue, Type pTargetType, object pParameter, CultureInfo pCulture)
{
return Convert(pValue);
}
[MethodImpl(MethodImplOptions.NoInlining)]
public override object ProvideValue(IServiceProvider pServiceProvider)
{
return this;
}
[MethodImpl(MethodImplOptions.NoInlining)]
public virtual object ConvertBack(object pValue, Type pTargetType, object pParameter, CultureInfo pCulture)
{
throw new InvalidOperationException($@"This AValueConverter inheritor: ({GetType().Name}) does not support converting types backward!");
}
}
Auf dem AValueConverter kann nun, zum Beispiel ein Bool-To-Color-Converter realisiert werden:
using System.ComponentModel;
using System.Runtime.CompilerServices;
using System.Windows.Media;
public class BoolToColorConverter : AValueConverter
{
public Brush FalseBrush { get; set; } = Brushes.Red;
public Brush TrueBrush { get; set; } = Brushes.Green;
[MethodImpl(MethodImplOptions.NoInlining)]
public override object Convert(object pValue)
{
if (DesignerProperties.GetIsInDesignMode(m_Dummy))
{
return FalseBrush;
}
if ((bool)pValue)
{
return TrueBrush;
}
else
{
return FalseBrush;
}
return FalseBrush;
}
}
Oder zum Beispiel einen Bool-To-Visibility-Converter:
using System;
using System.ComponentModel;
using System.Runtime.CompilerServices;
using System.Windows;
public class BoolToVisibilityConverter : AValueConverter
{
public Visibility FalseVisibility { get; set; } = Visibility.Hidden;
public Visibility TrueVisibility { get; set; } = Visibility.Visible;
[MethodImpl(MethodImplOptions.NoInlining)]
public override object Convert(object pValue)
{
if (DesignerProperties.GetIsInDesignMode(m_Dummy))
{
return Visibility.Visible;
}
if ((bool)pValue)
{
return TrueVisibility;
}
else
{
return FalseVisibility;
}
return FalseVisibility;
}
}
Diese Konverter können nun in XAML wie folgt (in Bindings) verwendet/aufgerufen werden:
ObservableList<T> erweitert ObservableCollection<T> mit nützlichen Methoden, um einfach mehrere Elemente in die Collection hinzufügen oder entfernen.
Anwendungs-Beispiele:
var items1 = new string[] { "a", "b", "c" };
var items2 = new string[] { "x", "y", "z" };
var items3 = new string[] { "1", "2", "3" };
// Adds a, b, c to the end of collection.
Items.InsertItemsAtEnd(items1);
// Adds x, y, z to start of collection.
Items.InsertItemsAtStart(items2);
// Adds 1, 2, 3 to indices 3, 4 and 5.
Items.InsertItemsAt(3, items3);
// Removes first 4 elements from collection.
Items.RemoveItemsFromEnd(4);
// Removes last 4 elements from collection.
Items.RemoveItemsFromStart(4);
// Adds Hello and World to the end of collection.
Items.AddRange(new string[] { "Hello", "World!"});
Implementierung von ObservableList<T>:
public class ObservableList<T> : ObservableCollection<T>
{
public virtual void RemoveItems(IEnumerable<int> pIndices)
{
foreach (var i in pIndices)
RemoveItem(i);
}
public virtual void RemoveItemsFromStart(int pCount)
{
while (Count > 0 && pCount > 0)
{
RemoveAt(0);
pCount--;
}
}
public virtual void RemoveItemsFromEnd(int pCount)
{
while (Count > 0 && pCount > 0)
{
RemoveAt(Count - 1);
pCount--;
}
}
public virtual void InsertItemsAt(int pIndex, IEnumerable<T> pItems)
{
foreach(var item in pItems)
InsertItem(pIndex++, item);
}
public virtual void InsertItems(IEnumerable<T> pItems)
=> InsertItemsAt(Count, pItems);
public virtual void InsertItemsAtStart(IEnumerable<T> pItems)
=> InsertItemsAt(0, pItems);
public virtual void InsertItemsAtEnd(IEnumerable<T> pItems)
=> InsertItems(pItems);
public virtual void AddRange(IEnumerable<T> pItems)
=> InsertItems(pItems);
}
Wenn URLs, Links und Anklickbare Benutzerschnittstellen, nicht eindeutig als solches (Signalstärke) angezeigt werden:
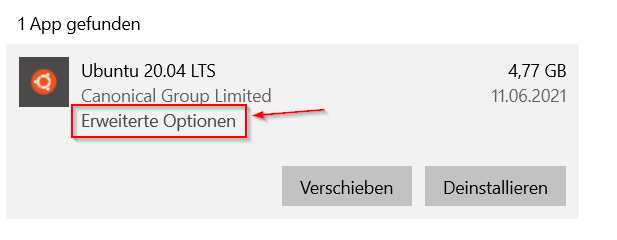
Gerade wollte ich meine Ubuntu Installation auf Windows 10 (WSL) zurücksetzen, und habe nach den anklickbaren Text „Erweiterte Optionen“ gesucht. Kein Wunder, dass meine Suche etwas gedauert hat.
Heute war ich bei einem Discounter für: Hygiene-Artikel, Wasch- und Putz-Mittel und der gleichen.
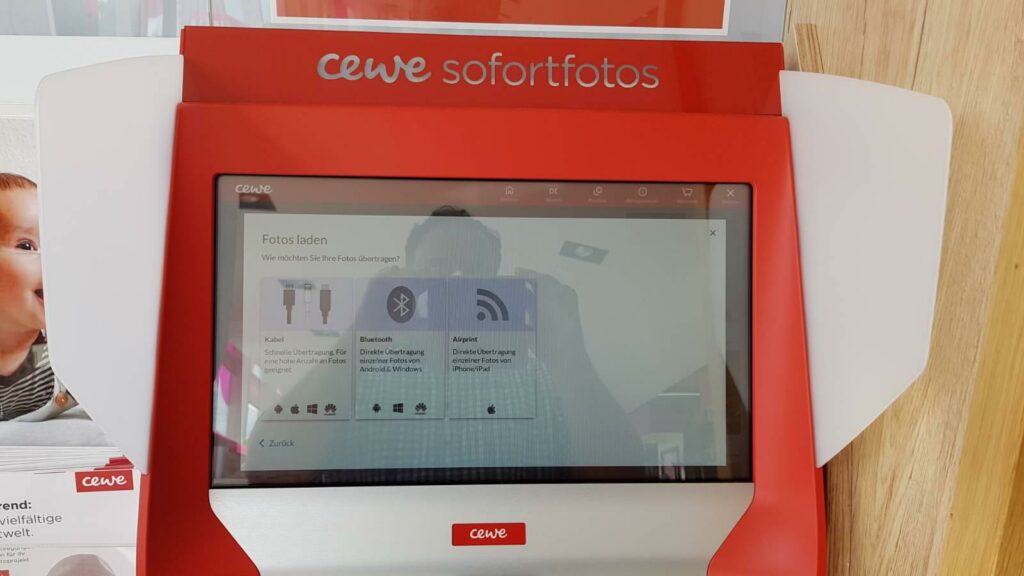
Ich wollte „einfach und schnell“ ein paar Fotos, die ich mit meinem Smartphone gemacht hatte auf Fotopapier ausdrucken lassen. So wie es die Werbung versprach.
Ich ging zum Automat.
Da ich ein IT-Sicherheits-Fanatiker bin, wollte ich meinem Smartphone nicht mit Malware über USB verseuchen. Also entschied ich mich für Bluetooth.
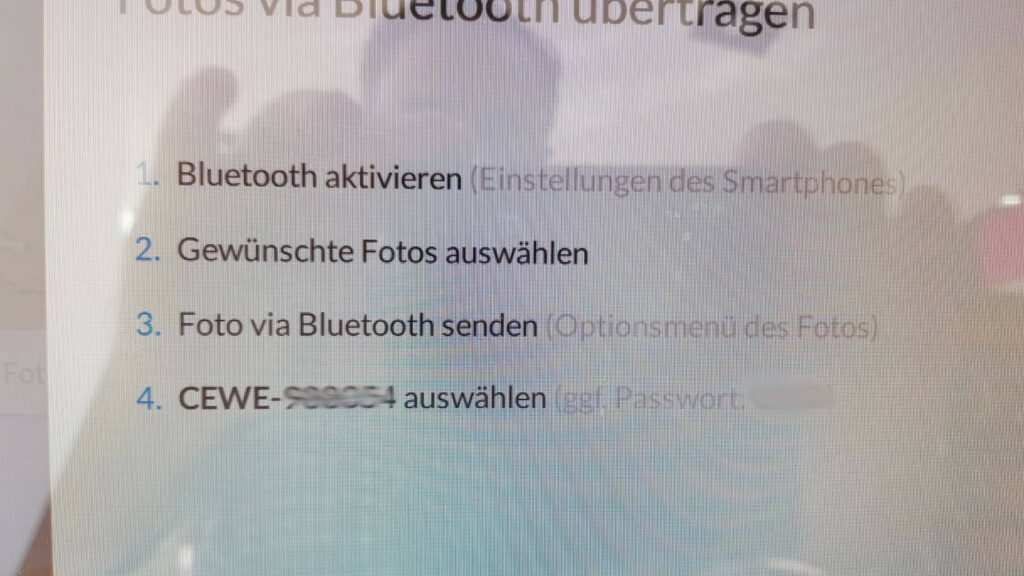
Ich befolgte die Anweisungen auf dem Bildschirm, Punkt für Punkt.
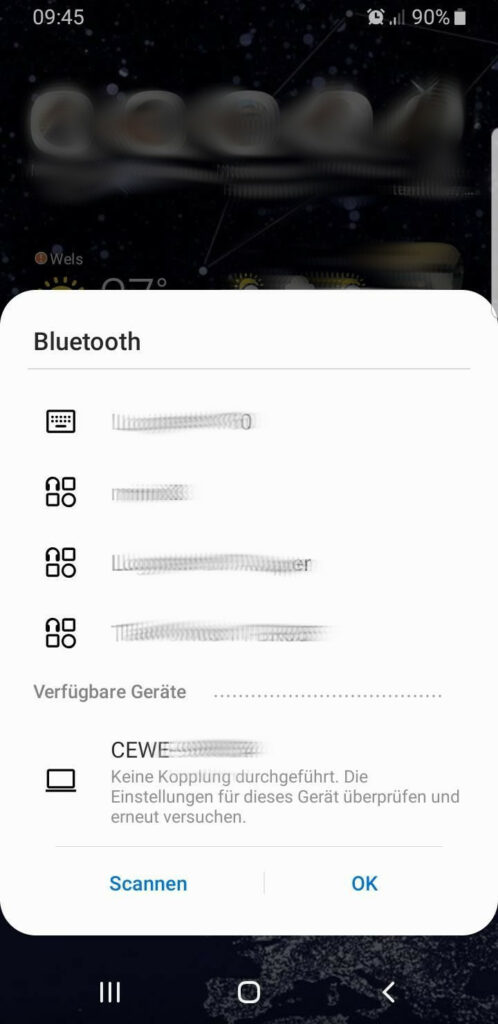
Ich wählte das Gerät „CEWE-XXXXXX“ wie auf dem Bildschirm des Automaten angezeigt.
Und siehe da!
Es funktionierte NICHT!
Ich probierte eine Zeit lang herum, schaltete mein Bluetooth aus und wieder ein, nach dem AEG-Prinzip (Ausschalten, Einschalten, Geht wieder) … schaute mir Minuten lang die Einstellungen von meinem Smartphone, und suchte nach irgend eine Einstellung, die Falsch wäre. Ohne Erfolg.
Nun gab es dort, einen zweiten Foto-Print-Automaten. Ich dachte mir, ich probiere der zweite Automat aus. Das gleiche Problem!
Notgedrungen, wählte ich diesmal die USB-Methode aus. Es funktionierte. Gleich danach, ließ ich mein Anti-Virus-Programm updaten und startet eine vollständige Suche nach Malware.
„Einfach & Schnell“ …
Jemand sagte mir mal: „Die Geschäftsleute haben schon immer das verkauft, was sich die Techniker immer gewünscht haben.“
Neulich nahm ich mein Smartphone zur Hand, öffnete den Firefox-Browser im Privatmodus, wie ich es gewohnt bin, und gab die Webseite eines Motorradherstellers ein.
Nachdem ich etwa fünfmal auf das Menüsymbol geklickt hatte, öffnete sich endlich das Menü. Offenbar war der anklickbare Bereich (von mir mit einem gelben Quadrat markiert) exakt so klein wie das Menü-Icon selbst!
Da ich mich für ein Motorrad für längere Reisen auf Asphalt interessierte, suchte ich nach einer passenden Kategorie wie „Reise-Enduro“ oder „Adventure“ und fand schließlich etwas Entsprechendes. Ich wählte ein Modell aus, scrollte nach unten und freute mich, als ich den Abschnitt „Motor“ mit Bild und Titel entdeckte. Endlich, dachte ich, bekomme ich die technischen Details wie Zylinderanzahl, PS, KW oder Hubraum zu sehen. Doch leider stand dort nichts davon!
Enttäuscht scrollte ich weiter und stieß auf die Option „BROSCHÜRE HERUNTERLADEN“.
Da der Text keinerlei „Signalwirkung“ hatte und nicht als klickbar hervorgehoben war, versuchte ich mehrmals, auf das Symbol/Bild „Herunterladen“ zu klicken (von mir blau markiert), jedoch ohne Erfolg.
Im nächsten Schritt klickte ich direkt auf den Text (von mir rot markiert) – und siehe da, plötzlich passierte etwas: Eine lange Liste von PDF-Dateien wurde angezeigt.
Es stellte sich heraus, dass die PDFs Broschüren für verschiedene Motorradmodelle waren. Allerdings wusste ich nicht, welche Datei ich für mein ausgewähltes Modell anklicken sollte. Also ging ich zurück, um den Modellnamen erneut nachzusehen, und kehrte anschließend zur Liste zurück. Doch mein Modell war nicht dabei.
Auf gut Glück wählte ich eines der „DOWNLOAD“-Elemente aus und begann, 11,5 MB herunterzuladen. Nach einer gefühlten Ewigkeit (LTE oder 3G?) war die Datei endlich auf meinem Smartphone. Ich öffnete sie voller Erwartung – und staunte.
Die Broschüre enthielt Daten für sämtliche Modelle der ausgewählten Kategorie. Leider war sie absolut nicht für Smartphones optimiert. Der Text war winzig, und Zoomen durch Wischen machte die Sache nur noch unübersichtlicher. Frustriert steckte ich mein Smartphone weg und wartete, bis ich die Webseite zu Hause an meinem 4K-Monitor aufrufen konnte.
„Die Geschichte ist ein Lehrer, ohne Schüler.“ Antonio Gramsci
Oft ist es gut, zu wissen wie etwas entstanden ist, oder welches Problem zu ein bestimmtes Werkzeug, Konzept oder Paradigma geführt hat, und welche Idee dahinter steckt.
Ein paar Beispiele:
Die Rolltreppe wurde einst erfunden, um die Passagiere schneller in/aus die (U-)Bahn-Station zu befördern. Dass die Passagiere darauf weiter gehen (Summation der Geh-Geschwindigkeit + Rolltreppen-Geschwindigkeit) und NICHT stehen bleiben sollten, haben die Passagiere nicht mitbekommen oder nicht verstanden.
Der Computer-Führerschein-Test wurde einst eingeführt, um 1. die theoretischen Tests einheitlich zu machen, und 2. Kosten (Beamten von Verkehrs-Ministerium) zu sparen sowie Verwaltungs-Aufwand zu reduzieren (Internet + Datenbank statt Termine und Papiere). Seit Einführung der Computer-Führerschein-Tests lernen die Fahrschüler die richtigen Antworten zu gezeigten Bilder und Fragen auswendig. Sie lernen für die (bekannten) Test-Fragen/-Bilder, nicht mehr! Folgende Fragen können diese nicht beantworten: Worum geht es bei all den Geboten und Verboten, bzw. was ist der Hauptgedanke von all dem? (damit der Verkehr möglichst für alle Teilnehmer immer im Fluss bleibt und niemals zum Stillstand kommt). Warum steht bei der Einfahrt in ein Kreisverkehr (meistens) ein „Vorrang geben“ Schild? (weil in Worst-Case-Szenario es dazu kommen kann, dass niemand aus dem Kreisverkehr rausfahren und deshalb auch niemand mehr reinfahren kann = Stillstand schlimmsten Art! Es geht wie immer um das Garantieren des Verkehrsflusses für möglichst alle Teilnehmer) Warum soll man sich an einer Kreuzung möglichst rechts einordnen, wenn man nach rechts abbiegen will, und möglichst links, wenn man nach links abbiegen will? (damit andere, die in die andere Richtung abbiegen möchten Platz haben und nicht unnötig dahinter warten müssen. Garantieren des Verkehrsflusses! Lange Auto-Schlangen/Staus möglichst bald verhindern!) Warum soll man an einer Kreuzung zügig abbiegen und auch beschleunigen? (damit N andere Teilnehmer nicht stark bremsen müssen, und dadurch Reduktion von Kollisions- und Auffahrunfälle zu erreichen) Warum werden an manchen Abschnitten der Autobahnen, die Höchst-Geschwindigkeit auf 100, 80 oder 70 km/h beschränkt? (wegen Autobahn-Ausfahrt(en) oder -Abzweige, damit sich alle rechtzeitig richtig und sicher einordnen können, ausgenommen Polizei-/Pass-Kontrolle, Umweltschutz und Reduktion von Lärm in stark besiedelten Abschnitte)
Warum wurden die ersten Computer/Rechenhilfsmittel (Abakus, Logarithmus-Schieber/-Tabellen, mechanische Rechner udg.) erfunden? (um menschliche Fehler zu vermeiden)
„Der Teufel steckt im Detail“ (deutsches Sprichwort)
Ich mag dieses Sprichwort nicht, und verwende es selten, wenn überhaupt, ungern. Warum? Will man einen kleinen ruhigen Fluss übersetzen/überqueren, reicht es wenn man sich an ein Stück Holz oder Baumstamm umklammert und hinüberschwimmt oder sich treiben lässt. Dazu muss man nicht viel wissen.
Will man jedoch die Meere oder Ozeane durchqueren, muss man sich ein Schiff oder U-Boot bauen. Dazu braucht man Details wie Physik: Dynamik, Auftriebskraft, hydrostatischen Druck, Navigation, Masse, Volumen etc., sonst sinkt das Schiff/U-Boot.
Für mich, als Techniker, steckt die Lösung im Detail, solange dies Relevanz hat. Man stelle sich vor: jemand leiht sich ein Auto aus und muss Tanken. Er tankt Diesel. Das Auto ist aber ein Benziner… soviel zum „Der Teufel steckt im Detail“ oder „Details interessieren mich nicht!„.
Software-Entwickler die immer in Teams gearbeitet haben, sind besser als jene die ausschließlich alleine Programmiert haben. Warum?
Wenn Anton, Bert und Christian in Team arbeiten: Zahn + Rad = Zahnrad + Christians Idee = Planetengetriebe
Weil:
Vier Augen sehen mehr als zwei. Sechs Augen sehen mehr als vier, usw. usf.
Zwei Köpfe denken mehr als einem Kopf. Drei Köpfe denken mehr als zwei usw. usf.
Ideen: die Kollegen haben manchmal bessere Ideen
Schneller ans Ziel kommen 1: ein Kollege kennt schon die Lösung zu einem Problem
Schneller ans Ziel kommen 2: die Arbeit kann aufgeteilt werden
Code-Review: die Kollegen von Team machen einem auf die Fehler udg. aufmerksam. Man lernt, und bessert sich.
Lernkurve: in Team lernt man viel mehr Dinge in viel kürzere Zeit
Erfahrung: ein Kollege hat bereits Erfahrung mit XY und teilt diese
Disziplin: um mit den Anderen am gleichen Code, Komponenten etc. zu arbeiten, muss man sich an bestimmte interne Standards, Regeln und Vorschriften einhalten (Naming, Coding, Commenting, Code-Style, Versioning, Change-Logs, Git/Subversion Commits, Packaging, …)
Bessere, solidere APIs und Code: kein Team-Mitglied kann Ad hoc Signaturen ändern, Dinge umbenennen oder zu verschieben („Rambo-Programmierung“). Jedes Team-Mitglied ist gezwungen:
mit den Anderen zu Kommunizieren (Vorgänge absprechen)
sich Dinge (Namen, Kommentare, Algorithmen etc.) vorher sehr gut überlegen, da die Anderen ihren Code auch ändern müssen
Schnellere Erfolgserlebnisse in viel kürzere Zeiten: da Einzelteile schneller entwickelt werden, hat man in viel kürzeren Zeitabständen Erfolgserlebnisse. Als Einzelkämpfer dauert es viel länger, um ein Teil-Erfolg zu feiern.
Motivation: Erfolgserlebnisse in kurzen Zeitabständen motivieren (Erfolgserlebnisse in sehr langen Zeitabständen demotivieren!)
Es macht mehr Spaß!
Man entwickelt sich weiter: Ein Entwickler in ein N-köpfiges (N > 1) Team vermehrt, vertieft und verbessert seine Fähigkeiten, Kenntnisse, Können und Still mit Faktor N in gleicher Zeitraum als der Einzelkämpfer
Für zahlreiche Webseiten ist ein Konto erforderlich. Zur Kontoerstellung werden in der Regel eine E-Mail-Adresse und ein Passwort verlangt. Nach der erfolgreichen Registrierung können Sie sich jederzeit an- und abmelden.
Beachten Sie: Die Registrierung erfolgt nur einmal, während das Anmelden bei Bedarf wiederholt werden kann.
Nach Pareto-Prinzip (20-80 oder 20 % – 80 % Regel) würde dies heißen:
Man registriert sich in höchstens 20 % der Fälle (= A)
Anmelden tut man sich dann in mindestens 80 % der Fälle (= B)
Somit wären die UI Elemente für das Anmelden (= B) wichtiger als für das (einmalig) Registrieren (= A)
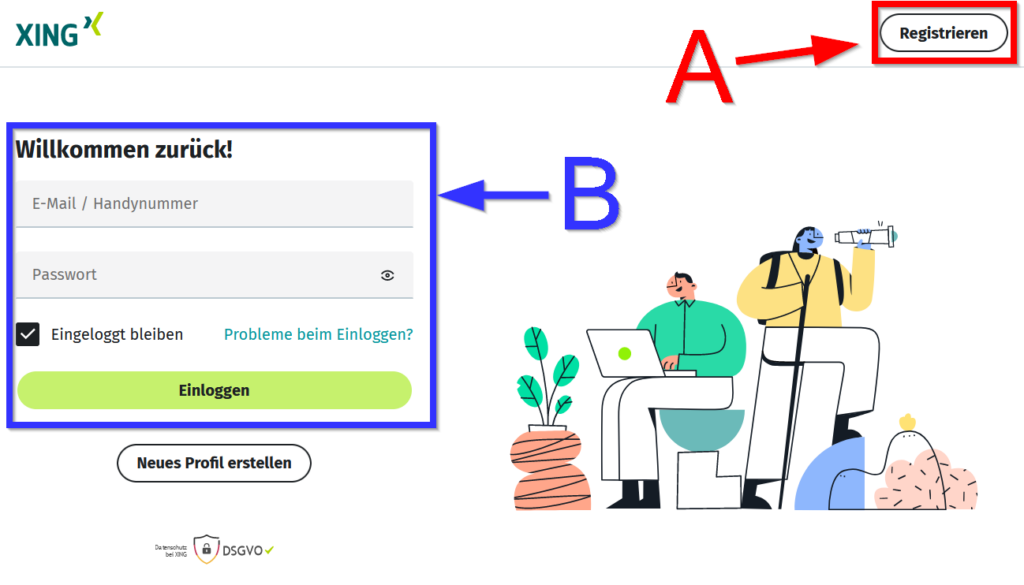
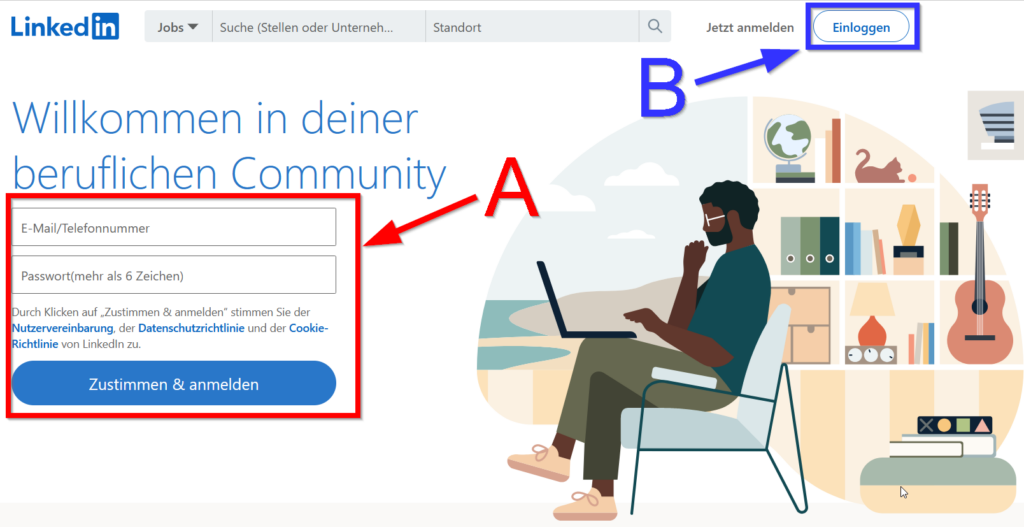
Vergleichen wir nun LinkedIn.com mit Xing.com: Welche der beiden Webseiten legt durch Position und Größe mehr Wert auf die Relevanz (entsprechend der Nutzungshäufigkeit)? Und bei welcher Seite, basierend auf Steve Krugs Prinzipien, klickt man fast intuitiv und ohne großes Zögern korrekt?
Xing.com: Anmeldung hat mehr Raum und fällt sofort auf
LinkedIn.com: Registrierung hat mehr Raum und fällt sofort auf
Im alten Persien, reiste ein Mann durch eine Wüste. Auf dem Weg fand er eine Blume. Er griff zur Blume und wollte es nehmen/reißen, müsste sie jedoch loslassen, da er sich dabei verletzte. Seine Finger waren blutig und taten weh.
Er schaute genauer hin und sah die Dornen, und fragte die Blume: „Was bist du?“ Die Blume antwortete: „Ich bin eine Rose, eine Blume.“ Der Mann fragte: „Eine Blume? Blumen haben keine Dornen. Warum hast du Dornen?“ Die Blume: „Ich hatte lange Zeit nur einen Dornenstrauch als Gefährte.“
Der Mann ging weiter. Nach einiger Zeit roch er einen süßlich lieblichen Duft. Den Duft folgend traf er auf einen Dornenstrauch. Er roch daran. Es war der Dornenstrauch der den Duft verbreitete. Er fragte den Dornenstrauch: „Was bist du?“ Der Dornenstrauch: „Ein Strauch. Ein Dornenstrauch.“ Der Mann erwiderte: „Dornensträucher haben keinen Duft. Warum duftest du so gut?“ Der Dornenstrauch: „Ich hatte lange Zeit eine Rose als Gefährte.“
Im alten Persien, reiste ein Mann einen langen Weg, um bei einem berühmten Gelehrter Unterricht zu nehmen. Jahre vergingen und der Schüler reiste mit einem Karawanenzug zurück nach Hause.
Auf dem Weg, mitten in der Wüste, wurde die Karawane von Räubern überfallen, und die Räuber durchsuchten die Taschen und Säcke der Händler. Als sie die Tragetaschen des Schülers auf seinem Kamel durchsuchten, fanden sie nichts als Bücher. Deren Anführer kam zu dem Schüler und fragte ihm warum er nur Bücher besitzt, worauf der Schüler erwiderte, diese sind seine Aufzeichnungen von all das Wissen, was sein Lehrer ihm beibrachte.
Der Anführer der Räuber befahl die Bücher zu verbrennen, und der Schüler fiel mit entsetzen zu Boden, schaute zu wie all das Wissen das er Jahre lang gesammelt und niedergeschrieben hatte, in Flammen vernichtet wurden. Der Schüler kehrte danach um, um wieder bei dem Gelehrten Unterricht zu nehmen.
Jahre vergingen…
Die gleichen Räuber überfielen wieder mal einen Karawanenzug. Und die Räuber fanden einen Mann, der Nichts hätte als seiner Bekleidung, eine Trinkflasche, etwas Brot und Salz, und das Kamel auf dem er reiste. Der Anführer ging zu ihm und fragte: „Was transportierst du?“, worauf der Mann erwiderte: „Wissen und Erfahrung“ und zeigte dabei auf seinem Kopf.
Ein Sprichwort aus dem Orient (Afghanistan, Iran, Türkei, …): „Der Stein, den ein Mann in den Brunnen warf, und hundert/tausend Männer es nicht herausbekamen.“
Bedeutung und Anwendung: wenn jemand einen schweren Fehler macht/verursacht, sodass hundert/tausend Andere es nicht mehr, oder sehr schwer wieder korrigieren können.
Die Geschichte dazu: Ein Mann warf (aus Langeweile, Bosheit oder als Experiment?) einen großen Stein in den einzigen Brunnen, dass irgendwo in der Wüste existierte, von dem alle Menschen in der Umgebung abhängig waren. Dadurch versickerte der Wasserader unten in den Brunnen, wodurch es meilenweit kein Trinkwasser mehr gab. Alle Männer aus dem Dorf kamen und halfen um den Stein wieder heraus zu holen, ohne Erfolg.
Ein australischer Teilchen-Physiker konvertierte zum Buddhismus, und nach Jahren wurde er zu einem Mönch ausgebildet. Er bekam den Auftrag nach Australien zurückzukehren, um dort ein Tempel zu bauen.
Also ging er zurück, und begann alleine den Tempel zu bauen. Einige Jahre vergingen und als der Tempel fertig gebaut war, schrieb er eine Einladung an seinem Auftraggeber, er möge nach Australien kommen, um den Tempel zu begutachten.
So reiste der andere Mönch nach Australien und der australische Mönch zeigte ihm den Tempel, den er ganz alleine gebaut hatte.
Als sie draußen rund um den Tempel spazierten, zeigte der australische Mönch auf eine Stelle und sagte bedauernd: „Leider habe ich diesen Ziegel etwas schief platziert, und nun ragt es etwas heraus und ist nicht sehr schön.“
Der Andere schaute ihm an und erwiderte: „Du hast ganz alleine ein Tempel gebaut. Den Tempel siehst du nicht, aber den einen schiefen Ziegel?“
Ein (unbekannter) schintoistischer Mönch hat folgende Denkaufgabe gestellt:
Ein Kutscher fährt mit seiner Kutsche, die von einem Pferd gezogen wird über eine Straße. Plötzlich steckt ein Rad fest in ein Schlagloch, und die Kutsche kommt aus diesem nicht mehr raus.
Untertitel: Zwischenmenschliche Beziehungen erfolgreich gestalten Von Vera F. BIRKENBIHL ISBN 978-3-86882-446-9
Die Autorin hat uns leider viel zu früh verlassen … als Autodidaktin spezialisierte sie sich auf „Gehirn-gerechtes Arbeiten“ und lehrte Praxis-bezogen, wie man effizienter lernt, kommuniziert usw.
Es gibt (noch) einige Videos von ihren Vorträgen auf YouTube die ich jedem empfehle:
Der Autor erklärt in diesem Buch, dass Java nicht nur eine Programmiersprache, sondern eine Sammlung verschiedene Paradigmen und Konzepte ist, zählt einige auf und erklärt interessante Details und die Geschichte dazu:
Die Java Umgebung: Bestandteile, Compiler, Interpreter, Virtual Machine sowie Java-Besonderheiten
Java Virtual Machine: Datentypen, Register und lokale Variablen, Laufzeit-Umgebung, Heap und Stack, die Sprache der VM (Code-Verwaltung und Befehlssatz)
Aufbau einer *.class Datei
Sicherheitskonzepte: Rechner-Sicherheit, Sicherheit durch Sprach-Design und den Compiler sowie die Überprüfung des Byte-Codes, Trennung in Namensräume, Security Manager und Probleme der Java-Sicherheit
Das Buch eignet sich (vor Allem) für alle Java-Anfänger und Aufsteiger, bietet mehr Einblick unter die Haube, sorgt für „Aha!“ Momente, und führt zu ein besseres Verständnis womit man effizienter und besser Java programmieren kann. Enthält außerdem einige lustige „Fun Facts“, wie zum Beispiel der Code Point für Klassen-Erkennung: 0xcoffeebabe (Coffe Babe) 😉
Was passiert, wenn jemand, der irgendwann mal Code geschrieben hat, jedoch von Software-Engineering kaum eine Ahnung hat, sich in die Arbeit von professionellen Software-Entwicklern einmischt und für denen Entscheidungen trifft?
Gegenfrage 1: sagt er jeden Tag dem Schulbus-Chauffeur, der seine Kinder zur Schule fährt, wie er den Bus zu fahren hat, wann und wo er abbiegen oder anhalten muss, nur weil er einen Führerschein hat und mit seinem Auto fährt? Gegenfrage 2: geht er jedes Mal, wenn er in Urlaub fliegt ins Cockpit, und sagt den Piloten wie diese zu Fliegen/Landen haben, nur weil er mal als Kind Drachen (Kite) in die Luft steigen lassen hat, oder ob und zu mit seinem Quadrocopter spielt? Fazit: Lieber Chefs/CEOs/CFOs/Manager; Bitte seid Restaurant-Gäste! Gebt eure Bestellung auf! Lasst euch bedienen, denn der Koch weiß wie er zu Kochen hat. Anders formuliert: lasst Profis ihre Arbeit machen! Sagt denen WAS das Ding tun soll und nicht WIE sie dieses Ding machen sollen.
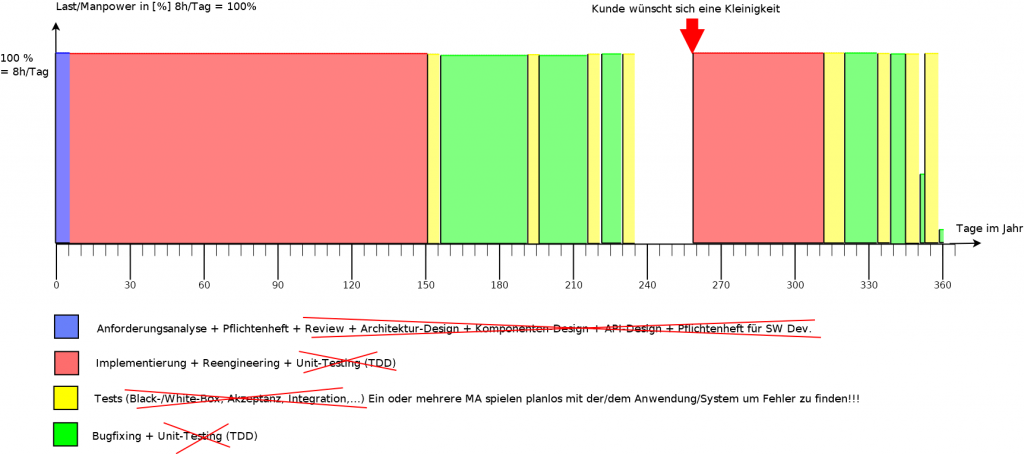
Man nimmt sich genug Zeit fürs Vordenken, Analysieren, Recherche, Review, Planen und Einteilen der Aufgaben + Meilensteine + Abhängigkeiten
Anforderungsanalyse hat keine Lücken, enthält ausschließlich feste, genau, eindeutig definierte Formulierungen
Es gibt ein Pflichtenheft speziell für die Software-Entwickler (es gibt keine offenen Fragen von Software-Entwickler nach Projekt-Beginn)
Abhängigkeiten, Risiken udg. werden abgewogen und verwaltet.
Architektur-, Komponenten- und API-Design wurden genauestens überlegt und entworfen (kein Reengineering danach notwendig)
Man plant Tests: Was, Wann, Worauf, Wie und Womit wird getestet
Wenn Kunden sich Kleinigkeiten wünschen, kann das sofort und in kurze Zeit erledigt werden (keine Staatsaffäre)
Projekt ist sehr wirtschaftlich, man macht satte Gewinne
SW Komponenten können 1:1, oder mit geringer Anpassung, für weitere Projekte verwendet werden
Die Software-Komponenten haben eine sehr hohe Qualität
Die SW-Dokumentationen behalten für sehr lange Zeit (Jahre) ihre Gültigkeit
Wenn genug vorgedacht und geplant wird, muss danach nicht viel/lange implementiert werden.
Eigenschaften von schlechte/mangelhafte/nicht-Existenz von Software-Engineering:
Man nimmt sich kaum Zeit fürs Vordenken, macht kaum Analysen, recherchiert wenig/kaum, lässt keine Reviews machen, plant grob/falsch, Einteilung und Verteilung der Aufgaben passiert Ad hoc nach dem Projekt-Beginn (während Implementierung, (Pseudo-)Testung etc.
Anforderungsanalyse hat große Lücken und ist sehr schwammige, offene, mehrdeutig interpretierbare Formulierungen
Es gibt kein Pflichtenheft für SW Entwickler! Man nimmt das gleiche Pflichtenheft für Kunde und gibt es Software-Entwickler.
Über Abhängigkeiten und Risiken hat man sich kaum oder gar keine Gedanken gemacht, geschweige dessen Abschätzung oder gar Verwaltung
Architektur-, Komponenten- und API-Design entstehen nach Projekt-Beginn, währen Implementierung, und deshalb muss immer wieder Reengineering und Redesign betrieben werden
Tests werden nicht geplant. Test-Units entstehen während, oder gar am Ende der Implementierung, müssen immer wieder ergänzt und/oder „angepasst“ werden („Was nicht passt, wird passend gemacht!“). Zum Testen spielt ein Mitarbeiter so lange herum, bis vielleicht irgendwas nicht so läuft, wie man will, oder irgendwas sich ergibt/zeigt …
Gott bewahre, ein Kunde wünscht sich eine Kleinigkeit. Das kommt eine Staatsaffäre gleich. Es ist so als ob Mount Everest versetzt werden muss. Kein Byte bleibt auf dem Anderen. Jedes Bit wird umgedreht. Reengineerings nach Reengineerings. Überstunden werden notwendig. Andere Projekte werden die Entwickler entzogen … Die Kosten/LOC explodieren!
Das Projekt wirft, wenn überhaupt, gerade noch, ein paar Euros als Gewinn ab, oder die Fa. muss sogar Pönale zahlen
Verärgerte Kunden beschweren sich immer wieder über Bugs/Fehler (Man hat denen Bananaware verkauft), Folge-Projekte bleiben aus
Die SW-Komponenten haben kaum, oder sehr geringe Qualität
Die SW-Komponenten müssen für weitere Projekte grob verändert, oder gar neugeschrieben werden
Änderungen an eine Software-Komponente zwingt die Änderung viele andere Software-Komponenten (Domino-Effekt)
SW-Dokumentationen (falls vorhanden), verlieren ihren Wert, da sich viel zu viel geändert hat, und müssen um oder komplett neugeschrieben werden
Wenn nicht genug Zeit fürs Vordenken und Planen genommen wird, dann muss man viel mehr Zeit für Reengineering und Überstunden in Kauf nehmen
Das kann jeder (behaupten). Man muss nur „CAPS Lock“ (Feststelltaste) drücken und danach „qualität“ tippen. Ergebnis: „QUALITÄT“. Qualität ist eine Einstellung und Haltung. Ständig! Bei jeder Gedankengang und jede Handbewegung! Von Anbeginn bis zum Ende.
Ad hoc, ist keine flache Hierarchie! Sofort zur Tastatur greifen, ist keine flache Hierarchie! Chaos ist keine flache Hierarchie! Jeder ist für tausend Dinge zuständig, ist keine flache Hierarchie! Jeder tut, was er/sie will, ist keine flache Hierarchie! Ständig im Fluss der Gedanken unterbrochen werden (Telefon, E-Mail, Meeting, Kollegen im Stress, …), ist keine flache Hierarchie! Agile ist keine flache Hierarchie! SCRUM ist keine flache Hierarchie! (Theorie zur „Flat Hierarchy“ wurde 1963 in USA von einem Ökonomen erfunden) Mangel an Projekt-Verwaltung ist keine flache Hierarchie! Mangel an Riskmanagement ist keine flache Hierarchie! Mangel an Ressourcen-Planung ist keine flache Hierarchie! Schlechtes, unvollständiges Pflichtenheft mit schwammigen Formulierungen, ohne Review, ist keine flache Hierarchie! Mangel an Anforderungsanalyse ist keine flache Hierarchie! Flache Hierarchie wird chaotischer gegessen als gekocht!
Warum wendet keine Armee der Welt, die flache Hierarchie? Bei Militär sind Effizienz, Geschwindigkeit und Befehlskette extrem wichtig. Warum haben sie keine flache Hierarchie?
Ad hoc, ist nicht Agile! Sofort zu den Tastaturen greifen, ist nicht Agile! Chaos ist nicht Agile! Jeder macht sofort irgendwas/alles, ist nicht Agile! Wenn alle 11 Fußballspieler eines Teams hinter dem Ball herlaufen, ist nicht Agile! Agile wird meistens agiler gegessen als gekocht!
Die Vortäuschung, die Verstellung, von lat. simulatio: die Verstellung, die Heuchelei, die Täuschung, das Vorschützen (eines Sachverhalts), die Vorspiegelung, der Vorwand, Die Vorschiebung; lat. similis: ähnlich, gleichartig, gleich. Eine Simulation gaukelt das Vorhandensein von Etwas, das nicht da ist.
Ein Simulator (Software), vor allem „Dummy“ Simulator, spart auf langer Sicht, Unmengen an Raum, Zeit, Energie, Kabel, Konfigurationen, Installationen etc. etc. und Kosten. Ein Simulator macht einem unabhängig von realem Ding, und man kann sich auf seine Business-Logik konzentrieren.
ACHTUNG: Natürlich sollte irgendwann mal die Software (Business Logik) mit dem echten Ding auch auf Herz und Nieren getestet/geprüft werden, bevor es geliefert wird, oder ins Produktions-System eingesetzt wird!
Ein Modell ist eine stark reduzierte, abstrakte Abbildung der Wirklichkeit. Es ist absichtlich unvollständig.
„In jenem Reich erlangte die Kunst der Kartografie eine solche Vollkommenheit, dass die Karte einer einzigen Provinz den Raum einer Stadt einnahm und die Karte des Reichs den einer Provinz. Mit der Zeit befriedigten diese maßlosen Karten nicht länger, und die Kollegs der Kartografen erstellten eine Karte des Reiches, die die Größe des Reiches besaß und sich mit ihm in jedem Punkte deckte.“ (Jorge Luis Borges, „Von der Strenge der Wissenschaft“ in: Universalgeschichte der Niedertracht und andere Prosastücke, Ffm-Berlin-Wien, ISBN 978-3548029146)
Er/Sie macht die Kollegen und die Firma von sich abhängig.
Was passiert, wenn:
Dieser Kollege die Firma verlässt?
Er längere Zeit krank ist?
Er in Pension geht oder stirbt?
Können andere Kollegen die Köpfe zusammenstecken und herausfinden wie seine Komponenten funktionieren? Wie diese sich verhalten oder zu benutzen seien? Oder müssen die Komponenten (die eigenen Produkte der Firma) mithilfe von Reverse-Engineering auf Funktionsweise analysiert werden? Müssen diese Neu/nochmal (von null auf) entwickelt werden? Muss der gesamte Code gelesen und verstanden werden? Was kostet die Dokumentation an Zeit und Geld für eine Firma? (A) Was kostet das Reverse-Engineering des eigenen Produktes + dessen Neu-Entwicklung und/oder lesen des gesamten Codes? (B) Welche Kosten sind höher: A oder B? Welche (A oder B) bringt größere, längere und teurere Kaskadeneffekte (Zeitpläne und Ressourcen-Teilung/-Planung, Fertigstellungs-Termine bei parallel laufenden Projekte) mit sich? Welche (A oder B) bringt die Termine durcheinander, sorgt/stiftet/produziert Chaos, macht Kunden unzufrieden? Wer zahlt für die entstandene Kosten und Ressourcen-Verbrauch für die Entwicklung eines Produktes das nicht verwendet/eingesetzt werden kann? Wer zahlt für die entstandene Überstunden bei B? Wer zahlt für die entstandenen Pönalen/Vertragsstrafen durch B bei N andere Projekte?
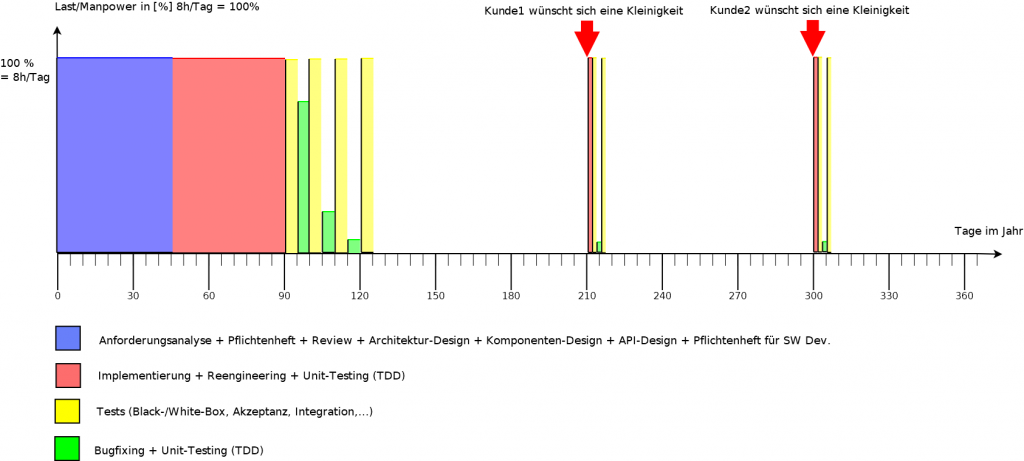
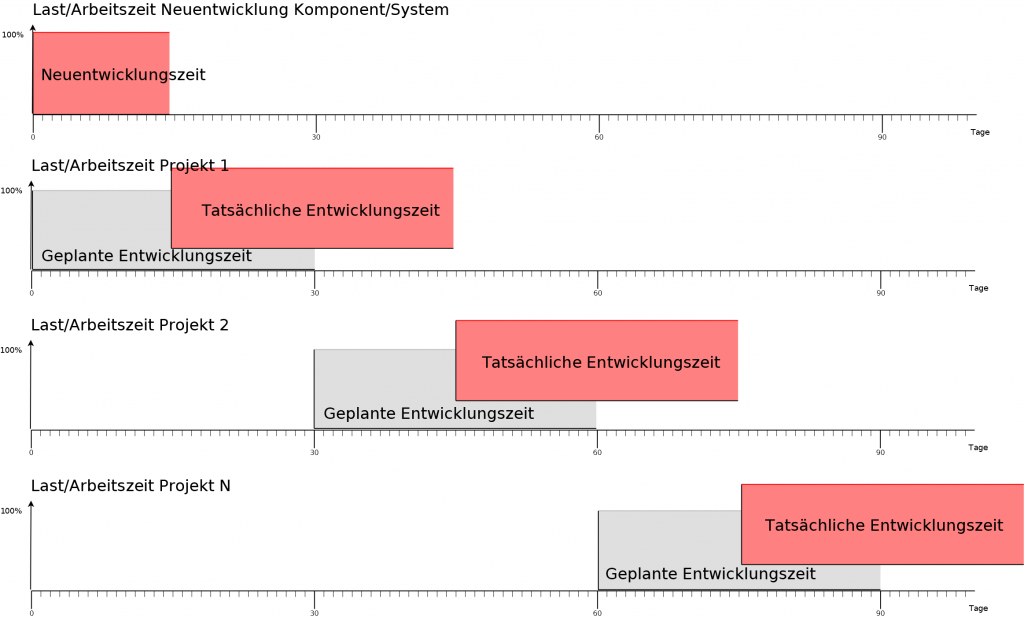
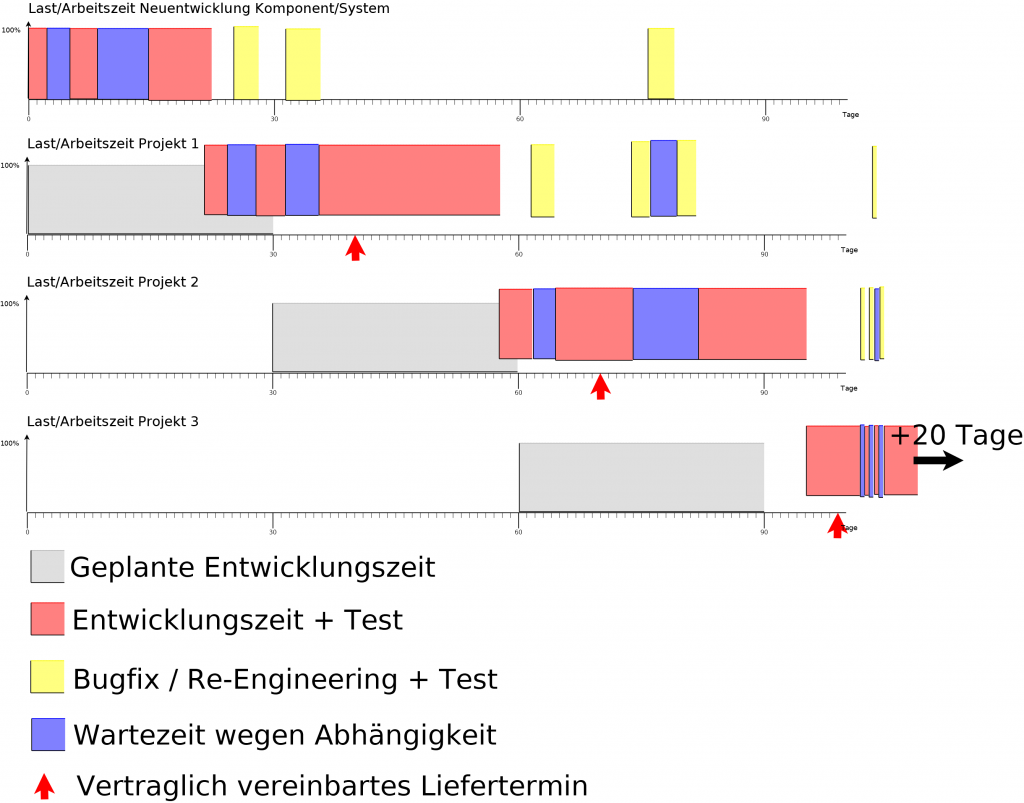
Hier eine einfache Milchmädchen-Rechnung (+Diagramm) für besseres Verständnis:
Naive Annahmen: 1. wir leben in einer perfekten Welt (Nichts geht schief, man muss auf Nichts warten, es gibt keine Bugs, niemand wird Krank, keiner nimmt sich Urlaub, … es gibt keine negativen Überraschungen) 2. die Projekte sind voneinander unabhängig und dauern alle gleich (exakt, nur 30 Tage)
Wie man aus dem Diagramm (für eine „perfekte“ Welt) sieht: Die Fertigstellung jedes Projekts verschiebt sich um 15 Tage (Dauer der Neuentwicklung von Komponente/System des Projekts ganz oben) um 15 Tagen nach hinten! Das bedeutet für alle N Projekte: N × 15 Tage. In unserem Beispiel, bei 3 Projekten, bedeutet das 45 Tage (eineinhalb Monate) insgesamt.
Wir leben aber in keine perfekte Welt!
1. Manche Projekte sind voneinander abhängig (Projekt A ist von Projekt B abhängig, und Projekt B ist von Projekt C abhängig, usw.): A ⇒ B ⇒ C ⇒ … 2. Krankheit, Urlaub, Todesfall 3. Verzögerung durch Bugs (z. B. Memoryleak) 4. zuständiger Fachexperte für XYZ, der Mitarbeiter X, ist auf einer Baustelle von einem Kunden in Land Y und kommt erst in einer Woche zurück 5. Wegen Covid-19, einem Schiff das in Suezkanal feststeckt, Produktionsverzögerung, Lieferschwierigkeiten für eine Hardware-Komponente, kann man Projekt XY nicht fertigstellen oder testen 6. Die Firma VUDU wird an Firma CONYAK verkauft und ändert die Lizenzierungen für das KI-System von VUDU. Das System muss nun ersetzt werden, oder darauf muss komplett verzichtet werden 7. Es stellt sich in reale Umgebung (Prototyp-System) heraus, dass externes/gekauftes System XYZ für die Aufgabe ABC ungeeignet ist oder dessen Laufzeitkomplexität viel zu hoch als erwartet ist (z. B. Taktzeiten können nicht eingehalten werden, in zeitkritischen Systemen werden harte Zeitschranken durchbrochen) 8. Es wurde aufgrund falscher Annahme(n) viel Code geschrieben, jedoch bei Developer-Tests stellt man am Ende fest: XYZ ist gar nicht imstande ABC zu tun 10. Unterschiedliche Softwareentwickler arbeiten an unterschiedliche Projekte und haben von andere Projekte, dessen Lösungsansätze, Paradigmen und/oder Konzepte keine Ahnung 11. Es gibt Spezialisten für Teilbereiche, nicht jeder kann alles, was der Andere kann. Der Spezialist wird aber für Projekt X benötigt und kann sich nicht auch noch um andere Projekte (Aufgaben) gleichzeitig kümmern 12. Der Tester bzw. die Test-Abteilung muss sich zuerst um Projekt X kümmern. Projekt Y muss warten bis es zum Testen dran ist 13. … und vieles mehr
Wie man in obigem Diagramm sieht: Die Neuentwicklung des Komponenten/Systems (ganz oben) verursacht enorme Chaos und Verzögerung in Projekt 1, was wiederum enorme Chaos und Verzögerung bei Projekt 2 verursacht. Da das Projekt 3 von Projekt 2 abhängig ist, braucht man sich nicht wundern, dass die Entwicklung dessen erst nach dessen Liefertermin gestartet werden kann. Obwohl für die Liefertermine für jedes Produkt 10 Tage als Puffer geplant waren (was ich in der Realität leider noch nie erlebt habe!). Das ist die Folge von: Nichts dokumentieren (weil „die Kunden nicht fürs Dokumentieren Zahlen“).
Warum? Dazu folgende (wahre) Geschichte: Es gab mal eine kanadische Firma namens AECL (Atomic Energie of Canada Limited), welche medizinische Bestrahlungsgeräte baute. Unter anderem das Therac 25. Das A und O der Bestrahlungsgeräte lautet: Soviel Strahlung wie nötig, so wenig wie möglich! Immer wieder kontaktierten Mediziner die Firma AECL und beklagten sich über Bestrahlungsüberdosen. Von der Firma AECL kam stets die gleiche Antwort: „Bei uns funktioniert es“ und „Es muss an euch liegen“.
Mehrere (mind. drei) Patienten sind wegen Bestrahlungsüberdosis durch Therac 25 ums Leben gekommen. Einige Patienten verloren ihre Glieder nach Not-Amputationen (direkt nach Bestrahlungsüberdosis durch Therac 25), weil das Gewebe an bestrahlte Stelle komplett verbrannt war (= totes Fleisch!). Einige Patienten könnten nie wieder ihre Extremitäten (Hand, Arm, Fuß, Bein) bewegen oder spüren, da die Nerven durch die Bestrahlungsüberdosis komplett verbrannt waren (= tote Nervenzellen!). Z. B. Marietta, eine 61-jährige Frau aus Georgia, wurde wegen Lymphknoten in 1985 mit 15000Rad statt 200Rad (75-fach höhere Dosis) bestrahlt. Sie könnte nie wieder ihre Schulter oder Arm bewegen oder spüren.
Die Entdeckung der Fehler: Anmerkung: In USA müssen die Mediziner vor ihrem Medizinstudium ein technische oder naturwissenschaftliches Studium erfolgreich absolviert haben (Dipl.-Ing. früher in Österreich), sonst dürfen sie nicht Medizin studieren. In einem Krankenhaus in USA, wurde eine Radiologin (die auch Physikstudium absolviert hatte), auf die Bestrahlungsüberdosen durch Therac 25 aufmerksam. Sie notierte die Daten der Vorkommnisse und sah ein Muster darin. Daraufhin bat sie einen Kollegen (Mediziner) der sich mit Elektronik und Computer auskannte um Hilfe. Sie entwickelten einen systematischen Testplan, und testeten den Therac 25 gründlich. Sie haben gleich mehrere reproduzierbare Fehlverhalten festgestellt und AECL sowie die Behörden informiert. Erst jetzt wurden die Fälle von der Behörde und AECL untersucht!
Die Fehler: Es wurden mehrere Fehler gefunden:
Mechanischer Fehler!
Mehrdeutige, in die Irre führende Anzeige bzw. Texte/Begriffe
Synchronisations-Fehler (angezeigter neuer Dosis-Wert entsprach nicht den im Speicher für die Bestrahlung angewendeter Wert, d. h. alter Dosis-Wert wurde für die Bestrahlung angewendet)
Zustands-Transitions-Fehler (die Positionierung verschiedene Magneten dauerten 8 Sekunden, die Bestrahlung wurde aber sofort eingeleitet, dadurch hatte jede Bestrahlung 8 Sekunden länger als erwartet gedauert, beginnend an falsche Position/Stelle)
Flags wurden ignoriert (nach grobe Positionierung wurde die Feinpositionierung der Magneten ignoriert)
Fehlermeldungen waren nicht aussagekräftig, waren nicht verständlich dokumentiert, ergaben für die Anwender (Mediziner) keinen Sinn!
usw. usw. usf.
Wie könnte das Alles nur passieren?
Einbildung (Gehabe und Einstellungen wie: „Ich bin so super!“, „Ich bin Perfekt und alle Anderen sind Idioten“, „Ich weiß alles, alle Anderen wissen nichts“ und „Ich bin der beste Programmierer auf der Welt!“, …)
Sätze und Glaubens-Gedanken (statt anständige Tests) wie:
„Es funktioniert.“
„Es hat funktioniert.“
„Bei uns funktioniert es.“
„Es muss an euch liegen.“
„Software-Tests“ von AECL basierten auf Vermutungen und „Schauen wir mal, ob es so funktioniert wie wir uns gedacht haben“, anstatt auf systematische professionelle fundierte Analysen! Das Ziel deren Tests war zu beweisen, dass es funktioniert, und nicht das Finden von Fehler!
Der neue Programmierer nutzte die SW-Komponenten des alten Programmierers (welcher AECL verlassen hatte), ohne wirklich zu wissen, wie diese Entworfen waren, und wie diese richtig einzusetzen waren (Race Conditions, Sync. Fehler, Flags-Änderungen ignorieren udg.)
Unverantwortliche Projekt-Leiter und Manager („Hauptsache Billig!“ Manier) die über die Tragweite ihrer Entscheidungen nicht bewusst waren (und Warnungen der Techniker/Experten ignorieren): nahezu alle Hardware-Überwachungskomponenten des Vorgängermodells wurden entfernt und durch Software-Checks ersetzt (wegen höchstens einige 1000 $ Hardwarekosten haben einige Menschen ihren Leib und Leben verloren! Tolle Kostenreduzierung!)
Bei Therac 25 wurde ein komplett neues eigenes Betriebssystem eingesetzt, welches noch jung war („Kinderkrankheiten“), Fehler enthielt unddie AECL Mitarbeiter keine Erfahrungen damit hatten. Kommerzielle Betriebssysteme wären bekannt und auch länger getestet gewesen (Erfahrungswerte, Bekanntheit, Dokumentationen, …). Aber auch hier hat AECL sich „viel Kosten erspart“.
Konsequenzen: 1985-1987 wurden von FDA (Food and Drug Administration, US-Behörde) und CDRH (Center for Devices and Radiological Health, US-Behörde) weitreichende Reformen durchgeführt (Überwachung von Software-Entwicklung und das Testen, sowie Verschärfung der Freigabeprozedur für neue Geräte).
Die Moral der Geschichte:
Hört auf zu denken/sagen „Es funktioniert“ oder „Es hat funktioniert.“
Hört auf zu sagen „Bei uns funktioniert es.“ oder „Es muss an euch liegen.“! Davon kann der Kunde sich Nichts kaufen!
Testet! Testet! Testet! Und zwar gründlich, analytisch, systematisch und fachmännisch. Die Aufgabe von Testen ist Fehler zu finden, und nicht zu beweisen das „es funktioniert“. Es gibt genug Paradigmen, Konzepte, Module, Best Practices, Standards und Konventionen für ein gründliches, systematisches, analytisches, fachmännisches Testen (TDD, Unit-Testing, Test-Doubles, Mocks & Fakes, Digital-Twins, Fehler-Simulatoren, …)
Warum? Dazu folgende (wahre) Geschichte: Es gab mal eine europäische Trägerrakete namens Ariane 4. Diese hatte ein Modul namens SRI (Inertial Reference System), welches für die Berechnung der Flugbahn zuständig war. Das SRI Modul war bestens getestet. Die Mission Ariane 4 war erfolgreich (somit hatte SRI in Produktion-System „funktioniert“). Dann baute man Ariane 5 mit stärkeren Triebwerke. Da das SRI Modul von Ariane 4 getestet und erfolgreich erprobt war, wurde es einfach in Ariane 5 eingesetzt. Ergebnis: in Sekunde +41 nach Zündung (Ignition) wurde der automatische Selbstzerstörungsmechanismus von beiden Onboard Computern ausgelöst und zerstörte die Rakete. Grund: Ariane 4 Computer war ein 16 Bit System. Ariane 5 Computer war ein 64 Bit System. Bei der Berechnung der Flugbahn wurde ein 64 Bit Float Wert (Fließkomma-Zahl) an SRI Modul übergeben ⇒ Stack Overflow! Die Triebwerke schlugen von der eine (IST-Wert) Richtung in das Extreme, andere Richtung (overflow SOLL-Wert). Durch die große Masse und hohe Geschwindigkeit (Impuls, Energie) wäre Ariane 5 auseinandergebrochen, weshalb der automatische Selbstzerstörungsmechanismus die kontrollierte Sprengung ausgelöst hat. Wie man sieht: „Es funktioniert.“, oder „Es hat funktioniert.“ bedeutet rein gar Nichts! Fun Fact 1: Nach Sekunde +36 war eine Berechnung der Flugbahn durch das SRI Modul gar nicht notwendig gewesen, und hätte somit von „Haupt-Computern“ abgeschaltet werden können. Fun Fact 2: Die Herstellungskosten für die Rakete und die Satelliten beliefen auf ca. 500 Millionen Dollar. Da keine kommerzielle Fracht an Bord war, sondern „nur“ Forschungssatelliten, war der Flug nicht versichert worden. Fun Fact 3: Die Entwicklung der Rakete alleine hat 10 Jahre und 7 Milliarden Dollar beansprucht. Resultat: 10 Jahre Entwicklungszeit + 7.500.000.000 $ wurden nach nur 41 Sekunden vernichtet, weil man sich dachte „Es hat funktioniert.“.
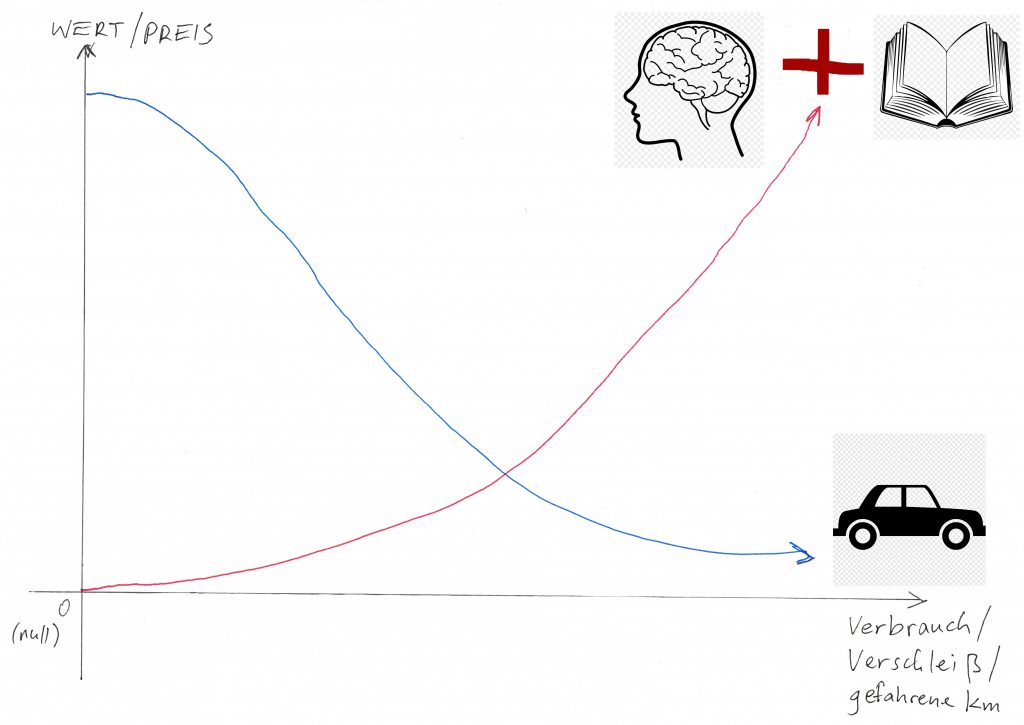
Ist jeder, der Zuhause kocht ein Haubenkoch? Ist jeder der an seinem Auto/Motorrad herumschraubt ein Auto-/KFZ-Mechaniker? Ist jeder der mit einem Lötkolben in einem Radio/Fernseher herum lötet ein Elektroniker?
Man kann ja selbst Fliesen legen und Küchenregale montieren. Ja! Klar! Aber wer macht es besser und professioneller, mit kaum fataler oder sichtbarer Fehler? Der Profi der das jeden Tag seit zig Jahren macht, oder man selbst?
Conclusio: Nicht jeder der Code schreibt, ist auch ein professioneller Software-Entwickler! Software-Entwickler > Programmierer > Code-Schreiber.
„Jeder kann Bücher lesen. Nicht jeder der Bücher lesen kann, kann auch ein (gutes/Bestseller) Buch schreiben. Jeder kann Code schreiben. Nicht jeder der Code schreiben kann, kann auch Code lesen.“ (Zitat von meinem geschätzten ehemaligen Kollege Manfred)
Damit man ein gutes Buch schreiben kann, muss man viele gute Bücher gelesen haben. Damit man guter Code schreiben kann, muss man viele (IT) Bücher sowie Code gelesen haben.
Ein Autor bzw. eine Autorin schreibt Bücher für die Leserinnen. Ein Software-Entwickler schreibt Code für:
Sich selbst, da er/sie es vielleicht in einem Monat oder einem Jahr wieder lesen, verstehen und ändern muss
für seine Kolleginnen, da sie es vielleicht lesen, verstehen und ändern müssen
für die „Nachwelt“ (neue Kolleginnen in der Zukunft, wenn man nicht mehr in der Firma ist)
und zum Schluss für den Compiler und CPU (oder JVM, CLR oder sonstige virtuelle Maschinen)
In jede Firma, jede Abteilung und auf jedem Tisch und in jedem Kanban-System, gibt es einen unsichtbaren Damm. Hinter dieser Damm sammelt sich ein trüber stinkender Schlamm, bestehend aus all die Fehler, falsch oder schlecht angegangene/gelöste Aufgaben, falsche Annahmen, falsche Entscheidungen, falsch (nicht)kommunizierte oder (nicht)verstandene Dinge, und all die nicht erledigte aber wichtige Dinge. Irgendwann bricht einer dieser Dämme und der Kaskadeneffekt beginnt. Der Aufgaben-Flut zeigt nun den Schlamm, wie ein Orkan die Existenz der Luft:
es müssen immer mehr Entwickler eingestellt werden
die Entwickler müssen immer mehr Code von bestehenden Komponenten ändern (oder hinzufügen)
die APIs und Framework-Komponenten ändern sich wöchentlich oder gar täglich
die Entwickler betreiben immer wieder Reengineering
die Entwickler müssen immer mehr Überstunden machen
die Entwickler lesen mehr Code (Implementierung-Details) als sie schreiben (der Kunde zahlt nur fürs Schreiben!)
die Entwickler werden täglich, ja sogar stündlich über bestimmte Bugs oder Problemen bei Kunden befragt
die Entwickler müssen immer mehr Telefonate, E-Mails udg. beantworten, und werden dadurch in ihrem Gedanken-Fluss unterbrochen
die Entwickler können sich nicht einmal für zwei Stunden, Zeit für tiefgründiges Nachdenken/Überlegen nehmen
wöchentlich, täglich, ja sogar stündlich, gibt es neue Versionen
der Compiler benötigt immer länger fürs Übersetzen (eine Sekunde ist für einen Computer eine Ewigkeit!), die Startzeit mal zwei!
das Programm benötigt immer mehr Speicher (HDD & RAM)
das Programm wird immer langsamer, und dadurch steigen die Wahrscheinlichkeiten für Nebeneffekte und neue (unerwünschte) Verhalten (vor allem bei komplexen, zeitkritischen Systemen)
die benötigten PCs für die Software benötigen immer mehr CPUs (Cores)
bei kleinen Anpassungen/Änderungen für einen Kunden, beschwert sich mindestens ein anderer Kunde über neuen Fehler (von einer Funktion, die bis dahin immer tadellos funktionierte)
Hotline ist ständig vollbeschäftigt, muss lange Telefonate mit enttäuschten/verärgerten Kunden/User führen
Techniker, Service-, Troubleshooting- und 3rd-Level-Support-Kollegen haben immer mehr zu tun, oder sind ebenfalls ständig beschäftigt
man sucht immer mehr und länger nach Fehler/Bugs und unerwartetes/unerwünschtes Verhalten
man benötigt für egal welche Tests, immer irgendwelche Hardware (SPS/PLCs, Sensoren, Netzteile, USB-Dongles, spezielles Kabel udg.) und kann diese Tests nicht durchführen, wenn das eine oder andere Hardware fehlt
und vieles mehr
Jetzt, wo der Damm gebrochen ist, ist man die Aufgaben-Flut ausgeliefert. Man hat keinerlei Kontrolle über die Aufgaben, wie ein Autofahrer mit über 100 km/h auf Glatteis. Ab jetzt kann man nur taktisch, Ad hoc und „husch husch“ (eher „Pfusch Pfusch“) auf die Aufgaben reagieren. Für strategisches und langfristiges Planen, Entwerfen und Programmieren, sowie dessen (Teil)Automatisierung ist es erstens zu spät, und zweitens keine Zeit da, da die Kunden warten. Das Dach brennt! Die Entwickler springen von einer dringenden Aufgabe zu Nächste, wie ein Ping-Pong-Ball. Die Entwickler laufen gestresst von einem Bugfix/Reengineering zum Anderen, wie eine Feuerwehr-Truppe die zig Brände an unterschiedlichen Orten gleichzeitig löschen muss. Die Kosten steigen. Für neue Projekte ist kaum Zeit da. Für Modernisierung (z. B. Umstieg von Windows Forms auf WPF/UWP) schon gar nicht. Ein Liefertermin nach dem Anderen wird überschritten. Die Firma beginnt nun auch noch Pönalen zu zahlen. Die Kunden sind verärgert und unzufrieden. Die Inhaber, CEOs, CFOs, Abteilungsleiter und Team-Leader sind gestresst und verärgert. Die Entwickler auch. Eine: lose-lose-lose Situation. Man hat sich Niemals-Endende-Baustellen geschaffen. Da kann man sich selbst gratulieren.
Hässlicher Code ist wie ein Kondom, Taschentuch oder Toilettenpapier. Man kann es nur einmal verwenden.
Guter Code hat einen Mehrwert. Wie die Weihnachtskeks-Schablonen/-Formen kann man ihn immer wieder verwenden/einsetzen.
Nomen est omen: Eine Funktion oder Prozedur tut genau das, was der Name sagt, nicht mehr und nicht weniger. Gilt auch für Namensräume, Klassen, Events, Variablen etc. Der Name muss 100%ig selbsterklärend, eindeutig und unmissverständlich sein.
Eleganter Code ist: kurz, klar, einfach, eindeutig, einprägsam und effizient. Alles andere ist plumper (dahin-gerotzter) Code.
Intelligente Software-Entwickler schreiben den einfachsten, kürzesten und flachsten Code (Eleganz!). Schlechte Software-Entwickler schreiben die kompliziertesten, längsten Zeilen und mehrfach verschachtelter Code.
Faule, aber clevere Software-Entwickler haben jeden Tag weniger zu tun als der Tag zuvor, während fleißige, aber schlechte Software-Entwickler jeden Tag gleich viel oder sogar mehr als der Tag zuvor tun müssen. (Siehe „Wenn die Dämme brechen“!)
Guter Code wird getestet, denn nur guter Code kann getestet werden. Schlechter Code kann gar nicht getestet werden. Die Aussagekraft der Tests von schlechtem Code = 0.
Code-Optimierung erfolgt erst nach vollständiger Implementierung und erfolgreichem Testen, nicht davor oder währenddessen.
Man muss sich Vieles überlegen und gut vordenken, bevor man einen Zug macht. Man muss sich auch Vieles überlegen und gut vordenken, bevor man ein paar Zeilen Code schreibt.
Intelligenz ist: wenn jemand oder etwas (relevante/wichtige) Fragen stellt. Speicherung von Information/Wissen ist kein Zeichen für Intelligenz (sonst wäre die Google-Suchmaschine das intelligenteste Ding auf Erde).
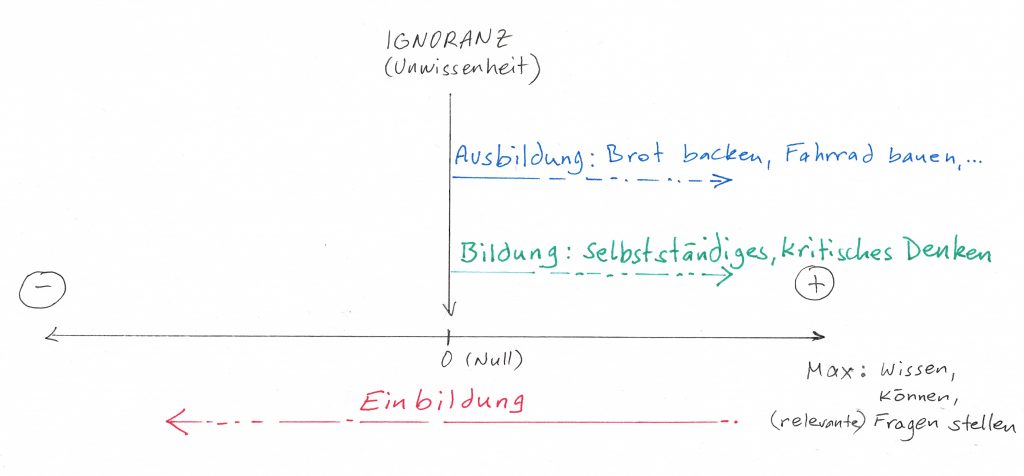
Das Gegenteil von Wissen ist nicht Ignoranz (Unwissenheit), sondern fester Glaube/Überzeugung an falsche Informationen/Theorien.
Es gibt Bildung, Ausbildung und… Einbildung: Mit Bildung kann man selbstständig kritisch denken, aber kein Brot backen oder Fahrrad bauen (Philosophie, Literatur, schönen Künste,…). Mit Ausbildung kann man Brot backen und Fahrrad bauen, aber nicht selbstständig kritisch denken (Lehre, Automatisierungs-Studium,…). Einbildung macht Bildung und Ausbildung zunichte. Einbildung benötigt keine Lehranstalt für höchste Zeugnisse. Jeder kann sich Einbilden, was er/sie will.
Der Autor dieses Buches, ein französischer Mediziner, Anthropologe, Psychologe, Soziologe und Erfinder Gustave Le Bons, gilt als einer der (wichtigen) Begründer der Massenpsychologie.
Kurz: in seinem Buch schreibt der Autor über seine Beobachtungen und dessen Erkenntnisse über: wie eine Gruppe von Menschen (die sich weder kennen, noch irgend eine Gemeinsamkeit haben) als Kollektiv denkt, sich verhält, und gelenkt wird. Die „niedrigste Instinkte/Triebe“ (Angst, Wut, Hass, …) nehmen überhand, und die Gruppe beginnt gemeinsam emotional statt rational zu denken und handeln.
Wenn man chronologisch die Themen Medien und Public Relations/Propaganda lernen und verstehen möchte, sollte man mit diesem Buch beginnen.
VORSICHT: der Autor schrieb dieses Buch im Zeitgeist des 19. Jahrhunderts (Gene, Vererbung, Nationalismus, Darwinismus etc.)! Er verwendet oft Wörter wie „Rasse“ udg.! Solche Begriffe, auch wenn sie aus heutigem Sicht/Wissen sehr kritisch sind, dürfen einem davon nicht abhalten das Buch (weiter) zu lesen.
Bei einem Vortragsvideo von Univ. Prof. Harald LESCH auf YouTube, wo es um die Umwelt ging, hat er das Buch „Nationales Sicherheits Amt NSA“ (von Andreas ESCHBACH) erwähnt. Da er, so schien es mir, davon begeistert war, dachte ich mir, dieses Buch muss ich auch lesen. Zuerst dachte ich mir: „Ich bin eh von Fach! Ich kenne mich eh aus. Was werde ich schon aus diesem Buch (Neues) lernen?“ (Einbildung!) Da ich von Prof. LESCH sehr viel halte, entschied ich mich doch das Buch zu kaufen und lesen … Es war kein Fehler! Als ich das Buch bis ca. Seite 45 gelesen habe, könnte ich an Nichts Anderes denken! Dieses Buch, die Geschichte hatte mich voll gepackt.
Nachdem ich das Buch fertig gelesen habe, habe ich noch weitere siebenmal das Buch bestellt und verschenkt.
Die Geschichte in diesem Buch, ist die einfachste und effektivste Methode, Menschen die keine IT’ler sind oder geringes Sicherheits-Bewusstsein haben, beizubringen, warum das Thema IT-Sicherheit, Privatsphäre, Facebook, Google, Amazon, bargeldlose Zahlung, Massenüberwachung von E-Mails, SMS, Telefonate, „soziale“ Medien udg. usw. wichtig und kritisch sind.
Alles (aus) Gold glänzt, aber nicht alles was glänzt ist Gold. Alle Nüsse sind rund, aber nicht alles, was rund ist, ist eine Nuss. …
Jeder kocht Zuhause. Aber deswegen ist nicht jeder ein Koch. Jeder kann ein Auto-Motor oder -Getriebe zerlegen. Aber deswegen ist nicht jeder ein Auto-Mechaniker. Jeder kann mit einer Lötpistole (oder einem Lötkolben) in einem Radio oder Fernseher herum löten. Aber deswegen ist nicht jeder ein Elektroniker. Jeder kann mit einem Taschenrechner umgehen, aber deswegen ist nicht jeder ein Mathematiker. Jeder kann beim Schachspielen drei Züge vorausdenken, aber deswegen ist nicht jeder ein Profi-Schachspieler. …
Nur weil man in eine Objekt-orientierte Programmier-Sprache wie C++, Java oder C# Code schreibt, heißt es noch lange nicht, dass das Programm (der Code) Objekt orientiert ist!
Ich habe C# Code in „professioneller“ Umgebung (Industrie) gesehen und gelesen … Es war SPS/PLC Programmier-Stil in .NET/C# ! Ja, ich weiß! Ich hätte es selbst nicht geglaubt, wenn ich den Code nicht persönlich gelesen hätte (eine mind. viermonatige Tortur! Eine pure Verschwendung von teurem Arbeits- und Lebens-Zeit! Dazu noch: Augen- und Hirn-Schmerzen sowie schlaflose Nächte! Das wünsche ich niemandem!). Ich selbst habe früher Mal, als Autodidakt, Visual Basic programmiert, ohne je von OOP, Klassen, Interfaces, Kapselung, Vererbung, Polymorphismus usw. je gehört/gelesen oder verstanden zu haben. Es hat (damals für mich) „funktioniert“. Dessen Code-Qualität war gleich 0 (null), bzw. eher am Ende der Minus-Bereich, je-nach Code-Qualitäts-Bewertungs-System.
Jede Programmier-Sprache hat seine Geschichte, geschichtliche Entwicklung, Konzepte, Paradigmen sowie „Eigenheiten“ und „Features“.
Es ist von großer Wichtigkeit die Geschichte einer Programmier-Sprache, dessen Sprach-/Programm-Elemente, Paradigmen und Konzepte zu kennen. Erst dadurch kann man sie 1.) begreifen und 2.) wissen Wann, Wo, Wie und Warum ein Programm-Element (Pre-Compiler-Symbol, Konstanten, Enumerations, Properties, Delegates, Events, usw.) oder OOP-Muster zu verwenden sei.
Jemand der C++ beherrscht kann nicht automatisch auch Java oder C# beherrschen. Jemand der Java beherrscht kann nicht automatisch auch C# beherrschen.
Beweis durch Widerspruch: Annahme: Wer C++ beherrscht, kann automatisch genauso Java/C# beherrschen. Vergleiche in alle drei Sprachen werden mit dem Schlüsselwort „if“ durchgeführt. Gegeben:if ( person != null && person.Name == "Bob" ) und die Variable person ist null. In C++ (bis mind. C99 Standard) wird ein Fehler ausgelöst (Null Reference), weil person.Name == ... ausgeführt wird, und die Variable person ist/referenziert ja null! Man kann nicht auf Etwas das NULL ist, auf dessen Eigenschaft/Variable/Methode (in diesem Fall „Name“) zugegriffen werden.
In Java und C# hingegen geht es gut, weil beide Sprachen den sogenannte „Kurzschluss-Ausschluss-Verfahren“ beim Vergleichen anwenden (was in C++ je nach Compiler und Standard nicht gibt/gab). Das heißt, nachdem „person != null“ Falsch (false) ist, und der nächste Vergleich Konjunktiv („&&“) gebunden ist, wird der Rest („person.Name == ...„) nicht mehr ausgewertet, da es gilt: false && True_Or_False ==> false oder binär (0 && (0 || 1) ==> 0). („==>“ steht hier für „daraus folgt“). Daher der Name: Kurzschluss-Ausschluss-Verfahren. Quod erat demonstrandum! (1)
Nun unterscheiden sich auch die Semantik (Bedeutung) und somit das Verhalten zwischen Java und C# auch noch: Gegeben: person ist nicht null UND der Inhalt von person.Name ist „Bob„.
In Java: person.Name == "Bob" erzeugt einen neuen anonymen immutable String Object(eine Konstante) von Typ String mit dem Inhalt „Bob“ und vergleicht den Referenzen von person.Namemit der Referenz von anonymen immutable String Object. Das Resultat ist: false, da jedes Object auf eine andere Adresse zeigt, und somit es sich um zwei unterschiedliche Referenzen handelt.
In C# werden hingegen die Inhalte von beiden immutable String Objekten (person.Name und anonymen String Objekt, = Konstante) durch den Operator „==“ verglichen. Das Resultat ist: true, da der Wert von „person.Name“ inhaltlich dem anonymen immutable String Objekt (Konstante) „Bob“ gleicht. Kurz: Strings in Java und C# sind immutable Objects (siehe und vergleiche ECMA-334, Abschnitt 8.2.1 „Predefined types“ mit Java-String von Oracle!) In Java müsste der Code so umgeschrieben werden damit es funktioniert: if (person != null && person.Name.equals("Bob"))… Quod erat demonstrandum! (2)
Dazu kommt noch…
Das Kennen von Schlüsselwörter (if, else, new, while, …) sowie die Grammatik (Syntax) einer Programmiersprache reicht nicht aus um es zu „können“. Man kann dadurch den Code höchstens lesen. Um eine Programmiersprache zu beherrschen („können“), sind daher weitere Kenntnisse unbedingt erforderlich:
Paradigmen und Konzepte (Heap vs. Stack, Class vs. Struct, Copy-by-Value, Copy-by-Reference, Immutable Types, OOP Design Patterns, Garbage-Collector/-Collection, Exception-Handling, Generizität, statischer vs. dynamischer Datentyp einer Variable,…)
Compiler (Was, Wie und Wo wird optimiert? Was wird während Compilierung und was während Runtime (Laufzeit) übersetzt, geprüft, ausgeführt? Z. B. findet in Java (ab Vers. 1.5 = Java 5) die Typ-Prüfung bei generische Typen erst zur Laufzeit (Runtime), weshalb der Compiler (da Java Type-Safety garantieren möchte) während Compilierung „Warning“ ausgibt. Bei C# jedoch findet die Typ-Prüfung bei generische Typen während Compilierung statt, und sollte Type-Safety nicht gegeben sein, gibt der C#-Compiler „Error“ aus. Siehe und Vergleiche auch Just-In-Time sowie Ahead-Of-Time Compiler! Zusätzlich: C# ermöglicht direkten Zugriff und Manipulation auf Speicher und dessen Inhalt (nur wenn der Code-Block mit „unsafe“ Schlüsselwort, sowie die Assembly als „Unsafe“ markiert wird), was in C++ normal/business as usual ist und Java gar nicht anbietet!
Ich habe ein Modem/Router im Jahr 2017 von A1 erhalten. Bis heute (09.07.2021) hat es nie ein Update dafür gegeben, obwohl wöchentlich, manchmal täglich, neue Sicherheitslücken in irgendwelche Software-Modulen, Internet-Protokolle udg. gemeldet und veröffentlicht werden. Wie kann das sein?
Die Modems/Router von Internet Provider (A1, Telekom, UPS, …) sind extrem billige Geräte. Sie nutzen, wie viele andere Internet-fähige Geräte (Switches, NAS, Tablets, Smartphones, Smart-TVs, …) Software-Module die „open source“ sind und für kommerzielle Zwecke sogar gratis verfügbar sind. Und hier liegt das Problem. Falls in diese Software-Module Sicherheitslücken udg. erkannt und beseitigt werden, dauert es lange, wenn überhaupt, dass die Internet-Provider einen Sicherheits-Patch/-Update erstellen und liefern. Leider! Wie mein Modem-Router.
Aus diesem Grund verwende ich seit 2007 mein eigenes Firewall-System/-Gerät, welches ich hinter dem Modem/Router von meinem Internet-Provider anschließe.
Ports blockieren (nach Innen und Außen) die nicht notwendig sind
verlässlich, einfach und immer aktuell IP Pakete blockieren/wegwerfen die infektiös sind (Attacken: DOS, DDOS, Kill-Bits, Trojaner, Viren, …)
verlässlich und einfach Werbe-Fotos/-Videos blockieren
verlässlich, einfach und immer aktuell einzelne URLs, IP-Adressen oder Netzwerke blockieren, welche für ihre Schad-Programme (Viren, Trojaner udg.) bekannt sind
einfach ganze Gruppen an Inhalte (Web-Adressen) sperren/filtern, wie z. B.: Casino, Viagra, Warez, …
Unsichtbare Web-Cache (Proxy) der Bilder und andere Dateien (wie z. B. Google-Logo-Bilder) beim ersten Besuch/Aufruf einer Webseite speichert –> ab dann kommen diese Inhalte von meinem Firewall/Web-Cache und nicht aus dem Internet –> schneller surfen & große Dateien herunterladen
DHCP Dienst: meine Geräte haben/bekommen immer die gleichen privaten IP-Adressen (seit 2007)! Ich muss meine Netz-Laufwerke (NAS), Drucker, Scanner etc. nie konfigurieren (obwohl ich inzwischen 6 Mal umgezogen/übersiedelt bin). Ich muss nur die MAC-Adressen neue Geräte, die ich mir kaufe, einmalig eingeben, und die Regeln (was darf dieser und was nicht) für diese festlegen.
Traffic Shaping: verteilt den Datenlasten zugunsten von Web-Surfen oder Emails-Lesen automatisch, während große Dateien von irgendeinem PC oder Notebook heruntergeladen werden.
Verbieten von „ET nach Hause telefonieren“: Ich kann mir nach der Installation von neuem App oder Anwendung auf dem PC, genau anschauen, wohin/mit wem sich dieses Verbinden will und welche Daten sie zu senden versucht. Je nach Bedarf erlaube ich den Zugang nach Außen durch diese App/Anwendung oder ich blockiere es.
Das Betriebssystem, die Modulen und Regeln sind immer Up-to-Date (aktuell).
Intrusion Detection System (IDS): Einbruchs-Versuche in meinem Netz werden protokolliert (wann, IP, Port, welche Art), verhindert und ich könnte sogar den Absender zurück-attackieren lassen (juristische Grauzone!).
Alles, was man dazu benötigt ist, ein kleiner Rechner, mit sehr geringem Strom-Verbrauch und mindestens zwei Ethernet-Büchsen (RJ-45) und eine eingebautes (Onboard) Wi-Fi Modul mit Antenne.
Als Firewall-Betriebssystem kann man dann IPFire oder OPNsense oder pfSense Community installieren. Hände weg von eingestellte Systemen wie m0n0wall oder IP Cop! Diese werden seit langem nicht mehr weiterentwickelt (Rest In Peace m0n0wall! Du hast mir das Leben als GBH-Admin um einiges leichter gemacht).
„Sicherheit“ ist nur ein Gefühl. 100 prozentige Sicherheit gibt es nicht! Niemand ist 100 prozentig neutral!
Die Schweizer Firma „Crypto AG“ stellte Maschinen für professionelle Verschlüsselung her. Diese wurden sowohl von Firmen, aber auch von Staaten, Nachrichten-Dienste, internationale Organisationen und Konzerne eingesetzt.
Irgendwann stellte sich heraus, dass die Crypto AG von BND und CIA betrieben und deren Verschlüsselungs-Maschinen/-Methoden/-Algorithmen absichtlich mit „Lücken“ versehen waren …!
Die Ereignisse am 11. Sept. 2001 haben Einiges in USA und weltweit verändert. Hier möchte ich nur auf 5 Dinge eingehen:
Freedom of Information Act wurde ausgehebelt/ausgesetzt: Früher dürfte man als US-Bürger zu einem beliebigen US-Amt gehen, und nach Dokumenten verlangen. Diese Dokumente dürfte man dann, gegen einen geringen Kopier-Kosten-Betrag, kopieren und nach Hause mitnehmen. Z. B.: Jemand wollte sich den Bericht über die Schadstoff- und Qualitäts-Werte des Wassers in seiner Gemeinde erkundigen. Er/Sie ging zu dem Amt, bekam die Akten/Berichte, könnte sich diese durchlesen, kopieren und die Kopien mitnehmen … Es gibt nur mehr komplett geschwärzte Zeilen und Seiten. Nicht zu verwechseln mit DGSVO!
Das Recht auf Anwalt haben die US-Bürger nicht mehr (ganz)! Lavabit war ein US-Unternehmen, welches besonders sicherer (verschlüsselte) E-Mail-Dienst anbot. Eines Tages kam ein FBI Beamter, der sich auswies, mit ein paar „Man in Black“ Typen, die sich nicht auswiesen, und der FBI-Mann bestätigte, dass diese ebenfalls von Regierung seien und sich nicht-auszuweisen brauchen. Sie verlangten die Entschlüsselung des Systems und alle E-Mail-Konten, was der Betreiber technisch nicht imstande war. Außerdem bedeutete dies das Ende seiner Firma! Der Betreiber wurde belehrt, dass er gemäß Patriot Act und weitere neue Gesetze „Nichts unternehmen darf was dazu führen KÖNNTE, dass die Öffentlichkeit davon informiert wird.“ Damit KÖNNTE er von seinem Recht auf Anwalt nicht gebrauch machen, um gegen die Entschlüsselungen-Aufforderung vor Gericht zu ziehen (Anwalt, Richter, Staatsanwälte und Gerichtsmitarbeiter KÖNNTEN somit informiert werden).
Der Fall von Cisco Geräte mit NSA-Firmware-Versionen: Cisco Geräte (Router, Switches) die von große Konzerne oder staatliche Ämter/Organe in Ausland bestellt wurden, wurden von NSA abgefangen, Pakete geöffnet, die NSA Firmware-Version installiert, professionell wieder verpackt (sogar mit original Cisco 3D Laser-Holo-Labels) und dann verschickt. Bei einigen Geräten, nachdem man im Ausland die Firmware aktualisiert hatte, funktionierten die Geräte nicht mehr … Und so ist man denen auf die Schliche gekommen Es ist nun mal so, dass nicht jeder einfach für jedes Gerät einen Firmware schreiben kann. Man muss von dem Gerät sehr detailliertes Wissen haben, was nur die Cisco-Mitarbeiter in Entwicklungs-Teams haben können! Alles Klar was ich sagen möchte?
Die sicher geglaubte Kryptografie: Es war 2013 … Edward Snowden war überall zu sehen, hören und lesen. Einige Ereignisse danach wurden (leider) nicht oft bzw. lang genug in Medien thematisiert: Einschleusung von NSA-Mitarbeiter als Software-Entwickler in diverse Unternehmen. So wurden unter anderem Hintertüren (backdoor) in Systemen, und Trojaner auf Installations-Medien eingebaut … Und den Bereich für tatsächlich erzeugten privaten Schlüssel (Private Key, für asymmetrische Verschlüsselung alá RSA und PGP) erheblich beschränkt (statt gepriesene so-und-so-mega-peta-giga-trillionen-milliarden Möglichkeiten wurden nur ein paar tausend tatsächlich erzeugt, sodass die NSA & Co für die Brute-Force-Entschlüsselung weniger als zwei Stunden benötigten!).
Die Kaspersky-Antivirus-Software (mit künstlicher Intelligenz): Kaspersky kommt bekanntlich nicht aus USA, sondern aus Russland. Die fingen an (ich glaube 2012) mithilfe der KI die Dateien sowie Netzwerk-Verhalten von Systemen und Software zu analysieren … etwas das sich als erfolgreich erwiesen hat. Wurden ein paar wenige Systemen von Schadsoftware befallen, so wurde sofort die Signaturen (Fingerprints, Hash summen) von Dateien, neu installierte Software sowie das Netzwerk-Verhalten von denen, die zuvor in Kaspersky-Netz gespeichert wurden, als Wiedererkennungs-Signale an allen anderen Kaspersky-Antivirus-Clients weitergereicht. Für NSA & Co bedeutete dies: Die müssten für jeden PC ihre Schadsoftware ändern (damit neue unterschiedliche Signatur entstand) plus dessen Verhalten ändern (was viel schwieriger ist) … Was geschah? FBI-Männer in Begleitung von „Man in Black“ klopften an die Türen der Kaspersky-Büros in USA… Zusätzlich/Parallel startete man eine Schmutzkübel-Kampagne und warnte über US-Medien „man befürchte Sicherheitsrisiken durch Kaspersky-Antivirus“ … Es wäre ja auch schade um die Millionen US $ die NSA in Microsofts Defender investiert hatte …
Wenn man sich den Fall von Lavabit anschaut und Kaspersky sowie Krypto-Algorithmen-Sabotage dazu addiert … Dann … Ja dann könnte man auf komische Ideen kommen.
Daher erstaunt es mich immer wieder, wenn bei jedem Virus, Trojaner etc. immer wieder behauptet wird: Die Russen waren es! Wie kann es sein, dass „die Russen“ so „einfach“ in IT-Systemen eindringen können? Schauen wir uns doch das Ganze mal in Ruhe sachlich an:
Welche Betriebssysteme haben unsere Geräte?
Kommen die Microsoft Windows (3.11, 95, 98, 2000, NT4, XP, Vista, 7, 8, 10,…) aus Russland?
Kommen Apple OS X und iOS aus Russland?
Googles Android? Auch nicht aus Russland? Hmmm…. komisch!
Fast hätte ich es vergessen … Und Linux?
Welche Suchmaschinen verwenden wir?
Kommt Google Search aus Russland?
Kommt Microsoft Bing aus Russland?
Und Yahoo kommt auch nicht aus Russland? Wird immer komischer!
Ach ja! Wolfram Search?
Welche TOP 11 Profi-Netzwerk-Geräte (Router, Bridges und Switches) werden weltweit in Ämter, staatliche Organe, große Organisationen und Konzerne eingesetzt?
Nur fürs Protokoll: Alle von uns eingesetzten Betriebssystemen, Suchmaschinen und die wichtigsten Netzwerkgeräte (sowie alle Internet-Protokolle und Standards) kommen aus USA. Ein Schelm Putin-Versteher und „Anti-Amerikanist“ wer sich Böses Verschwörungstheorien denkt!
Wie schaut es bei uns in der EU aus? Wer in Österreich, Deutschland, Frankreich, Spanien, Italien, Schweden usw. baut Profi-Router/Switches? Und Patch-Kabel? Nicht einmal das Patch-Kabel! Wir müssen sogar ein lächerliches Patch-Kabel aus Asien (China & Tiger-Staaten) kaufen/importieren. So viel zu EU, Industrie 4.0 und Digitalisierung.
Wir sind zu 100 % von USA und China abhängig! Was wenn …?
Hier erkläre ich, anhand von praktischen Beispielen, worum es geht und wie das Spionieren durch Konzerne/Firmen über WWW (Webseiten, Handy-Apps, Bankomatkarte) funktioniert.
Eine Webseite (auch E-Mails die in „HTML“ Format empfangen werden) kann folgende Dinge enthalten:
Ausführbare Skripte (JavaScript)
Frameworks: Sammlung vorgefertigte „Koch-Rezepte“ (JavaScript), wie z. B. JQuery und JQuery UI
Elemente (Bilder, Schriftarten, Werbe-Banner oder komplette Webseite) von fremden (3rd Party) Webseiten (z. B. in sogenannte Rahmen „Frames“, oder transparente 1 × 1 Pixel „Bilder“)
CSS (Beschreibung-Skripte welche Dinge, wie dargestellt werden sollen, wie z. B.: Farben, Schriftart, Schriftgröße udg.)
„Cookies“: eine Datei das irgendwelche Name-Wert-Paare enthält wie z. B.: „IstAngemeldet=Ja“ oder „LetzteAktivitätZeitstempel=2021-12-31 23:59:59“ udg.
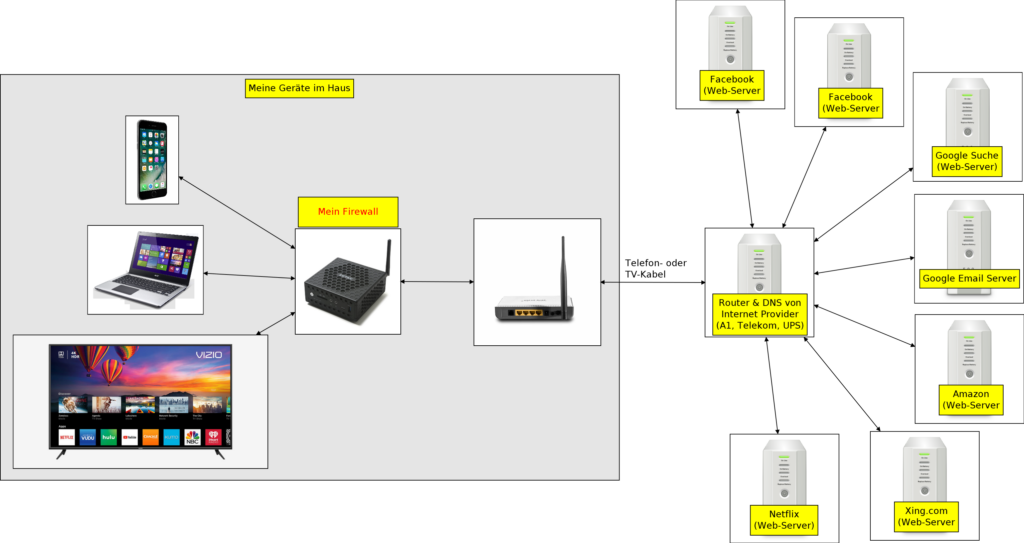
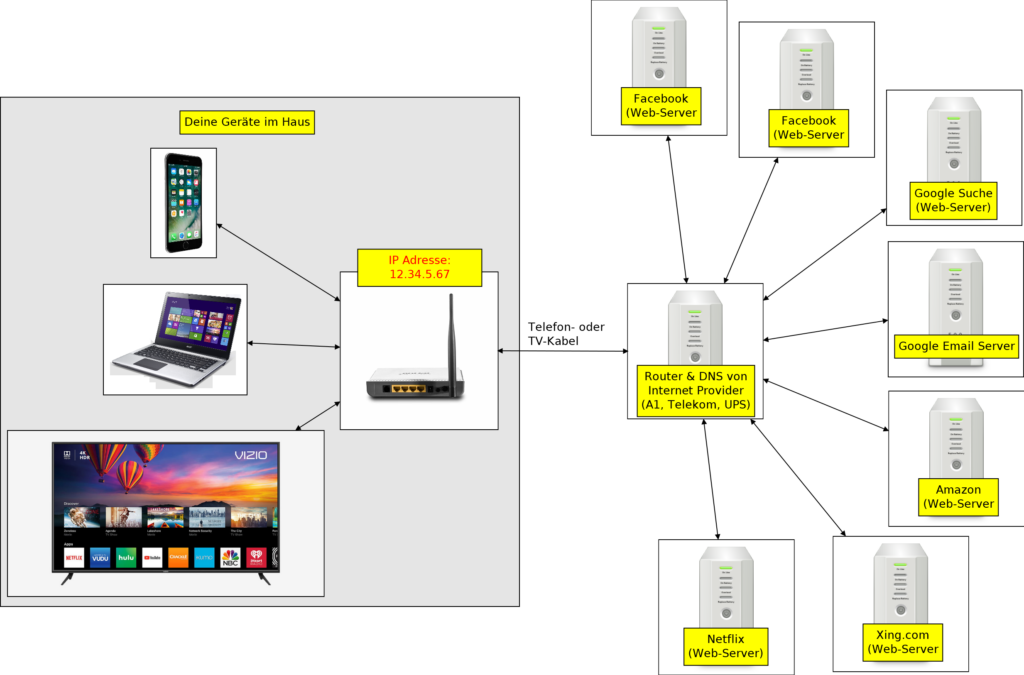
Dein Netzwerk bei dir Zuhause ist der Verräter!
Egal ob über das Telefon- oder TV-Kabel, du hast ein Modem von deinem Internet-Anbieter (A1, Telekom, UPS, …) bei dir Zuhause. Diese hat eine eindeutige IP-Adresse, sowie ein paar RJ-45 Büchsen und einen WLAN (damit du Zuhause mit dem Handy oder Notebook, ohne Kabel, statt 3G/4G/LTE/5G ins Internet kommst).
Es ist völlig egal, mit welchem Gerät im Haus, du ins Internet gehst (E-Mails von Google Mail „Gmail.com“ liest, in Amazon nach einem Produkt suchst und es online kaufst, Online-Banking machst, in Facebook ein Bild postest, mit TV Videos von YouTube oder Netflix anschaust usw.). Deine IP-Adresse (12.34.5.67), die von deinem Modem/Router, ist eindeutig, für jeden im Internet sichtbar (sonst wurde Internet nicht funktionieren), und damit kann man dich eindeutig identifizieren (die IP-Adresse ist wie ein Finger-Abdruck). Probiere den Link „Deine IP-Adresse“ mit verschiedene Geräte aus!
So! Und nun schauen wir mal was jeder einzelner Dienst-Anbieter (Google, YouTube, Facebook, Amazon, Xing.com, …) von dir weiß und (gegen Bezahlung oder Austausch-Vertrag) mit anderen austauschen kann.
Nehmen wir als Beispiel eine erdachte Person „Anton Berger“ der in Wien wohnt. Anton nimmt sein Notebook, öffnet den Internet Explorer, geht auf Google.com und sucht nach „sexy blondinen fotos“. Und klickt auf einem Link „Sex Magazin XYZ“.
Datenbank der Webseite von Google (Such-Maschine): Suchanfragen-Tabelle:
IP Adresse
Webbrowser ID
Was wurde gesucht?
12.34.5.67
Internet Explorer 0.8.15 (Windows 10 Pro, DE…)
sexy blondinen fotos
…
…
…
Jetzt nimmt er sein iPhone in die Hand, öffnet die Amazon-App. Nanu! In Amazon-App wird jede menge Werbung für Sex-Magazine, Sex-Kalender und Sex-Artikel gemacht! Der Anton bestellt sich den „Super Pervers Sex Magazin XXX“, und bezahlt es mit seiner Kreditkarte.
Datenbank von Amazon: Verkaufte Artikel:
Verkaufs ID
Konto ID
Artikel ID
Kreditkarten-Nr.
Betrag
…
…
1234
234
345
987654321000
100€
…
…
…
…
…
…
…
…
…
Amazon-Konten-Tabelle:
ID
Vorname
Nachname
Telefon
PLZ
Ort
Straße
…
234
Anton
Berger
012345678
1234
Wien
Berger Str. 1/2/3
…
…
…
…
…
…
…
…
…
Artikel-Tabelle:
ID
Name
…
345
Super Pervers Sex Magazin XXX
…
…
…
…
Datenbank deiner Bank („Banka Balkonia Finance Group“): Konten-Tabelle:
ID
Bankomat-Karten-Nr.
Kreditkarten-Nr.
Name
Adresse
777
1234567890
987654321000
Anton Berger
1234 Wien Berger Str. 1/2/3
…
…
…
…
Letzte-Transaktionen:
Konto-ID
Wann
IP Adresse
Client
Client-/Web-Broser-ID
777
01.02.2019 12:30:00
12.34.5.67
Handy App
…
777
28.02.2020 01:59:59
12.34.5.67
Web Browser
Internet Explorer 0.8.15 (Windows 10 Pro, DE…)
Nun schaltet der Anton seinen TV ein und öffnet den Netflix oder YouTube TV-App. Nanu! Es werden jede menge Werbung für Erotik-Filmen gezeigt.
Am nächsten Tag schaut sich Anton seine E-Mails auf seinem PC an. Dazu öffnet der seinen Firefox Webbrowser. Er hat eine neue E-Mail von Xing (oder Facebook, Twitter, LinkedIn, WerAuchImmer…). Er war so klug und hat Gmail so eingestellt, dass die Bilder in E-Mails nicht automatisch geladen und gezeigt werden (eigentlich reicht es, wenn die Bilder geladen werden, diese müssen jedoch nicht gezeigt werden! So macht das z.B. GMail-App von Google! Warum das von Interesse ist, kommt später).
Der Anton klickt auf „Bilder unten anzeigen“. Was passiert da? Es wird in Wahrheit kein Bild von Web-Server geholt, sondern ein einzigartiger Link, welcher eine Signatur nur für Anton enthält aufgerufen. Dahinter versteckt sich ein Programm, welches auf dem Web-Server gestartet wird. Dieser sucht in der Datenbank nach die eindeutige Signatur und vervollständigt (zum Beispiel) folgende Einträge: Wer hat wann mit welche IP-Adresse mithilfe welchem Client diesen Link aufgerufen, und was soll nun gesendet werden. Erst danach wird das Logo/Bild gesendet! Wenn man z. B. in einem Webbrowser wie Firefox, Rechts-Klick auf dem „Xing Logo“ macht und in Kontextmenü auf „Link-Adresse kopieren“ wählt … (siehe Bild unten!) …
Dann kann man sich den Link irgendwo anders (z. B. in einem Text-Editor oder Adresszeile des Browsers) genauer anschauen, wie hier im Bild unten:
Anhand der IP-Adressen + „User Agent“ Eigenschaften kann man eine Tabelle anlegen, und sämtliche Aktivitäten verfolgen. Der Internet-Provider (z. B. A1, Telekom, UPS, …) können dies jederzeit tun. Die DNS (Domain Name Server) liefern die IP-Adressen für Links/URLs, die für Menschen leichter verständlich sind. Zum Beispiel: für „www.amazon.de“ wird „99.88.123.250″ zurückgeliefert. Somit kann jeder DNS Betreiber (auch A1, Telekom, UPS, …) wissen, wann man aufwacht, wann man seine E-Mails von welchem E-Mail-Anbieter liest, … und so weiter bis zum, wann man wieder Zuhause ist und schläft. Die IP-Adressen von Modem/Router werden zwar von Zeit zu Zeit geändert … aber es gibt jede menge andere Meta-Daten, die man ebenfalls zur Verfügung hat, und aus einer Submenge von ihnen, ist es möglich immer genau zu sagen, wer schon wieder (und wie oft) auf www.playboy.com herum-surft usw.
Ein „User Agent“ ist in der Web-Sprache, eine lange Text-Zeile, die einiges über das verwendete Client (Amazon-App, Banken-App, Internet Explorer, Chrome, Firefox, Samsung-Smart-TV-YouTube-App etc.) aussagt, wie z. B.:
Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0
Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/51.0.2704.106 Safari/537.36 OPR/38.0.2220.41
Opera/9.80 (Macintosh; Intel Mac OS X; U; en) Presto/2.2.15 Version/10.00 Opera/9.60 (Windows NT 6.0; U; en) Presto/2.1.1
Und wie man sieht, steht in „User Agent“ viel mehr als einem lieb ist: Name und Version von Client, Betriebssystem-Name und -Version, 32 oder 64 Bit. Dieser Text wird immer an dem Webserver gesendet!
Dann kommen noch die Skripte (JavaScript) die in Webseiten, auf deinem Handy/Notebook/TV, ausgeführt werden. Diese können dann unter anderem folgende Dinge über dich verraten: Wie groß ist dein Bildschirm (1920 × 1080 Pixel), welche Farbtiefe ist eingestellt, und welche „Plug-ins“ bzw. „Add-ons“ du installiert hast, welche Sprache du auf dein System verwendest („de“, „en“, „us“,…) … und einiges mehr.
Dann gibt es die Cookies auch noch 🙂 Diese speichern Informationen in einem Cache Verzeichnis auf dein Gerät. In denen stehen Dinge wie: Wann hast du dich angemeldet, bist du überhaupt angemeldet, was hast du gewählt, gesucht, geklickt usw. Manche diese Cookies sind sogenannte 3rd-Party-Cookies. Diese speichern Daten über dich, um dich für andere Webseiten eindeutig und leichter zu identifizieren. Bei mir werden diese immer deaktiviert (Firefox). Sobald du eine andere Webseite besuchst, kann er auf diese 3rd-Pary-Cookies zugreifen und sich anschauen, wofür dich interessierst oder bisher so gemacht hast.
Dann gibt es noch 3rd-Party-Dinge wie z. B. Video- oder Musik-Player. Du gehst auf die Webseite „www.illegal-kinofilme-gratis-anschauen.com“ und schaust dir den neuen Schinken aus Hollywood (eine Sony-Produktion) an. Irgendwann gehst du auf eine andere Seite und schaust dir z. B. ein Werbe-Video an … Was glaubst du, was dieser Video-Player alles über dein Gerät und somit dich speichert und weitergibt? Was mach der Verein Anti Piraterie (VAP) mit deiner IP-Adresse und Zeitstempel, wenn sie an die Daten von beschlagnahmten Server kommen (von wo du die illegal MP3 oder Videos heruntergeladen/angehört/angesehen hast)?
Die meisten Webseiten im Internet benutzen sogenannte Frameworks: JQuery, JQuery UI, WordPress,… Was glaubst du was diese an Daten abfragen und weiterleiten/austauschen/verkaufen?
Sprichst du gerne mit Alexa, Siri, Cortana & Co? Sind diese immer eingeschaltet (= horchen immer zu)? Hast du gewusst, dass das was du denen sagst zuerst zum Amazon, Apple, Microsoft etc. gesendet wird, damit deren Künstliche Intelligenz dein Gesprochenes zu Text umwandelt?
Trägst du eine moderne Armband-Uhr, welche mit deinem Handy verbunden ist oder direkten Zugang zum Internet hat? Könnte es sein, dass die Versicherung wo du deine private Kranken-Versicherung abgeschlossen hast, an diese Daten Interesse hat?
Gehst du gerne Laufen? Werden deine Lauf-/Sport-Aktivitäten sofort, Live, ins Facebook oder sonst wo angezeigt und aktualisiert? Hast du Unbekannten als deine „Freunde“ in Facebook? Könnte es sein, dass einer von ihnen (dank deiner Bilder) weiß, dass du teures Zeug zu Hause hast? Könnte er auch nun wissen, wo du gerade bist, und wie lange brauchst bis du wieder zu Hause bist?
Tust du dein Haus oder Wohnung mit Kameras rund um die Uhr überwachen? Fühlst du dich nun sicher? Na dann schau mal hier, ob du aufgelistet bist 😉 Die Profi-Diebe freuen sich auch!
Hast du dir ein USB-Ladegerät gekauft, um deine Akkus über USB zu laden?
Eine wahre Geschichte zum Aufwärmen: In der Weimarer Republik (Deutschland), hatte jemand die Idee, unterschiedlichste Listen von Beamten, Politiker, Offiziere udg. zu erstellen. In eine Liste wurden Namen von Personen (hohe Beamten, Politiker, Offiziere etc.) gesammelt, welche „mädchenhaft“ waren, oder sich für gleichgeschlechtliche Liebe oder gar „Knabenliebe“ interessierten. Diese Liste wurde als die „rosa rote Liste“ genannt. Niemand weiß bis heute, wer der Initiator war, und niemand weiß, warum bzw. wozu? Die gelistete Personen wurden weder verhaftet, noch entlassen, noch kontaktiert. Einige Zeit später gab es die „Weimarer Republik“ nicht mehr. Stattdessen, war der „dritte Reich“ da, mit NSDAP und ein gewisser Adolf an deren Spitze … Die rosa rote Liste (neben andere Listen) war noch da. Und diese wurde von Gestapo und SS „abgearbeitet“. In einer Demokratie, MÜSSEN die Regierungen, Ämter und Organe, sehr präzise und ausführlich begründen 1. Welche Daten, 2. von Wem, und 3. Wozu gesammelt werden? 4. Wann diese Daten unter 5. Welche Voraussetzungen gelöscht werden? Das Ganze sollte natürlich transparent gehalten werden (ausgenommen, wenn es um Schutz der Bevölkerung oder tatsächliche Gefahrenbekämpfung geht, wie z. B. Terror, Kriminalität udg., oder tatsächliche „nationale Interessen“ wie z. B. Kauf von Funkgeräte fürs Militär usw.). Zu diesem Thema empfehle ich den Roman „NSA – Nationales Sicherheits-Amt“ von Andreas ESCHBACH, ISBN 978-3-7857-2625-9
Wie man gesehen hat, siehe BVT, Ibiza, Wirecard, Spionage von NEOS Abgeordnete & Co, heißt eine Demokratie NICHT, dass ALLES so bleibt wie es ist. Regierungen kommen und gehen, die Parteien wechseln Farbe (z. B. Schwarz zum Türkis) und Personal… Wir wissen NIE wer als Nächstes kommt, was er/sie vorhat, und wozu diese(r) fähig ist… „Sie werden sich noch wundern, was alles möglich ist.“ (Norbert Hofer, FPÖ)
Gegenstandsbereich der Software-Ergonomie im eigentlichen Sinne ist der arbeitende Mensch im Kontext (Softwarenutzung an Arbeitsplätzen). Allgemein wird heute die Benutzung von bzw. die Interaktion mit Computern betrachtet. Dies bedeutet die Berücksichtigung (neuro)psychologischer Aspekte beim Entwerfen der Software – wie dies methodisch auch die Ingenieurpsychologie anstrebt –, um eine optimale Mensch-Maschine-Schnittstelle zur Verfügung zu stellen. Dies soll sich in besonders leicht verständlichen funktionalen Einheiten ausdrücken (Bsp. einfache Dialoge bei Systemen mit GUI). Die Entwicklung gebrauchstauglicher Software wird im Rahmen des Usability-Engineering geleistet.
Wer ist der User?
Zu einem System gehören nicht nur Hardware u. Software, sondern auch Anwender (User). Der User unterscheidet sich durch:
Kultur (Sprache, Symbole, Farben),
Bildungs-Niveau,
domänenspezifisches Wissen,
Kontaktfreudigkeit,
Gemütszustand (schlechter Tag, private Probleme, Eile, Stress, Müdigkeit,…)
…
Und einiges mehr.
Es ist wichtig sich bewusst zu sein, dass viele Anwendungs-User in sogenannte Dritte-Welt-Länder, noch nie einen PC mit Maus und Tastatur gehabt, oder damit gearbeitet haben.
Diese besitzen jedoch meist ein Smartphone. Genauso wie das Festnetz-Telefon durch den Einsatz und schnelle Verbreitung von Handys und Handy-Masten übersprungen wurde, wurden in viele Länder die PCs durch Smartphones (und teilweise Tablets) übersprungen.
Somit ist es verständlich das Einigen die Verwendung von Tasten-Kombinationen („Tastatur-Kung-Fu“), Kontext-Menüs, F1 – F12 und Escape-Tasten, sowie Tool-Tipps teilweise oder gar völlig unbekannt sind.
Das sollte auch bei der Einschulung der User sowie schreiben der Manuals berücksichtigt werden.
UX Eigenschaften
Allgemein gebräuchliche Eigenschaften von Usability:
Nützlich: Kann es etwas, das die Leute brauchen?
Erlernbar: Können Leute herausfinden wie es funktioniert?
Einprägsam: Müssen die User es für jeden Gebrauch erneut lernen?
Effektiv: Erledigt es seinen Job?
Effizienz: Tut es das in einem angemessenen Zeitraum und mit zumutbarem Aufwand?
Begehrenswert: Werden die User es mögen?
Reizvoll: Ist der Gebrauch erfreulich oder macht er sogar Spaß?
UX Definition von Steve KRUG:
„Eine Person mit durchschnittlicher (oder sogar unterdurchschnittlicher) Fähigkeit und Erfahrungversteht, wie man das Ding benutzt, um etwas zu erreichen, ohne dass dabei der Aufwand größer als der Nutzen ist.“
KRUGs erstes Gesetz der Usability
Was ist Usability?
Eine Anwendung sollte – so weit, wie es nach menschlichem Ermessen möglich ist – klar sein.
Der User sollte in der Lage sein „es zu kapieren“ – was die Ansichtdarstellt und was man mit ihr machen kann –, ohne lange überlegen zu müssen.
Wie viel Klarheit?
Wenn der User sich denkt: „Oh, das ist ja einMenü → ich kann es anklicken.“ „Ah ja, da istder Button zum Speichern.“ „Da ist jadas Bestellformular →was ich wollte.“
Was ist Unklarheit?
Wenn der User eine Ansicht (gilt auch für Sektionen und Steuer-Elemente) ansieht, die ihn zum Überlegen zwingt, sind alle Gedankenblasen über seinem Kopf voller Fragezeichen.
Grundprinzip von UX: Eliminierung der Fragezeichen.
Mann kann nicht alles offensichtlich machen! Aber das Ziel sollte sein, dass jede Ansicht (gilt auch für Sektionen und Steuer-Elemente) offensichtlich ist, damit der Durchschnittsanwender beim Ansehen weiß, worum es geht und wie man sie nutzt. Er kapiert es, ohne darüber nachzudenken.
Warum müssen die Fragezeichen eliminiert werden?
Wenn wir (User) die Anwendung benutzen, trägt jedes Fragezeichen zu unserer kognitiven Belastung bei und lenkt unsere Aufmerksamkeit von der momentanen Aufgabe ab. Die Ablenkungen mögen nur gering sein, aber sie addieren sich, und ein Tropfen bringt das Fass zum Überlaufen.
Grundregel:
Die Leute mögen es nicht, darüber nachzugrübeln, wie man etwas macht (Wer liest gerne die Manuals zuerst durch? „TL;DR“* in Kommentaren, Chats und Blogs,… Anm. d. A.). Die Tatsache, dass die Ersteller der Anwendung sich keine große Mühe gaben, die Dinge offensichtlich – und einfach – zu gestalten, kann unser Vertrauen in die Anwendung und ihre Herausgeberuntergraben.
*) Abkürzung des Internet-Kunstbegriffs „Too Long; Didn’t Read!“
Beispiel für Dinge die den User zum Nachdenken zwingen:
Niedliche oder clevere Namen, falsche oder nicht gebräuchliche Begriffe
firmenspezifische oder fremdartige technische Bezeichnungen
nicht offensichtlich anklickbare Buttons, Drop-Down-Listen, Listen-Elemente, Links,…
„Datum von“, „Datum bis“: ist das inklusive oder exklusive heute/gestern/…?
Ich habe die Uhrzeit in Datum-UI eingegeben, aber die Uhrzeit-UI zeigt immer noch XYZ an. Was habe ich falsch gemacht?
Muss ich jetzt die Anwendung Neustarten (um die Einstellungen anzuwenden) oder nicht?
Wurde die Aktion XYZ durchgeführt oder nicht?
Muss ich auf „Speichern“ oder „Übernehmen“ klicken?
Muss ich auf „Cancel“ oder „Close“ klicken? Was ist der Unterschied?
Ich klicke auf dem Button „Kopieren“ aber es tut Nichts! Warum? Habe ich was falsch gemacht?
Was ist „Initialisieren“?
Uuups! Fehlermeldung „Object XYZ throw NullReferenceException….“. Was heißt das? Hab ich was falsch gemacht? Kann ich es nochmal probieren? Muss ich jemandem davon benachrichtigen? Kann ich weiter damit arbeiten oder muss ich die Anwendung Neustarten? An welche Support-E-Mail-Adresse muss ich schreiben? Welche Hotline-Nummer muss ich wählen? Was soll ich dem Support-/Hotline-/Techniker sagen?
…
Also warum UX?
Die Ansichten offensichtlich zu gestalten, ist wie die gute Beleuchtung in einem Geschäft: Alles erscheint einfach besser. Die Nutzung einer Anwendung, die uns nicht zum Nachdenken über Unwichtiges zwingt, fühlt sich mühelos an, wogegen das Kopfzerbrechen über Dinge, die uns nichts bedeuten, Energie, Nerven, Enthusiasmus und Zeit raubt.
Die meisten User haben weit weniger Zeit mit dem Betrachten der von uns designten Ansichten/Fenster/Manuals, als uns lieb ist.
Ergebnis: Klarheit oder zumindest selbsterklärend.
Die User haben ein Ziel. Sie wissen, dass sie nicht alles lesen müssen. Sie sind gut darin Dinge zu überfliegen. Darin sind sie geübt (in der Sprache der Neurologen: konditioniert).
Deswegen: die User wählen in der Realität die erste annehmbare Option (Satisficing1), also ausreichend befriedigend. Zur Erinnerung: Gemütszustand der User!
Die User befassen sich nicht damit, wie etwas funktioniert, sondern wursteln sich durch (Beispiel: Manuals/Bedienungs-Anleitungen).
Woher kommt das?
Den meisten von uns ist es egal, ob wir die Funktionsweise verstehen, solange wir etwas benutzen können
Wenn wir etwas finden, das funktioniert, bleiben wir dabei. Wir neigen dazu keinen besseren Weg zu suchen.
Wenn die User eine Ansicht kapieren ist die Wahrscheinlichkeit viel größer, dass:
sie das Gesuchte finden (was gut für User und Hersteller ist)
sie die gesamte Anwendung verstehen
sie sich schlauer fühlen und haben mehr das Gefühl der Kontrolle
Ein paar Punkte zum Überfliegen von Design und Layout:
Vorteile von Konventionen nutzen
Effektive visuelle Hierarchien erzeugen
Einteilung der Ansichten in klar definierte Bereiche
Keine Zweifel darüber lassen, was anklickbar ist
Minimierung des „Rauschens“
Formatierung der Inhalt, damit er sich leichter überfliegen lässt
Wichtigste über Navigation:
Wo bin ich (da)? und
Wo möchte ich hin (dort)? Daraus resultiert
Wie komme ich dorthin (Strecke/Weg, Route)?
1 Satisficing ist ein Kunstbegriff bestehend aus: Satisfaction + Sufficient
Vorgehensweise bei Projekt-Beginn
UML Use Case Diagramm:
welche Akteure (User) werden
welche Funktionen (Was)
wann und
wo aufrufen/anwenden
UML Zustands Diagramm:
In welcher/welches Ansicht/Fenster/Menüpunkt beginnt das Ganze?
Was sind die nächsten Schritte?
Durch welche Daten/Zustände werden welche UI-Elemente aktiviert/deaktiviert?
Was sind illegale Eingaben/Aktionen? Wie soll darauf reagiert werden?
Was wenn bei der Aktion XYZ (Laden, Speichern,…) ein Fehler auftritt?
Muss der User alle bisherige Angaben (z. B. in Formular) nochmal eingeben? Zumutbar?
Muss der User die Anwendung Neustarten? Oder Admin benachrichtigen bzw. Hotline anrufen?
…
Wie kann dem User am Ende der Aktions-Kette signalisiert werden, dass alles gut gegangen oder etwas Fehlgeschlagen ist?
Sind Zusatz-Informationen notwendig?
Kann dem User Vorschläge unterbreitet werden, was er/sie tun kann damit es funktioniert?
Wo bzw. in welche Dokumentation oder Manual kann der User mehr darüber lesen?
…
Wireframes / Mockups erstellen!
Reviews!
Test von Wireframes / Mockups auf dem Papier…
Verbessern und nochmal Testen!
Erst, wenn Tests erfolgreich sind, wird mit der GUI-Entwicklung begonnen
Jetzt kann die GUI qualitativ auf UX getestet werden (periodisch/zyklisch!)
Falls in neue Anwendungs-Version neue Funktionen hinzugekommen sind (Menüs, Menü-Punkte, Buttons, Listen udg.) → auf UX nochmal Testen!
Standards & Konventionen
Die Standards und Konventionen sind nicht aus Langweile oder einfach aus der Luft gegriffen.
Irgendjemand hatte die Idee zuerst. Wenn die Idee gut war und sich als nützlich erwies, wurde es mehr und mehr kopiert und verbessert. Irgendwann haben die Leute das Ding öftersüberallgesehen und wissen worum es sich handelt und wie es funktioniert. Sie müssen nicht nachdenken (in der Sprache der Neurologen und Pädagogen: Model-Lernen, oder einfach Kopieren).
Die Aufgabe von Layout und Design ist nicht, das Rad neu zu erfinden!
Selten führt das Neuerfinden des Rades zu einem revolutionärem, neuen Fahrgerät. Aber oft geht dabei einfach nur Zeit drauf.
Wenn man, eine existierende Konvention nicht nutzen kann/will, muss man sicher sein, dass der Ersatzvorschlag:
Offensichtlich und
selbsterklärend ist und
kein Anlernen benötigt oder
es einen so extrem großen Wertzuwachs bedeutet, dass etwas Anlernzeit gerechtfertigt ist.
Klarheit übertrumpft Konsistenz!
Was bringt es, wenn etwas konsistentunverständlich ist?
Beispiele für Konventionen:
Form und Farben:
Egal wo Sie mit dem Auto fahren, ob in: Iran, Chile, Mongolei, Mexiko, Marokko, Québec, Thailand oder China,… die wichtigsten und notwendigsten Verkehrszeichen sehen alle gleich aus (bis auf die Schrift).
Positionierung der Funktionen:
Egal wer das Auto gebaut hat, egal ob manuelle oder automatische Schaltung, und egal welches Model das Auto ist: Die Positionen und Funktionen der Pedalen sind eindeutig. Man muss nicht nachdenken.
Abgerundete Ecken bei Schalter und Tastatur:
Beim Überfliegen einer Ansicht suchen wir nach Hinweisen, die Dinge als anklickbar kennzeichnen.
Entstandene (Ideen) Standards:
Signal-Stärke und Rauschen (= Lärm)
Beispiel fürs Rauschen/Lärm:
Zu viele/lange Texte (Absätze kurz halten)
viele Ausrufezeichen
verschiedene Schriften und bunte Farben
automatische Animationen (hineinfahren/hinausfahren von mehreren Steuer-Elementen, wenn mit der Maus über die Ansicht gefahren wird)
Keine oder wenige Listen mit Gliederungspunkten (Manuals, Fehler-Behebungs-Vorschläge,…)
Nicht hervorgehobene Schlüsselbegriffe (= Signal)
Unordnung:
Jede Ansicht ist anders aufgeteilt
Durch zu große Dimensionierung verliert ein Steuer-Element seine Wieder-Erkennbarkeit
Dinge mit gleicher Funktion (Status-Texte, Labels, Buttons,…) haben unterschiedliche Größe, Position, Form, Schriftart oder Farbe (bei mindestens einer Ansicht)
Neue Schriften oder Farben auf mindestens einer Ansicht
Nicht genug Abstand
Nicht eindeutig Zuordenbar
Nicht betitelt oder beschriftet (Was kann ich in dieser Drop-Down-Liste auswählen?)
Unnötige Umrandung(en) oder Rahmen suggerieren das Element (z. B. Button oder Combo-Box) ist etwas Eigenes und hat nichts mit den UI Elementen darunter/darüber zu tun
Erstes Beispiel für UX-Test: Wo bin ich?
Schichtwechsel! User Anton geht. User Bernd kommt.
Was sieht er?
Muss Bernd nachdenken/grübeln welche Ansicht er sieht?
Vor den UX Verbesserungen
Nach den UX Verbesserungen
Zweites Beispiel für UX-Test: Wo finde ich XYZ?
Die Produktion steht! Der für die Produktion verantwortlicher User (Maschinen-/Hallen-Chef oder Produktions-Leiter) eilt gestresst und genervt zum Bildschirm. Er hat die Fehler-Meldung „Unbekannte Produkt-Nummer!“ bekommen und nun sucht er (ungeduldig) nach Anweisungen für die Konfiguration.
Er versucht möglichst schnell (durch Überfliegen) die interessanteSektion zu finden.
Muss er alles durchlesen?
Muss er viel nachdenke/grübeln?
Warum?
Was ist hier das Rauschen/Lärm?
Wo sind die Signale?
Vor den UX Verbesserungen
Nach den UX Verbesserungen
Maximale Anzahl der Klicks für die Navigation oder Erledigung einer Aufgabe:
Die Anzahl ist relativ egal, solange diese Klicks unüberlegt getätigt werden können.
Als Richtlinie: ca. max. 3 Klicks. Warum sollte der User N Mal klicken um zu XYZ zu kommen? Warum sollte der User N Ansichten/Views oder gar andere Stellen/Fenster/Dokumente (User Manual, PDF) suchen um alle benötigte Informationen zusammenzubekommen? Kann man den XYZ klickbar machen, damit der User mit nur einem Klick darauf, sofort das Dokument öffnen/speichern/sehen kann?
Einige Wahrheiten über UX-Tests
Wenn man eine großartige Anwendung haben will, muss man es testen.
Einen einzigen User testen ist auf jeden Fall besser als gar keine Tests.
Einen User zu Beginn des Projekts testen zu lassen, ist besser als 50 gegen Ende.
Was wird getestet?
Qualitative UX-Eigenschaften:
Klarheit
Offensichtlichkeit
Wiedererkennbarkeit
Einhaltung von Konventionen/Standards
Navigation
Wie lange der User, für die Erledigung bestimmter Aufgaben benötigt hatte
Woran der User, während der Erledigung der Aufgaben gegrübelt/gedacht, bzw. welche Fragen er sich gestellt hat
Welche Outputs nach dem UX-Test gibt es?
Video
Analyse-Bericht mit:
Liste von erledigte oder nicht-erledigte Aufgaben (wenn nicht erledigt: der Grund)
Liste der gröbsten Mängel (max. 10)
Verbesserungsvorschläge
Wie wird entschieden welche der Mängel sofort zu beheben sind?
Nach Return-on-Investment (RoI):
Es wird eine engere Auswahl-Liste erstellt. Der Zweck der Auswertung ist, die schwerwiegendsten Probleme zu identifizieren, damit diese zuerst behoben werden.
Vorgehensweise:
Verbesserungen die leicht und schnell umgesetzt werden können zuerst.
Verbesserungen die etwas mehr Zeit benötigen fürs Später einplanen.
Falls die Anwendung (das Projekt) kurz vor dem Liefer-Termin steht und die Behebung eines der Mängel inklusive dessen UX-Test nicht zu schaffen ist, dann für nächste Roll-Out planen.
Re-Design ausschließlich, wenn das Projekt noch in Anfangs-/Entwicklungs-Phase befindet, sonst nie (diese müssen leider dann akzeptiert/hingenommen werden!).
Vorschläge für mehr Effizienz, Zeit- und Kosten-Ersparnis bei den GUI-/Anwendungs-Projekten:
Fürs Layout (Ausrichtung, Positionierung/Platzierung, Abstände, Dimensionen) ein möglichst einfaches Konzept/Model ausarbeiten (Wireframes) und das Layout minimal halten. Später können diese leicht und schnell hinzugefügt, präzisiert, angepasst und detaillierter gestalten werden, und zwar einmalig.
Design (Schrift-Arten, Farben, Symbole udg.) weglassen, oder sehr einfach und „global“ änderbar halten. Global bedeutet wie z. B. die einmalige Definition von Hintergrund-Farbe oder Schrift-Größe für Buttons (Schaltflächen) unter einzigartigen Namen in einer globalen Stil-Datei („styles.xaml“) wie z. B.:
Button-Background-Color = Light-Gray
Button-Font-Size = 14 pixels
Alle Buttons nutzen dann die in Stil-Datei definierte und benannte Werte.
Dadurch kann man durch das Anpassen/Ändern des Wertes (z. B. für die Schrift-Größe) an einer einzigen Stelle (in „styles.xaml“), alle Buttons einheitlich anpassen. Funktioniert extrem leicht und schnell. RETURN ON INVESTMENT!
Kurzes Beispiel für einen UX-Test-Bericht mit Liste der Mängel sowie deren Verbesserungsvorschläge:
Angemeldet als Admin, gezeigt wird die Ansicht Produktion
Weiß der User welche Ansicht er vor sich hat?
Nein! Weil…
2.
Wie 1.
Der User soll neue Produktion mit dem Namen „P123“ anlegen.
Ja
3.
Gezeigt wird die Ansicht Produktions-Klassen
Umbenennen der „P123“ in „Q456“
Nein! Weil…
4.
Wie 2.
Der Wert von System-Einstellung XYZ soll auf 1,23 geändert u. gespeichert werden
Ja
…
…
…
…
Worüber der User gegrübelt hat:
Bei Aufgabe 1 hat er die Drop-Down-Liste XYZ nicht als solches erkannt und hat danach gesucht.
Bei Aufgabe 3 könnte der User nicht herausfinden wie der Name der P-Klasse geändert werden kann.
Während der Aufgabe N wurde eine Fehler-Meldung Error-0815 ausgelöst. Der User war sich nicht sicher, ob er weiterarbeiten kann oder die Anwendung neu-starten muss.
…
Verbesserungsvorschläge:
Die Drop-Down-Liste XYZ beschriften (mit einem Label über oder Links davon) und ein Tooltip (Balloon-Text) hinzufügen mit dem Text „Hier können Sie XYZ auswählen“.
Der Text für die Fehler-Meldung Error-0815 ändern, damit der User weiß, dass er die Anwendung neu-starten muss.
Bei Pareto-Prinzip geht es vereinfacht formuliert darum: das Verhältnis der Dinge, mit 20 % und 80 %, möglichst einfach zu beschreiben. Dabei gibt es nur die zwei Prozentzahlen: 20 und 80 (sonst nichts). Z. B.: 20 % Code von einer Software enthält die 80 % der Hauptfunktionen (SW Core), oder 20 % der Funktionen werden 80 % der Zeit aufgerufen, die Benutzer sehen in 80 % der Fälle 20 % der Fehler-Dialoge/-Meldungen etc. etc. usw. usf.
Bei Job-Interviews, stelle ich immer die Frage nach dem Prozentsatz meiner Tätigkeit in der Firma (welche einen Software-Entwickler für .NET/C# sucht).
Was ich erwarte: 20 % der Zeit … oder 80 % der Zeit. Ich glaube ja auch daran, dass ein Bäcker 80 % der Zeit Brot bäckt, ein Metzger 80 % der Zeit Fleisch schneidet, ein Automechaniker 80 % der Zeit Autos repariert…
In altes Griechenland, zwei angesehene alte Fischer die auch Philosophen waren, da sie ja auf dem Meer genug Zeit zum Nachdenken hatten, führten am Land eine lebhafte Diskussion.
Der erste behauptete die kleinsten Fische seien 3 Finger hoch/dick. Der zweite behauptete das sei falsch, weil die kleinsten Fische 2 Finger hoch/dick seien.
Der Erste meinte zum Zweiten: Deine Fische können gar nicht aus dem gleichen Meer sein. Der Zweite erwiderte zum Ersten: Du stichst nicht weit genug ins Meer. Wurdest du so weit wie ich ins Meer stechen hättest du auch kleinere Fische in deinem Netz.
Nach einige Zeit versammelte sich das ganze Dorf am Hafen. Die einen verteidigten den Ersten, die Anderen den Zweiten, ein paar andere meinten lautstark beide hätten recht. Es wurden zig Fische herangezogen und verglichen. Mal nahm man die Finger der Kinder als Vergleich, Mal von alte Frauen… Alles wurde nur verworrener.
Da kam ein Fremder mit dem Boot ans Land, und wollte aus reiner Neugierde wissen was all die Menschen am Hafen, Wichtiges zu diskutieren hätten. Jemand schilderte ihm die Situation…
Da ging der Fremde auf die Fischer zu, und fragte, ob sie ihre Netze ihm zeigen können. Gesagt, getan. Er nahm das Netz vom zweiten Fischer und versuchte 3 Finger in einem Loch zu stecken. Ging nicht. 2 Finger gingen schon. Nun nahm er beide Netze suchte sich bei beiden die Mitte, und legte sie übereinander. Heureka! Die Netze hatten unterschiedlich große Löcher.
Drei Philosophen hatten eine sehr lebhaft geführte Diskussion. Alle drei waren sich einig, dass: 1 + 0 = 1 sei. Alle drei waren sich auch einig, dass: 0 + 1 = 1 sei.
Jedoch bei 1 + 1 hatten sie unterschiedliche Meinungen. Zwei meinten 1 + 1 = 2, und der dritte beharrte darauf, dass 1 + 1 = 10 sei. Darauf meinte einer von ersten zwei, dass 1 + 1 nicht = 10 sein kann, da 7 + 1 = 10 sei…
So sagte nun der andere von ersten zwei, dass der andere sich auch irrt, da 10 + 10 = 100 sei. Jetzt behauptete der dritte das diese zwei sich komplett auf dem Irrweg befanden, da jeder wusste, das 70 + 10 = 100 sei…
Nun war die Verwirrung perfekt. Also kurz zusammengefasst: Alle drei Philosophen hatte gleichzeitig recht! Wie kann das nur sein?
1 + 0 = 1 (Alle drei einig) 0 + 1 = 1 (Alle drei einig) 1 + 1 = 2 (nur der 1. und 3.) 1 + 1 = 10 (nur der 2.) 7 + 1 = 10 (nur der 3.) 10 + 10 = 20 (nur der 1.) 10 + 10 = 100 (nur der 2.) 70 + 10 = 100 (nur der 3.)
Der erste Philosoph hat alles aus seiner Sicht, die dezimale Sicht, betrachtet. Der zweite Philosoph hat ebenfalls aus seiner Sicht, die binäre Sicht, betrachtet. Der dritte… nun auch er hatte seine Sicht: die oktale Sichtweise.
Somit hatten alle drei Philosophen, jeder in seinem System, recht.
Bei der Kommunikation geht es viel öfter darum richtig zuzuhören, ehrlich zu versuchen den Gesprächs-Partner zu verstehen, und nicht lautstark seine Meinung zu verteidigen.
Eine kurze Geschichte übers Kommentieren und Kommentare
Ich wünsche die Kollegen beim Neuschreiben des Codes in C, C++, C#, Java,… oder WasAuchImmer++ viel Geduld, Kraft und Nervenstärke.
Wenn Kommentare genauso kryptisch sind, wie der Code
Was machen diese 15 Zeilen?
Man kann die Kommentare übersetzen und erahnen was diese Zeilen tun
Back to the Future… Kommentare sind wichtige Informationen für die Zukunft. Kommentare sind wichtige Informationen aus der Vergangenheit. Kommentare sind Notizen/Erklärungs-Ergänzungen für sich selbst, Kolleginnen und die Nachwelt (neue Kolleginnen, wenn man nicht mehr in der Firma (oder am Leben) ist).
Ich lese immer wieder Sätze mit Rufzeichen am Ende, wie „Jede Code-Zeile muss kommentiert werden!“, oder „Pro Methode, mindestens drei Zeilen Kommentare!“ usw.
An der Uni hieß es „Alles muss kommentiert werden!“.
Dann hieß es (eine Show namens „Linux Nerds vs. Geeks“ glaube ich) „Wenn man schönen/guten Code schreibt, braucht man keine Kommentare“ (sagte der Linux Grafik-Programmierer-Guru!).
Irgendwann sagte ein ehemaliger Kollege „Kommentare verwirren nur“ und dass „Nur Amateure und Doofis kommentieren“ …
Mein derzeitiger Standpunkt ist:
Extrem ist und bleibt extrem. Daher entscheide ich mich für die goldene Mitte.
Bevor ich Kommentiere stelle ich mir folgende Fragen:
Muss ich Kommentieren?
Reicht der Name nicht?
Ist der Name gut gewählt?
Sollte ich nicht lieber den Namen ändern?
Wie groß ist der Informationsgehalt des Kommentars?
Bietet der Kommentar eine zusätzliche oder ergänzende Information, die sonst nicht (oder sehr schwer) zu lesen/sehen/wissen (Code) wäre?
Erleichtert/Verkürzt der Kommentar die Suche/Recherche oder das Verständnis des Algorithmus?
Lässt der Kommentar Raum für falsche Interpretationen zu?
Hilft der Kommentar Fehler zu minimieren, oder verursacht es mehr Fehler durch Missverständnis?
Nehmen wir den (C#) Code von Unten als Beispiel und stellen wir uns gemeinsam pro Kommentar die obigen neun Fragen unter Punkt zwei:
public class Person
{
/// <summary>
/// Gets/Sets the ID of Person.
/// </summary>
public int ID { get; set; }
/// <summary>
/// Gets/Sets the first/given name of Person.
/// </summary>
public string FirstName { get; set; }
/// <summary>
/// Gets/Sets the last/second name of Person.
/// </summary>
public string LastName { get; set; }
/// <summary>
/// Gets/Sets the day of birth of Person.
/// </summary>
public DateTime BirthDay { get; set; }
/// <summary>
/// Returns the whole/full name beginning with FirstName then LastName in uppercase.
/// </summary>
/// <returns></returns>
public string GetName()
{
// todo: check!
return $"{FirstName} {LastName.ToUpper()}"; // NG! PGH 2021-07-05 V0.8.15
}
}
Die Property-Namen sagen eindeutig, unmissverständlich und klar aus, was sie beinhalten, und deren Kommentare haben/bringen keine zusätzliche/ergänzende Informationen… Also ⇒ Weg damit!
Der Kommentar von der Methode „GetName“ möchte, und MUSS, etwas erklären, was der Name leider nicht tut. Zusätzlich verwirrt dieser Kommentar. Innerhalb der Methode „GetName“ steht ein „todo“ Kommentar, was kein Mensch entschlüsseln kann: „check!“ Check-What? Was soll gecheckt/überprüft werden FirstName, LastName oder Return-Value (string)? Am Ende der Return-Zeile steht wieder kryptische Buchstaben-Suppe:
„NG!“ steht für…??? No Guns? No Game? Next Generation? Not Good? No Grade? Network Grid?
Danach steht „PGH„, meine Initialien plus Datum und anscheinend eine Version:
Gibt es für sowas Versionsverwaltungs-Systemen (CVS, SVN und GIT). Dort kann man all das lesen, von Anbeginn der Zeit (Projekt-Geburt) bis zum letzten Commit: Wer (Name, E-Mail-Adresse) hat, wann(Datum + Uhrzeit mit Millisekunden) was (Verzeichnis, Datei, Zeile) in welche Version geändert (gelöscht, hinzugefügt, umbenannt, ergänzt, entfernt,…) hat.
Was sollen die Kolleginnen damit anfangen? Mehrwert? Informationsgehalt?
Das Ganze könnte man auch so schreiben:
public class Person
{
public int ID { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
/// <summary>
/// Returns full name, like: "John DOE", "Alice BOYLE".
/// </summary>
/// <returns></returns>
public string GetFullName()
{
return $"{FirstName} {LastName?.ToUpper()}";
}
}
Ich habe diese Beispiele nicht aus der Luft gegriffen. Ähnliche, und teilweise noch schlimmere Fälle aus der Praxis (was mir unter die Augen gekommen sind) werde ich noch hinzufügen. Entweder hier oder im neuen Beitrag.
Der Kunde zahlt fürs Code-Schreiben und nicht fürs Code-Lesen!
In einer Firma, wo alle Software-Entwickler und IT’ler Deutschsprachige waren, hat der Inhaber & CEO uns befohlen alle Kommentare (nur Kommentare) auf Deutsch zu schreiben. Ein Jahr später, nachdem das Projekt im Verzug war und die Entwicklung des Software-Systems nicht schnell genug vorangegangen war, wurden drei neue Software-Entwickler aus Spanien eingestellt. Die neuen Kollegen waren alle sehr gute Software-Entwickler und beherrschten souverän ihr Fach, jedoch verstanden kein Wort Deutsch. Danach wurden noch mindestens fünf weitere Software-Entwickler, ebenfalls aus Spanien, eingestellt… Nun hatten wir alle Hände voll zu tun. Wir drei Deutschsprachigen müssten alle Kommentare nun auf Englisch übersetzen und ersetzen, anstatt unsere Aufgaben nachzugehen.
In eine andere Firma, hatte ich das „Vergnügen“ Code auf Denglisch zu lesen. Manche Namen waren Deutsch, manche waren Englisch, und der Rest eine beliebige Mischung aus Deutsch und Englisch. Dass alle Programm-Elemente (Interfaces, Klassen, Delegates, Events, Methoden, Properties etc.) in Microsoft .NET Frameworks auf US-Englisch waren, ist natürlich trivial…
Das Lesen der Code war extrem schwierig und eine Herausforderung an/für sich. Beispiel für Variable-Namen: messValue, measWert, measValue, messWert (diese Namen standen für: measured value, bzw. gemessener Wert). Auch wenn man alle Namen auf Deutsch schreibt, die Hälfte von Code ist und bleibt auf Englisch, da die Schlüsselwörter und alles Andere in MS .NET Frameworks in US-Englisch ist, wie: string.IsNullOrEmpty(…), PropertyChanged, File.Exist(…), using(var x = new MemoryStream(…)), usw. usf.
Deswegen behaupte ich: Es kann kein Code auf „Deutsch“ geschrieben werden, wenn man das versucht, dann entsteht immer ein Code auf „Denglisch“. Man stelle sich nur vor, jemand würde Denglisch schreiben oder reden: „I war very froh to sehen you nochmal“.
Ich verwende gerne US englische Namen (Color statt Colour, Synchronize statt Synchronise, usw.). Somit bleibt alles einheitlich, unmissverständlich, eindeutig, klar und der Lese-Fluss bleibt sehr flüssig.
Denglisch kostet mehr Zeit, mehr Zeit zum Lesen und mehr Zeit zum Verstehen. Je öfter der Code von je mehr Kollegen (wieder)gelesen wird, desto mehr Zeit wird verschwendet! Zeit ist Geld. Somit verursacht Code auf Denglisch unnötige zusätzliche Kosten.
Der Kunde zahlt fürs Code-Schreiben und nicht fürs Code-Lesen!
Event-Handling-Methoden beginnen mit „On“ plus Event-Name, und können -wenn passend- mit „ed“ enden, also: „On<EventName>ed„, wie: OnCommandInvoked, OnValueChanged, OnSafeModeActivationChanged, OnStreamOpening, OnStreamOpened, OnStreamClosing, OnStreamClosed, OnUserLoggedIn, OnUserLoggedOut, OnMachineReplaced, OnErrorOccured,…
Funktionen/Methode, die etwas Berechnen und eine Zahl zurückgeben beginnen mit „Calc“ oder „Calculate“ (und NIEMALS mit „Get“!), wie: CalculateCircleSurface(…), CalculateStandardDeviation(…) oder kurz: CalcStdDeviation(…)
Methoden die asynchron laufen enden mit „Async“, wie: CalcStdDeviationAsync(IEnumerable pTooManyNumbers),…
Properties die Exception werfen können, werden NICHT als Properties, sondern mit „Get…()“ und „Set…()“ implementiert (so wie es die C# Sprach-Designer Anders Hejlsberg, Bill Wagner & Co vorgesehen haben), denn ein Property sollte niemals Exceptions werfen, schon gar nicht der Getter. Ausgenommen sind die Indexer (wegen IndexOutOfRangeException).
„Get…“ Methoden welche Exceptions abfangen und behandeln enden mit:
„OrNull“ wenn bei Exception NULL zurückgeliefert wird
„OrDefault“ wenn bei Exception Default-Wert (z. B. default(int)) zurückgeliefert wird
Member-Variablen beginnen mit „m“ oder „m_„, wie: mFirstName oder m_FirstName
Parameter beginnen mit „p“ wie: CalcRectSurface(int pWidth, int pHeight), SetTopLeft(int pX, int pY),…
Konstanten werden GROSS_GESCHRIEBEN: DEFAULT_VALUE, MAX_VALUE,…
Der Beispiel-Code unten erfüllt die oben erwähnten Regeln. Versuche herauszufinden: Welcher Name ist ein Property, welcher ein Parameter, welcher eine Member-Variable und welcher eine Konstante:
Konstanten, Parameter, Properties etc. sind eindeutig zu erkennen
Der Kunde zahlt fürs Code-Schreiben und nicht fürs Code-Lesen!
Die Zeiten wo alles in Grün auf schwarzem Hintergrund stand (Borland Turbo Pascal/CPP Editor udg.) sind lange vorbei. IDEs wie Visual Studio & Co bieten von Haus aus Syntax Highlighting. Die Einfärbung der Schlüsselwörter, Kommentare, Typen etc. machen das Lesen von Code leichter, flüssiger und angenehmer. Für mich jedoch reichte die Einfärbung für C# in Visual Studio nicht. Ich möchte schnell auf einem Blick, ohne zu lesen erkennen, ob bei ein Programm-Element (in C#) es sich um ein Interface, Klasse, Enum, Delegate, Event oder „Magic Number“ handelt. Dazu habe ich für Interfaces, Delegates, Enums und Zahlen eigene Farben zugewiesen (siehe Bild 1!)
Kommentare sehe ich deutlicher (Dunkelgrün statt Standard Leichtgrau)
Enums sind eindeutig sofort zu erkennen (Orange)
Delegates sind ebenfalls eindeutig zu erkennen (Violett)
Interfaces haben eine andere Farbe als (abstrakte) Klassen oder Structs
Events sind Braun
„Magic Numbers“ haben bei mir keine Chance, da sie sofort erkannt werden 😉
Unterscheidung zwischen Enums und Konstanten sind ebenfalls leichter
Bild 1
So gelangt man zu Farben- und Font-Style von Programm-Elementen in Visual Studio (Bild 2):
Seit Visual Studio 2012 wird „Dark Theme“ (Tools → Options → Environment → General → Color Theme) als Standard verwendet. Das hat den Vorteil, dass die Augen mit weniger Licht belastet werden. Jedoch ist es so, dass „Dark Theme“ sich eher für Grafik, 3D und Animations-Editoren eignet, um die Tool-Leisten weg- und das Bild/Modell (Bild, 3D Objekt udg.) in die Mitte zu rücken (dadurch wird automatisch die Fokussierung auf das Bild/Modell geleitet). Für das Lesen und Schreiben von Text (hier Code) ist es eher ungeeignet (laut Augen-Mediziner). Die Augen müssen sich mühsam auf die hellen Buchstaben fokussieren. Vor allem, wenn durch große Fenster, was heutzutage modern ist, das Sonnenlicht auf dem Bildschirm fällt, oder über helle Flächen auf dem Bildschirm reflektiert wird.
Deshalb probiert es selbst aus! Nachdem ich eine Zeit lang extreme Augen- und Kopfschmerzen hatte, und deshalb zum Augenarzt gehen müsste, bin ich auf dem „Light“ Theme umgestiegen. Das reflektierte Sonnenlicht ist seitdem kein Thema (für mich) mehr. Für detaillierte Informationen, siehe hier und hier! Anmerkung: bei OLED und AMOLED Bildschirm, wird oft Dark Theme zwecks Energiesparen eingesetzt.
Der Kunde zahlt fürs Code-Schreiben und nicht fürs Code-Lesen!
Wenn wir ein Buch, eine Zeitung, ein Magazin oder nur ein A4 Blatt lesen, dann halten wir es so, dass die obere Kante etwas weiter hinten ist, und die untere Kante näher zu uns ist. Beim Lesen nach Unten bewegen sich die Augen weiter nach Innen (zu Nase), und beim Lesen nach Oben bewegen sich die Augen auseinander. Wir halten ein Buch niemals parallel vor unserem Kopf, wir neigen den Kopf etwas nach Unten. Kurze Zeilen unter einander machen den Lese-Fluss leichter. Lange Zeilen stören den Lese-Fluss, da die Augen sich auch horizontal bewegen müssen. Bei sehr lange Zeilen muss sich sogar noch der Kopf sich horizontal drehen. Je mehr Augenmuskeln beansprucht werden, desto früher wird man Müde (Kopf-Schmerzen). Man kann sich schlecht konzentrieren/fokussieren. Deshalb ist das Lesen während einer Zug- oder Busfahrt (für längere Zeit) nicht ratsam.
Das gilt auch für Code lesen. Deshalb sollte darauf geachtet werden das beim Code schreiben, die Zeilen möglichst kurz und untereinander stehen.
// Hindert den Lesefluss
if ((a > B && C < D) && !(x == y || y != z)) dataCommunicator.SomeMethod(a, b, c, true);
// Noch mehr Code...
// Macht den Lesefluss leichter
if ((a > B && C < D) && !(x == y || y != z))
dataCommunicator.SomeMethod(a, b, c, true);
// Noch mehr Code...
Nomen est omen Namen spielen beim Schreiben von Code eine essenzielle Rolle. Gut gewählte Namen können viele Grübeleien, Verwirrungen und Missverständnisse sowie Fehler vermeiden, und machen den Code leichter lesbar. Gute Namen sind:
Selbsterklärend
Klar
Eindeutig
Unmissverständlich
Einprägsam
Sagen genau was das Ding tut oder enthält, nicht mehr und nicht weniger
Müssen nicht kommentiert werden
Zum Beispiel hier (C# Code): Der Klassen-Name sagt aus „Ich enthalte Geometrie-Methoden“, die erste Methode sagt „Ich berechne eine Kreisfläche, wenn du mir die Radius-Länge gibst“, usw. Man braucht nicht (mit F12 ins Visual Studio) sich den Code innerhalb einer Methode zu lesen, um zu wissen, was es tut.
public class GeometryCalculator
{
public double CalculateCircleSurface(double radiusLength)
{
return radiusLength * radiusLength * Math.PI;
}
public double CalculateSquareSurface(double sideLength)
{
return sideLength * sideLength;
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Ugly.Code
{
public class GeoCalc
{
public double GetCS(double value)
{
double val1;
double calc;
val1 = value;
calc = Math.Pow(val1, 2) * Math.PI;
return calc;
}
public double GetSS(double value)
{
double val1;
double calc;
val1 = value;
calc = Math.Pow(val1, 2);
return calc;
}
// Some other methods...
}
}
Warum ist der Code oben „Ugly“?
Ungenutzte „using“ Zeilen
Der Klassen-Name sagt nicht, was die Klasse enthält/anbietet/tut
Die Methoden-Namen sagen nicht, was sie tun oder berechnen/zurückliefern
Die Parameter-Namen sagen nicht, was sie enthalten
Die lokalen Variable-Namen sagen nicht, was sie enthalten
Lokale Variablen kaschieren die Parameter und dessen Werte, machen den Algorithmus schwer verständlich
Unnötige Leerzeilen verlängern unnötig die Methode. Man muss mehr scrollen und mit den Augen rauf & runterschauen.
Die Klasse „GeoCalc“ von Oben, könnte man auch so schreiben:
using System;
namespace Clean.Code
{
public class GeometryCalculator
{
public double CalculateCircleSurface(double radiusLength)
{
return radiusLength * radiusLength * Math.PI;
}
public double CalculateSquareSurface(double sideLength)
{
return sideLength * sideLength;
}
// Some other methods...
}
}
Zustimmung verwalten
Um dir ein optimales Erlebnis zu bieten, verwenden wir Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wenn du diesen Technologien zustimmst, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn du deine Zustimmung nicht erteilst oder zurückziehst, können bestimmte Merkmale und Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.